 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuessArena: Guess Who I Am? A Self-Adaptive Framework for Evaluating LLMs in Domain-Specific Knowledge and Reasoning
May 28, 2025The evaluation of large language models (LLMs) has traditionally relied on static benchmarks, a paradigm that poses two major limitations: (1) predefined test sets lack adaptability to diverse application domains, and (2) standardized evaluation protocols often fail to capture fine-grained assessments of domain-specific knowledge and contextual reasoning abilities. To overcome these challenges, we propose GuessArena, an adaptive evaluation framework grounded in adversarial game-based interactions. Inspired by the interactive structure of the Guess Who I Am? game, our framework seamlessly integrates dynamic domain knowledge modeling with progressive reasoning assessment to improve evaluation fidelity. Empirical studies across five vertical domains-finance, healthcare, manufacturing, information technology, and education-demonstrate that GuessArena effectively distinguishes LLMs in terms of domain knowledge coverage and reasoning chain completeness. Compared to conventional benchmarks, our method provides substantial advantages in interpretability, scalability, and scenario adaptability.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025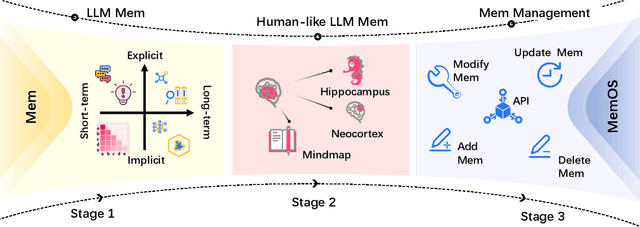
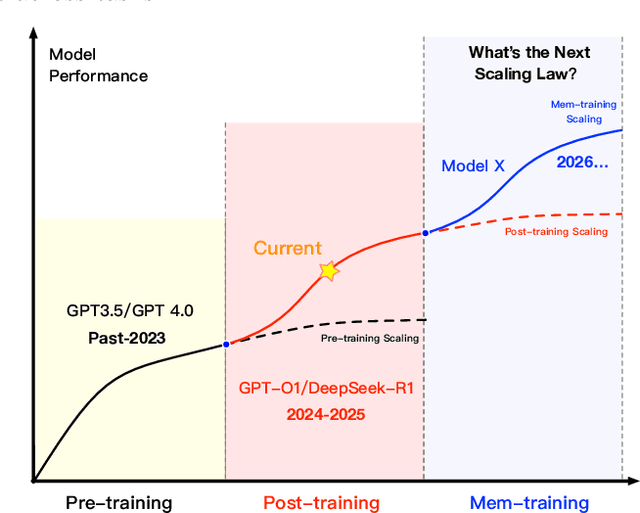
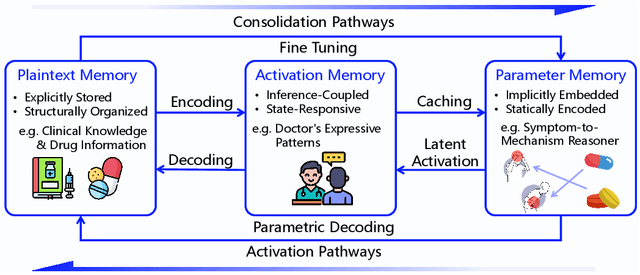
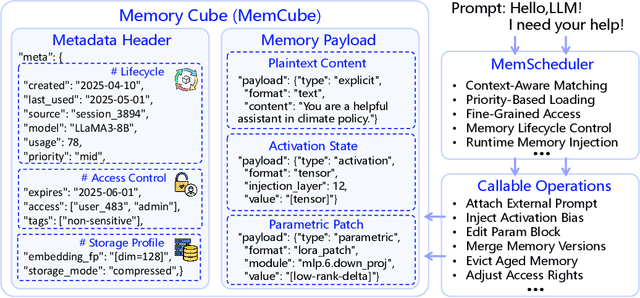
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
xVerify: Efficient Answer Verifier for Reasoning Model Evaluations
Apr 14, 2025With the release of the o1 model by OpenAI, reasoning models adopting slow thinking strategies have gradually emerged. As the responses generated by such models often include complex reasoning, intermediate steps, and self-reflection, existing evaluation methods are often inadequate. They struggle to determine whether the LLM output is truly equivalent to the reference answer, and also have difficulty identifying and extracting the final answer from long, complex responses. To address this issue, we propose xVerify, an efficient answer verifier for reasoning model evaluations. xVerify demonstrates strong capability in equivalence judgment, enabling it to effectively determine whether the answers produced by reasoning models are equivalent to reference answers across various types of objective questions. To train and evaluate xVerify, we construct the VAR dataset by collecting question-answer pairs generated by multiple LLMs across various datasets, leveraging multiple reasoning models and challenging evaluation sets designed specifically for reasoning model assessment. A multi-round annotation process is employed to ensure label accuracy. Based on the VAR dataset, we train multiple xVerify models of different scales. In evaluation experiments conducted on both the test set and generalization set, all xVerify models achieve overall F1 scores and accuracy exceeding 95\%. Notably, the smallest variant, xVerify-0.5B-I, outperforms all evaluation methods except GPT-4o, while xVerify-3B-Ib surpasses GPT-4o in overall performance. These results validate the effectiveness and generalizability of xVerify.
TurtleBench: Evaluating Top Language Models via Real-World Yes/No Puzzles
Oct 07, 2024

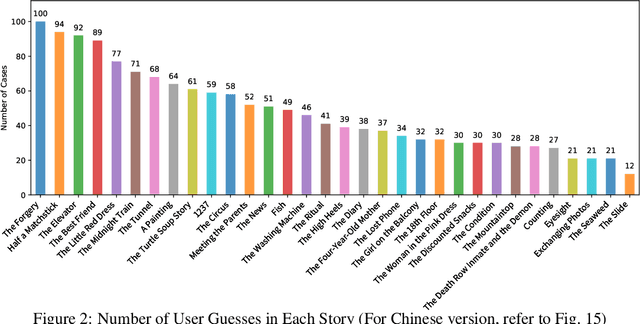

As the application of Large Language Models (LLMs) expands, the demand for reliable evaluations increases. Existing LLM evaluation benchmarks primarily rely on static datasets, making it challenging to assess model performance in dynamic interactions with users. Moreover, these benchmarks often depend on specific background knowledge, complicating the measurement of a model's logical reasoning capabilities. Other dynamic evaluation methods based on strong models or manual efforts may introduce biases and incur high costs and time demands, hindering large-scale application. To address these issues, we propose TurtleBench. TurtleBench collects real user guesses from our online Turtle Soup Puzzle platform that we developed. This approach allows for the relatively dynamic generation of evaluation datasets, mitigating the risk of model cheating while aligning assessments more closely with genuine user needs for reasoning capabilities, thus enhancing the reliability of evaluations. TurtleBench includes 1,532 user guesses along with the correctness of guesses after annotation. Using this dataset, we thoroughly evaluated nine of the most advanced LLMs available today. Notably, the OpenAI o1 series models did not achieve leading results in these evaluations. We propose several hypotheses for further research, such as "the latent reasoning of o1 utilizes trivial Chain-of-Thought (CoT) techniques" and "increasing CoT length not only provides reasoning benefits but also incurs noise costs."
Internal Consistency and Self-Feedback in Large Language Models: A Survey
Jul 19, 2024Large language models (LLMs) are expected to respond accurately but often exhibit deficient reasoning or generate hallucinatory content. To address these, studies prefixed with ``Self-'' such as Self-Consistency, Self-Improve, and Self-Refine have been initiated. They share a commonality: involving LLMs evaluating and updating itself to mitigate the issues. Nonetheless, these efforts lack a unified perspective on summarization, as existing surveys predominantly focus on categorization without examining the motivations behind these works. In this paper, we summarize a theoretical framework, termed Internal Consistency, which offers unified explanations for phenomena such as the lack of reasoning and the presence of hallucinations. Internal Consistency assesses the coherence among LLMs' latent layer, decoding layer, and response layer based on sampling methodologies. Expanding upon the Internal Consistency framework, we introduce a streamlined yet effective theoretical framework capable of mining Internal Consistency, named Self-Feedback. The Self-Feedback framework consists of two modules: Self-Evaluation and Self-Update. This framework has been employed in numerous studies. We systematically classify these studies by tasks and lines of work; summarize relevant evaluation methods and benchmarks; and delve into the concern, ``Does Self-Feedback Really Work?'' We propose several critical viewpoints, including the ``Hourglass Evolution of Internal Consistency'', ``Consistency Is (Almost) Correctness'' hypothesis, and ``The Paradox of Latent and Explicit Reasoning''. Furthermore, we outline promising directions for future research. We have open-sourced the experimental code, reference list, and statistical data, available at \url{https://github.com/IAAR-Shanghai/ICSFSurvey}.
xFinder: Robust and Pinpoint Answer Extraction for Large Language Models
May 23, 2024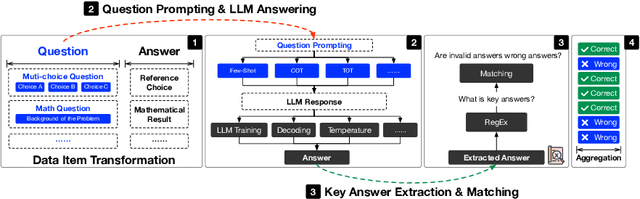
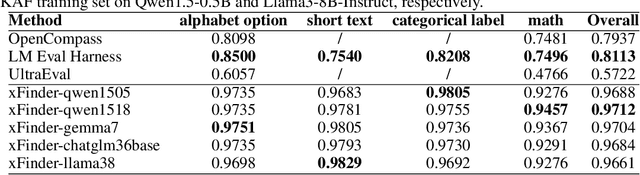

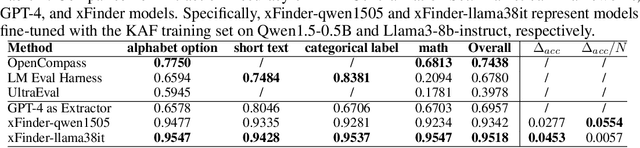
The continuous advancement of large language models (LLMs) has brought increasing attention to the critical issue of developing fair and reliable methods for evaluating their performance. Particularly, the emergence of subjective or non-subjective cheating phenomena, such as test set leakage and prompt format overfitting, poses significant challenges to the reliable evaluation of LLMs. Since evaluation frameworks often utilize Regular Expression (RegEx) for answer extraction, some models may adjust their responses to comply with specific formats that are easily extractable by RegEx. Nevertheless, the key answer extraction module based on RegEx frequently suffers from extraction errors. This paper conducts a comprehensive analysis of the entire LLM evaluation chain, demonstrating that optimizing the key answer extraction module can improve extraction accuracy, reduce LLMs' reliance on specific answer formats, and enhance the reliability of LLM evaluation. To address these issues, we propose xFinder, a model specifically designed for key answer extraction. As part of this process, we create a specialized dataset, the Key Answer Finder (KAF) dataset, to ensure effective model training and evaluation. Through generalization testing and evaluation in real-world scenarios, the results demonstrate that the smallest xFinder model with only 500 million parameters achieves an average answer extraction accuracy of 93.42%. In contrast, RegEx accuracy in the best evaluation framework is 74.38%. xFinder exhibits stronger robustness and higher accuracy compared to existing evaluation frameworks.
Grimoire is All You Need for Enhancing Large Language Models
Jan 10, 2024In-context Learning (ICL) is one of the key methods for enhancing the performance of large language models on specific tasks by providing a set of few-shot examples. However, the ICL capability of different types of models shows significant variation due to factors such as model architecture, volume of learning data, and the size of parameters. Generally, the larger the model's parameter size and the more extensive the learning data, the stronger its ICL capability. In this paper, we propose a method SLEICL that involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application. This ensures the stability and effectiveness of ICL. Compared to directly enabling weak language models to learn from prompt examples, SLEICL reduces the difficulty of ICL for these models. Our experiments, conducted on up to eight datasets with five language models, demonstrate that weak language models achieve consistent improvement over their own zero-shot or few-shot capabilities using the SLEICL method. Some weak language models even surpass the performance of GPT4-1106-preview (zero-shot) with the aid of SLEICL.