 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025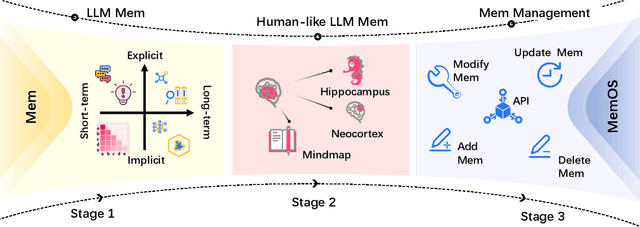
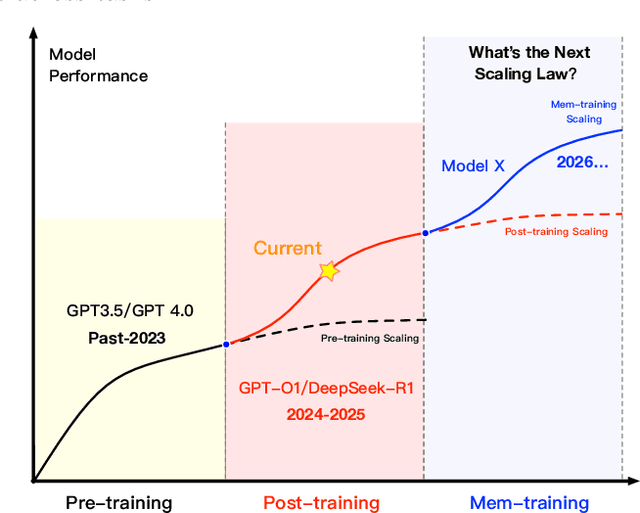
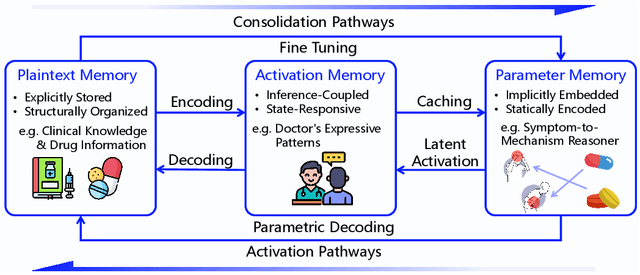
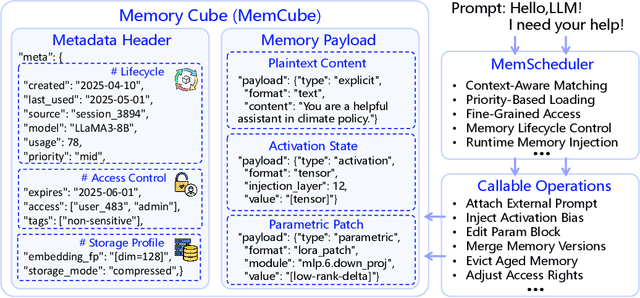
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
SEAP: Training-free Sparse Expert Activation Pruning Unlock the Brainpower of Large Language Models
Mar 10, 2025



Large Language Models have achieved remarkable success across various natural language processing tasks, yet their high computational cost during inference remains a major bottleneck. This paper introduces Sparse Expert Activation Pruning (SEAP), a training-free pruning method that selectively retains task-relevant parameters to reduce inference overhead. Inspired by the clustering patterns of hidden states and activations in LLMs, SEAP identifies task-specific expert activation patterns and prunes the model while preserving task performance and enhancing computational efficiency. Experimental results demonstrate that SEAP significantly reduces computational overhead while maintaining competitive accuracy. Notably, at 50% pruning, SEAP surpasses both WandA and FLAP by over 20%, and at 20% pruning, it incurs only a 2.2% performance drop compared to the dense model. These findings highlight SEAP's scalability and effectiveness, making it a promising approach for optimizing large-scale LLMs.
SurveyX: Academic Survey Automation via Large Language Models
Feb 20, 2025Large Language Models (LLMs) have demonstrated exceptional comprehension capabilities and a vast knowledge base, suggesting that LLMs can serve as efficient tools for automated survey generation. However, recent research related to automated survey generation remains constrained by some critical limitations like finite context window, lack of in-depth content discussion, and absence of systematic evaluation frameworks. Inspired by human writing processes, we propose SurveyX, an efficient and organized system for automated survey generation that decomposes the survey composing process into two phases: the Preparation and Generation phases. By innovatively introducing online reference retrieval, a pre-processing method called AttributeTree, and a re-polishing process, SurveyX significantly enhances the efficacy of survey composition. Experimental evaluation results show that SurveyX outperforms existing automated survey generation systems in content quality (0.259 improvement) and citation quality (1.76 enhancement), approaching human expert performance across multiple evaluation dimensions. Examples of surveys generated by SurveyX are available on www.surveyx.cn
SafeRAG: Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Jan 28, 2025The indexing-retrieval-generation paradigm of retrieval-augmented generation (RAG) has been highly successful in solving knowledge-intensive tasks by integrating external knowledge into large language models (LLMs). However, the incorporation of external and unverified knowledge increases the vulnerability of LLMs because attackers can perform attack tasks by manipulating knowledge. In this paper, we introduce a benchmark named SafeRAG designed to evaluate the RAG security. First, we classify attack tasks into silver noise, inter-context conflict, soft ad, and white Denial-of-Service. Next, we construct RAG security evaluation dataset (i.e., SafeRAG dataset) primarily manually for each task. We then utilize the SafeRAG dataset to simulate various attack scenarios that RAG may encounter. Experiments conducted on 14 representative RAG components demonstrate that RAG exhibits significant vulnerability to all attack tasks and even the most apparent attack task can easily bypass existing retrievers, filters, or advanced LLMs, resulting in the degradation of RAG service quality. Code is available at: https://github.com/IAAR-Shanghai/SafeRAG.
TurtleBench: Evaluating Top Language Models via Real-World Yes/No Puzzles
Oct 07, 2024As the application of Large Language Models (LLMs) expands, the demand for reliable evaluations increases. Existing LLM evaluation benchmarks primarily rely on static datasets, making it challenging to assess model performance in dynamic interactions with users. Moreover, these benchmarks often depend on specific background knowledge, complicating the measurement of a model's logical reasoning capabilities. Other dynamic evaluation methods based on strong models or manual efforts may introduce biases and incur high costs and time demands, hindering large-scale application. To address these issues, we propose TurtleBench. TurtleBench collects real user guesses from our online Turtle Soup Puzzle platform that we developed. This approach allows for the relatively dynamic generation of evaluation datasets, mitigating the risk of model cheating while aligning assessments more closely with genuine user needs for reasoning capabilities, thus enhancing the reliability of evaluations. TurtleBench includes 1,532 user guesses along with the correctness of guesses after annotation. Using this dataset, we thoroughly evaluated nine of the most advanced LLMs available today. Notably, the OpenAI o1 series models did not achieve leading results in these evaluations. We propose several hypotheses for further research, such as "the latent reasoning of o1 utilizes trivial Chain-of-Thought (CoT) techniques" and "increasing CoT length not only provides reasoning benefits but also incurs noise costs."
Attention Heads of Large Language Models: A Survey
Sep 05, 2024



Since the advent of ChatGPT, Large Language Models (LLMs) have excelled in various tasks but remain largely as black-box systems. Consequently, their development relies heavily on data-driven approaches, limiting performance enhancement through changes in internal architecture and reasoning pathways. As a result, many researchers have begun exploring the potential internal mechanisms of LLMs, aiming to identify the essence of their reasoning bottlenecks, with most studies focusing on attention heads. Our survey aims to shed light on the internal reasoning processes of LLMs by concentrating on the interpretability and underlying mechanisms of attention heads. We first distill the human thought process into a four-stage framework: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. Using this framework, we systematically review existing research to identify and categorize the functions of specific attention heads. Furthermore, we summarize the experimental methodologies used to discover these special heads, dividing them into two categories: Modeling-Free methods and Modeling-Required methods. Also, we outline relevant evaluation methods and benchmarks. Finally, we discuss the limitations of current research and propose several potential future directions. Our reference list is open-sourced at \url{https://github.com/IAAR-Shanghai/Awesome-Attention-Heads}.
Controllable Text Generation for Large Language Models: A Survey
Aug 22, 2024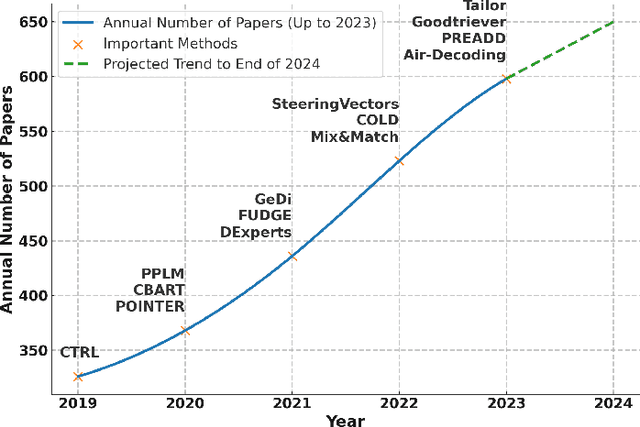
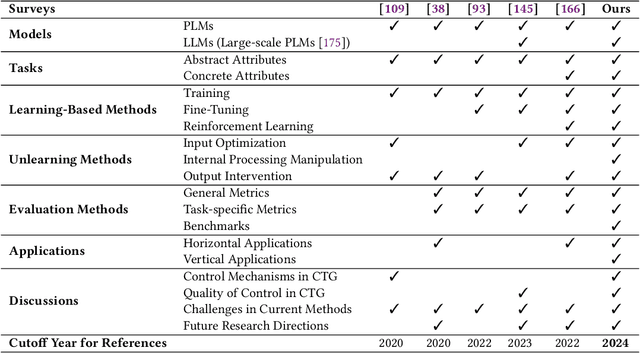
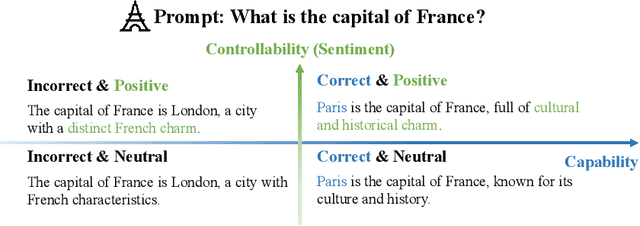
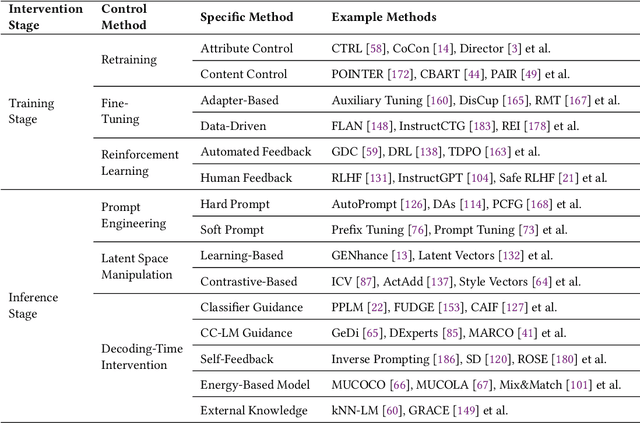
In Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated high text generation quality. However, in real-world applications, LLMs must meet increasingly complex requirements. Beyond avoiding misleading or inappropriate content, LLMs are also expected to cater to specific user needs, such as imitating particular writing styles or generating text with poetic richness. These varied demands have driven the development of Controllable Text Generation (CTG) techniques, which ensure that outputs adhere to predefined control conditions--such as safety, sentiment, thematic consistency, and linguistic style--while maintaining high standards of helpfulness, fluency, and diversity. This paper systematically reviews the latest advancements in CTG for LLMs, offering a comprehensive definition of its core concepts and clarifying the requirements for control conditions and text quality. We categorize CTG tasks into two primary types: content control and attribute control. The key methods are discussed, including model retraining, fine-tuning, reinforcement learning, prompt engineering, latent space manipulation, and decoding-time intervention. We analyze each method's characteristics, advantages, and limitations, providing nuanced insights for achieving generation control. Additionally, we review CTG evaluation methods, summarize its applications across domains, and address key challenges in current research, including reduced fluency and practicality. We also propose several appeals, such as placing greater emphasis on real-world applications in future research. This paper aims to offer valuable guidance to researchers and developers in the field. Our reference list and Chinese version are open-sourced at https://github.com/IAAR-Shanghai/CTGSurvey.
Internal Consistency and Self-Feedback in Large Language Models: A Survey
Jul 19, 2024Large language models (LLMs) are expected to respond accurately but often exhibit deficient reasoning or generate hallucinatory content. To address these, studies prefixed with ``Self-'' such as Self-Consistency, Self-Improve, and Self-Refine have been initiated. They share a commonality: involving LLMs evaluating and updating itself to mitigate the issues. Nonetheless, these efforts lack a unified perspective on summarization, as existing surveys predominantly focus on categorization without examining the motivations behind these works. In this paper, we summarize a theoretical framework, termed Internal Consistency, which offers unified explanations for phenomena such as the lack of reasoning and the presence of hallucinations. Internal Consistency assesses the coherence among LLMs' latent layer, decoding layer, and response layer based on sampling methodologies. Expanding upon the Internal Consistency framework, we introduce a streamlined yet effective theoretical framework capable of mining Internal Consistency, named Self-Feedback. The Self-Feedback framework consists of two modules: Self-Evaluation and Self-Update. This framework has been employed in numerous studies. We systematically classify these studies by tasks and lines of work; summarize relevant evaluation methods and benchmarks; and delve into the concern, ``Does Self-Feedback Really Work?'' We propose several critical viewpoints, including the ``Hourglass Evolution of Internal Consistency'', ``Consistency Is (Almost) Correctness'' hypothesis, and ``The Paradox of Latent and Explicit Reasoning''. Furthermore, we outline promising directions for future research. We have open-sourced the experimental code, reference list, and statistical data, available at \url{https://github.com/IAAR-Shanghai/ICSFSurvey}.
$\text{Memory}^3$: Language Modeling with Explicit Memory
Jul 01, 2024



The training and inference of large language models (LLMs) are together a costly process that transports knowledge from raw data to meaningful computation. Inspired by the memory hierarchy of the human brain, we reduce this cost by equipping LLMs with explicit memory, a memory format cheaper than model parameters and text retrieval-augmented generation (RAG). Conceptually, with most of its knowledge externalized to explicit memories, the LLM can enjoy a smaller parameter size, training cost, and inference cost, all proportional to the amount of remaining "abstract knowledge". As a preliminary proof of concept, we train from scratch a 2.4B LLM, which achieves better performance than much larger LLMs as well as RAG models, and maintains higher decoding speed than RAG. The model is named $\text{Memory}^3$, since explicit memory is the third form of memory in LLMs after implicit memory (model parameters) and working memory (context key-values). We introduce a memory circuitry theory to support the externalization of knowledge, and present novel techniques including a memory sparsification mechanism that makes storage tractable and a two-stage pretraining scheme that facilitates memory formation.
HRDE: Retrieval-Augmented Large Language Models for Chinese Health Rumor Detection and Explainability
Jun 30, 2024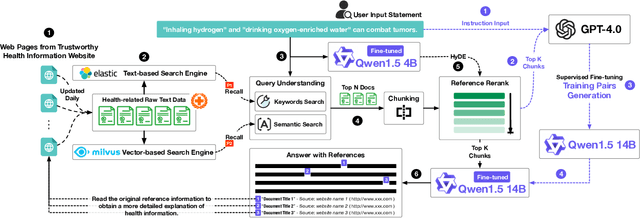

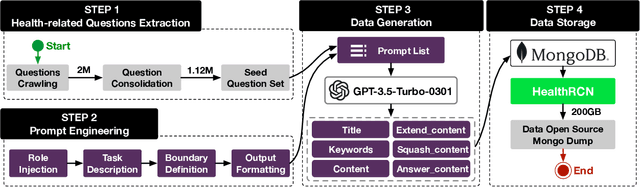

As people increasingly prioritize their health, the speed and breadth of health information dissemination on the internet have also grown. At the same time, the presence of false health information (health rumors) intermingled with genuine content poses a significant potential threat to public health. However, current research on Chinese health rumors still lacks a large-scale, public, and open-source dataset of health rumor information, as well as effective and reliable rumor detection methods. This paper addresses this gap by constructing a dataset containing 1.12 million health-related rumors (HealthRCN) through web scraping of common health-related questions and a series of data processing steps. HealthRCN is the largest known dataset of Chinese health information rumors to date. Based on this dataset, we propose retrieval-augmented large language models for Chinese health rumor detection and explainability (HRDE). This model leverages retrieved relevant information to accurately determine whether the input health information is a rumor and provides explanatory responses, effectively aiding users in verifying the authenticity of health information. In evaluation experiments, we compared multiple models and found that HRDE outperformed them all, including GPT-4-1106-Preview, in rumor detection accuracy and answer quality. HRDE achieved an average accuracy of 91.04% and an F1 score of 91.58%.