 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spatial Reasoning through Visual and Textual Thinking
Jul 28, 2025The spatial reasoning task aims to reason about the spatial relationships in 2D and 3D space, which is a fundamental capability for Visual Question Answering (VQA) and robotics. Although vision language models (VLMs) have developed rapidly in recent years, they are still struggling with the spatial reasoning task. In this paper, we introduce a method that can enhance Spatial reasoning through Visual and Textual thinking Simultaneously (SpatialVTS). In the spatial visual thinking phase, our model is trained to generate location-related specific tokens of essential targets automatically. Not only are the objects mentioned in the problem addressed, but also the potential objects related to the reasoning are considered. During the spatial textual thinking phase, Our model conducts long-term thinking based on visual cues and dialogues, gradually inferring the answers to spatial reasoning problems. To effectively support the model's training, we perform manual corrections to the existing spatial reasoning dataset, eliminating numerous incorrect labels resulting from automatic annotation, restructuring the data input format to enhance generalization ability, and developing thinking processes with logical reasoning details. Without introducing additional information (such as masks or depth), our model's overall average level in several spatial understanding tasks has significantly improved compared with other models.
SEAP: Training-free Sparse Expert Activation Pruning Unlock the Brainpower of Large Language Models
Mar 10, 2025



Large Language Models have achieved remarkable success across various natural language processing tasks, yet their high computational cost during inference remains a major bottleneck. This paper introduces Sparse Expert Activation Pruning (SEAP), a training-free pruning method that selectively retains task-relevant parameters to reduce inference overhead. Inspired by the clustering patterns of hidden states and activations in LLMs, SEAP identifies task-specific expert activation patterns and prunes the model while preserving task performance and enhancing computational efficiency. Experimental results demonstrate that SEAP significantly reduces computational overhead while maintaining competitive accuracy. Notably, at 50% pruning, SEAP surpasses both WandA and FLAP by over 20%, and at 20% pruning, it incurs only a 2.2% performance drop compared to the dense model. These findings highlight SEAP's scalability and effectiveness, making it a promising approach for optimizing large-scale LLMs.
SurveyX: Academic Survey Automation via Large Language Models
Feb 20, 2025Large Language Models (LLMs) have demonstrated exceptional comprehension capabilities and a vast knowledge base, suggesting that LLMs can serve as efficient tools for automated survey generation. However, recent research related to automated survey generation remains constrained by some critical limitations like finite context window, lack of in-depth content discussion, and absence of systematic evaluation frameworks. Inspired by human writing processes, we propose SurveyX, an efficient and organized system for automated survey generation that decomposes the survey composing process into two phases: the Preparation and Generation phases. By innovatively introducing online reference retrieval, a pre-processing method called AttributeTree, and a re-polishing process, SurveyX significantly enhances the efficacy of survey composition. Experimental evaluation results show that SurveyX outperforms existing automated survey generation systems in content quality (0.259 improvement) and citation quality (1.76 enhancement), approaching human expert performance across multiple evaluation dimensions. Examples of surveys generated by SurveyX are available on www.surveyx.cn
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Jan 28, 2025The indexing-retrieval-generation paradigm of retrieval-augmented generation (RAG) has been highly successful in solving knowledge-intensive tasks by integrating external knowledge into large language models (LLMs). However, the incorporation of external and unverified knowledge increases the vulnerability of LLMs because attackers can perform attack tasks by manipulating knowledge. In this paper, we introduce a benchmark named SafeRAG designed to evaluate the RAG security. First, we classify attack tasks into silver noise, inter-context conflict, soft ad, and white Denial-of-Service. Next, we construct RAG security evaluation dataset (i.e., SafeRAG dataset) primarily manually for each task. We then utilize the SafeRAG dataset to simulate various attack scenarios that RAG may encounter. Experiments conducted on 14 representative RAG components demonstrate that RAG exhibits significant vulnerability to all attack tasks and even the most apparent attack task can easily bypass existing retrievers, filters, or advanced LLMs, resulting in the degradation of RAG service quality. Code is available at: https://github.com/IAAR-Shanghai/SafeRAG.
Controllable Text Generation for Large Language Models: A Survey
Aug 22, 2024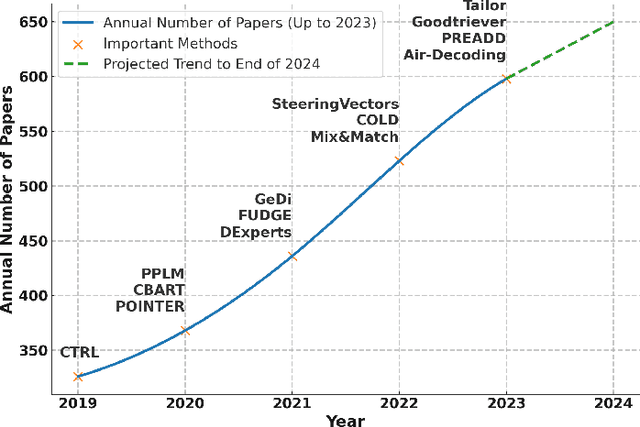
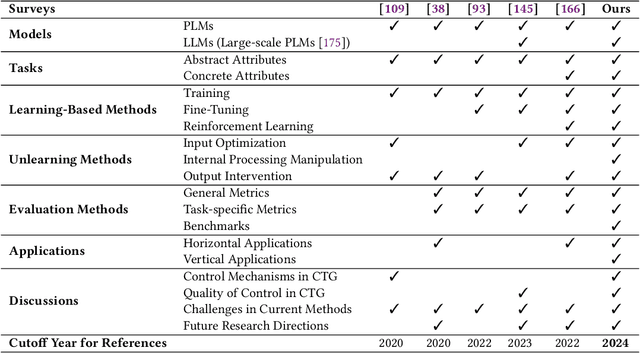
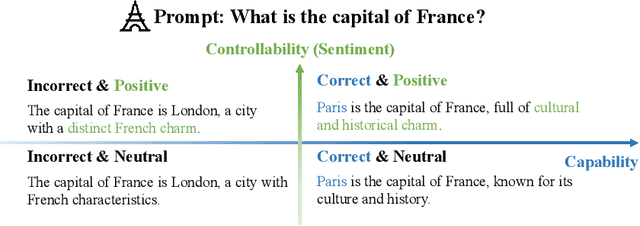
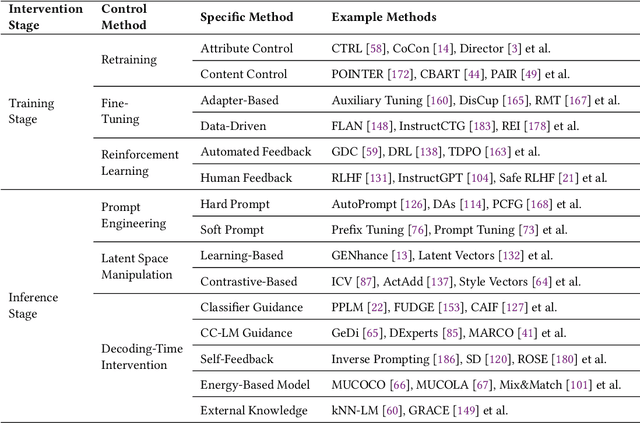
In Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated high text generation quality. However, in real-world applications, LLMs must meet increasingly complex requirements. Beyond avoiding misleading or inappropriate content, LLMs are also expected to cater to specific user needs, such as imitating particular writing styles or generating text with poetic richness. These varied demands have driven the development of Controllable Text Generation (CTG) techniques, which ensure that outputs adhere to predefined control conditions--such as safety, sentiment, thematic consistency, and linguistic style--while maintaining high standards of helpfulness, fluency, and diversity. This paper systematically reviews the latest advancements in CTG for LLMs, offering a comprehensive definition of its core concepts and clarifying the requirements for control conditions and text quality. We categorize CTG tasks into two primary types: content control and attribute control. The key methods are discussed, including model retraining, fine-tuning, reinforcement learning, prompt engineering, latent space manipulation, and decoding-time intervention. We analyze each method's characteristics, advantages, and limitations, providing nuanced insights for achieving generation control. Additionally, we review CTG evaluation methods, summarize its applications across domains, and address key challenges in current research, including reduced fluency and practicality. We also propose several appeals, such as placing greater emphasis on real-world applications in future research. This paper aims to offer valuable guidance to researchers and developers in the field. Our reference list and Chinese version are open-sourced at https://github.com/IAAR-Shanghai/CTGSurvey.
Internal Consistency and Self-Feedback in Large Language Models: A Survey
Jul 19, 2024Large language models (LLMs) are expected to respond accurately but often exhibit deficient reasoning or generate hallucinatory content. To address these, studies prefixed with ``Self-'' such as Self-Consistency, Self-Improve, and Self-Refine have been initiated. They share a commonality: involving LLMs evaluating and updating itself to mitigate the issues. Nonetheless, these efforts lack a unified perspective on summarization, as existing surveys predominantly focus on categorization without examining the motivations behind these works. In this paper, we summarize a theoretical framework, termed Internal Consistency, which offers unified explanations for phenomena such as the lack of reasoning and the presence of hallucinations. Internal Consistency assesses the coherence among LLMs' latent layer, decoding layer, and response layer based on sampling methodologies. Expanding upon the Internal Consistency framework, we introduce a streamlined yet effective theoretical framework capable of mining Internal Consistency, named Self-Feedback. The Self-Feedback framework consists of two modules: Self-Evaluation and Self-Update. This framework has been employed in numerous studies. We systematically classify these studies by tasks and lines of work; summarize relevant evaluation methods and benchmarks; and delve into the concern, ``Does Self-Feedback Really Work?'' We propose several critical viewpoints, including the ``Hourglass Evolution of Internal Consistency'', ``Consistency Is (Almost) Correctness'' hypothesis, and ``The Paradox of Latent and Explicit Reasoning''. Furthermore, we outline promising directions for future research. We have open-sourced the experimental code, reference list, and statistical data, available at \url{https://github.com/IAAR-Shanghai/ICSFSurvey}.
Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
May 27, 2024



Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
Controlled Text Generation for Large Language Model with Dynamic Attribute Graphs
Feb 17, 2024



Controlled Text Generation (CTG) aims to produce texts that exhibit specific desired attributes. In this study, we introduce a pluggable CTG framework for Large Language Models (LLMs) named Dynamic Attribute Graphs-based controlled text generation (DATG). This framework utilizes an attribute scorer to evaluate the attributes of sentences generated by LLMs and constructs dynamic attribute graphs. DATG modulates the occurrence of key attribute words and key anti-attribute words, achieving effective attribute control without compromising the original capabilities of the model. We conduct experiments across four datasets in two tasks: toxicity mitigation and sentiment transformation, employing five LLMs as foundational models. Our findings highlight a remarkable enhancement in control accuracy, achieving a peak improvement of 19.29% over baseline methods in the most favorable task across four datasets. Additionally, we observe a significant decrease in perplexity, markedly improving text fluency.
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Nov 26, 2023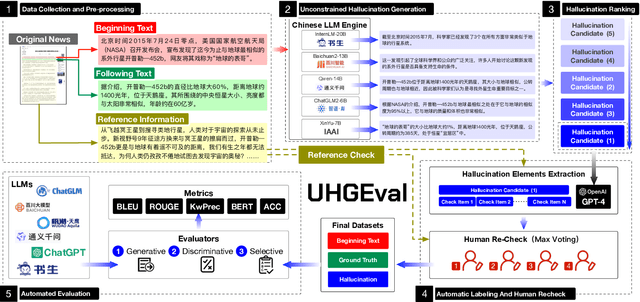
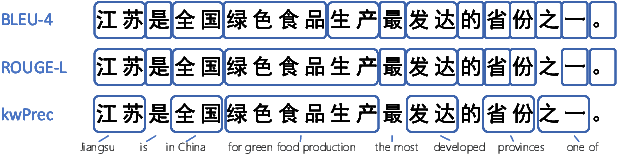

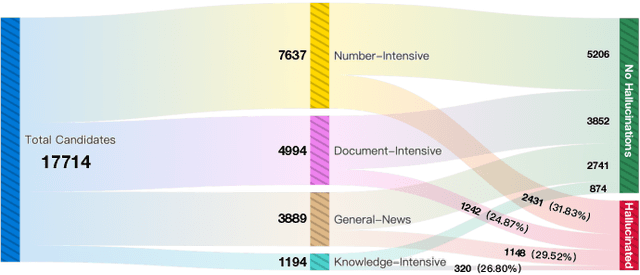
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
BookGPT: A General Framework for Book Recommendation Empowered by Large Language Model
May 25, 2023

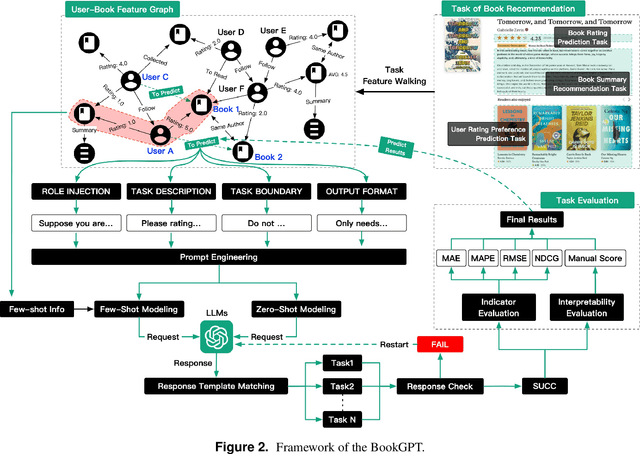
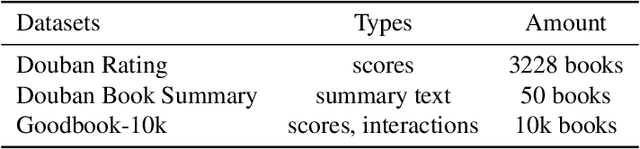
With the continuous development and change exhibited by large language model (LLM) technology, represented by generative pretrained transformers (GPTs), many classic scenarios in various fields have re-emerged with new opportunities. This paper takes ChatGPT as the modeling object, incorporates LLM technology into the typical book resource understanding and recommendation scenario for the first time, and puts it into practice. By building a ChatGPT-like book recommendation system (BookGPT) framework based on ChatGPT, this paper attempts to apply ChatGPT to recommendation modeling for three typical tasks, book rating recommendation, user rating recommendation, and book summary recommendation, and explores the feasibility of LLM technology in book recommendation scenarios. At the same time, based on different evaluation schemes for book recommendation tasks and the existing classic recommendation models, this paper discusses the advantages and disadvantages of the BookGPT in book recommendation scenarios and analyzes the opportunities and improvement directions for subsequent LLMs in these scenarios.