 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Full-Pipeline Framework for Evaluating Membership Inference Attacks in Machine Learning
May 28, 2026While Membership Inference Attacks (MIAs) are the prevailing method for identifying training data, their application has expanded into privacy auditing and machine unlearning. Nevertheless, the field lacks a systematic framework for evaluating how different contexts affect MIA efficacy. Without such a characterization, practitioners risk deploying algorithms that perform well on benchmarks but become statistically irrelevant when faced with the nuances of specific, real-world datasets. To bridge this gap and provide actionable insights, we introduce a comprehensive evaluation framework that systematically characterizes privacy risks across the entire machine learning pipeline, spanning data, architectures, algorithms, and post-training modules. Designed to inherently capture diverse operational contexts, our framework rigorously evaluates state-of-the-art MIAs across a broad spectrum of training configurations. To account for varying misclassification costs in real-world deployments, we employ three complementary metrics: Balanced Accuracy for symmetric costs, alongside TPR at low FPR (or TNR at low FNR) for asymmetric scenarios where false alarms or missed detections are strictly penalized. Furthermore, recognizing that existing MIAs assume divergent adversary capabilities, we formalize two standardized threat models and adapt these attacks into corresponding variants to ensure an equitable benchmark. Extensive empirical evaluations demonstrate that the efficacy of specific MIA methodologies is highly sensitive to the assumed threat models and chosen evaluation metrics. Ultimately, we distill these findings into actionable guidelines and provide a ready-to-use auditing toolkit, empowering practitioners to conduct better privacy assessments.
MemReranker: Reasoning-Aware Reranking for Agent Memory Retrieval
May 07, 2026In agent memory systems, the reranking model serves as the critical bridge connecting user queries with long-term memory. Most systems adopt the "retrieve-then-rerank" two-stage paradigm, but generic reranking models rely on semantic similarity matching and lack genuine reasoning capabilities, leading to a problem where recalled results are semantically highly relevant yet do not contain the key information needed to answer the question. This deficiency manifests in memory scenarios as three specific problems. First, relevance scores are miscalibrated, making threshold-based filtering difficult. Second, ranking degrades when facing temporal constraints, causal reasoning, and other complex queries. Third, the model cannot leverage dialogue context for semantic disambiguation. This report introduces MemReranker, a reranking model family (0.6B/4B) built on Qwen3-Reranker through multi-stage LLM knowledge distillation. Multi-teacher pairwise comparisons generate calibrated soft labels, BCE pointwise distillation establishes well-distributed scores, and InfoNCE contrastive learning enhances hard-sample discrimination. Training data combines general corpora with memory-specific multi-turn dialogue data covering temporal constraints, causal reasoning, and coreference resolution. On the memory retrieval benchmark, MemReranker-0.6B substantially outperforms BGE-Reranker and matches open-source 4B/8B models as well as GPT-4o-mini on key metrics. MemReranker-4B further achieves 0.737 MAP, with several metrics on par with Gemini-3-Flash, while maintaining inference latency at only 10--20\% of large models. On finance and healthcare vertical-domain benchmarks, the models preserve generalization capabilities on par with mainstream large-parameter rerankers.
MemReader: From Passive to Active Extraction for Long-Term Agent Memory
Apr 09, 2026Long-term memory is fundamental for personalized and autonomous agents, yet populating it remains a bottleneck. Existing systems treat memory extraction as a one-shot, passive transcription from context to structured entries, which struggles with noisy dialogue, missing references, and cross-turn dependencies, leading to memory pollution, low-value writes, and inconsistency. In this paper, we introduce the MemReader family for active long-term memory extraction in agent systems: MemReader-0.6B, a compact and cost-efficient passive extractor distilled for accurate and schema-consistent structured outputs, and MemReader-4B, an active extractor optimized with Group Relative Policy Optimization (GRPO) to make memory writing decisions. Under a ReAct-style paradigm, MemReader-4B explicitly evaluates information value, reference ambiguity, and completeness before acting, and can selectively write memories, defer incomplete inputs, retrieve historical context, or discard irrelevant chatter. Experiments on LOCOMO, LongMemEval, and HaluMem show that MemReader consistently outperforms existing extraction-based baselines. In particular, MemReader-4B achieves state-of-the-art performance on tasks involving knowledge updating, temporal reasoning, and hallucination reduction. These results suggest that effective agent memory requires not merely extracting more information, but performing reasoning-driven and selective memory extraction to build low-noise and dynamically evolving long-term memory. Furthermore, MemReader has been integrated into MemOS and is being deployed in real-world applications. To support future research and adoption, we release the models and provide public API access.
MemEmo: Evaluating Emotion in Memory Systems of Agents
Feb 27, 2026Memory systems address the challenge of context loss in Large Language Model during prolonged interactions. However, compared to human cognition, the efficacy of these systems in processing emotion-related information remains inconclusive. To address this gap, we propose an emotion-enhanced memory evaluation benchmark to assess the performance of mainstream and state-of-the-art memory systems in handling affective information. We developed the \textbf{H}uman-\textbf{L}ike \textbf{M}emory \textbf{E}motion (\textbf{HLME}) dataset, which evaluates memory systems across three dimensions: emotional information extraction, emotional memory updating, and emotional memory question answering. Experimental results indicate that none of the evaluated systems achieve robust performance across all three tasks. Our findings provide an objective perspective on the current deficiencies of memory systems in processing emotional memories and suggest a new trajectory for future research and system optimization.
Inside Out: Evolving User-Centric Core Memory Trees for Long-Term Personalized Dialogue Systems
Jan 08, 2026Existing long-term personalized dialogue systems struggle to reconcile unbounded interaction streams with finite context constraints, often succumbing to memory noise accumulation, reasoning degradation, and persona inconsistency. To address these challenges, this paper proposes Inside Out, a framework that utilizes a globally maintained PersonaTree as the carrier of long-term user profiling. By constraining the trunk with an initial schema and updating the branches and leaves, PersonaTree enables controllable growth, achieving memory compression while preserving consistency. Moreover, we train a lightweight MemListener via reinforcement learning with process-based rewards to produce structured, executable, and interpretable {ADD, UPDATE, DELETE, NO_OP} operations, thereby supporting the dynamic evolution of the personalized tree. During response generation, PersonaTree is directly leveraged to enhance outputs in latency-sensitive scenarios; when users require more details, the agentic mode is triggered to introduce details on-demand under the constraints of the PersonaTree. Experiments show that PersonaTree outperforms full-text concatenation and various personalized memory systems in suppressing contextual noise and maintaining persona consistency. Notably, the small MemListener model achieves memory-operation decision performance comparable to, or even surpassing, powerful reasoning models such as DeepSeek-R1-0528 and Gemini-3-Pro.
HaluMem: Evaluating Hallucinations in Memory Systems of Agents
Nov 05, 2025Memory systems are key components that enable AI systems such as LLMs and AI agents to achieve long-term learning and sustained interaction. However, during memory storage and retrieval, these systems frequently exhibit memory hallucinations, including fabrication, errors, conflicts, and omissions. Existing evaluations of memory hallucinations are primarily end-to-end question answering, which makes it difficult to localize the operational stage within the memory system where hallucinations arise. To address this, we introduce the Hallucination in Memory Benchmark (HaluMem), the first operation level hallucination evaluation benchmark tailored to memory systems. HaluMem defines three evaluation tasks (memory extraction, memory updating, and memory question answering) to comprehensively reveal hallucination behaviors across different operational stages of interaction. To support evaluation, we construct user-centric, multi-turn human-AI interaction datasets, HaluMem-Medium and HaluMem-Long. Both include about 15k memory points and 3.5k multi-type questions. The average dialogue length per user reaches 1.5k and 2.6k turns, with context lengths exceeding 1M tokens, enabling evaluation of hallucinations across different context scales and task complexities. Empirical studies based on HaluMem show that existing memory systems tend to generate and accumulate hallucinations during the extraction and updating stages, which subsequently propagate errors to the question answering stage. Future research should focus on developing interpretable and constrained memory operation mechanisms that systematically suppress hallucinations and improve memory reliability.
Over-The-Air Phase Calibration of Spaceborne Phased Array for LEO Satellite Communications
Oct 09, 2025To avoid the unpredictable phase deviations of the spaceborne phased array (SPA), this paper considers the over-the-air (OTA) phase calibration of the SPA for the low earth orbit (LEO) satellite communications, where the phase deviations of the SPA and the unknown channel are jointly estimated with multiple transmissions of the pilots. Moreover, the Cramer Rao Bound (CRB) is derived, and the optimization of beam patterns is also presented to lower the root mean squared error (RMSE) of the OTA calibration. The simulation results verify the effectiveness of the proposed OTA phase calibration algorithm as the RMSEs of the phase estimates closely approach the corresponding CRB, and the beam pattern optimization scheme is also validated for more than 4dB gain of SNR over the randomly generated beam patterns.
GuessArena: Guess Who I Am? A Self-Adaptive Framework for Evaluating LLMs in Domain-Specific Knowledge and Reasoning
May 28, 2025The evaluation of large language models (LLMs) has traditionally relied on static benchmarks, a paradigm that poses two major limitations: (1) predefined test sets lack adaptability to diverse application domains, and (2) standardized evaluation protocols often fail to capture fine-grained assessments of domain-specific knowledge and contextual reasoning abilities. To overcome these challenges, we propose GuessArena, an adaptive evaluation framework grounded in adversarial game-based interactions. Inspired by the interactive structure of the Guess Who I Am? game, our framework seamlessly integrates dynamic domain knowledge modeling with progressive reasoning assessment to improve evaluation fidelity. Empirical studies across five vertical domains-finance, healthcare, manufacturing, information technology, and education-demonstrate that GuessArena effectively distinguishes LLMs in terms of domain knowledge coverage and reasoning chain completeness. Compared to conventional benchmarks, our method provides substantial advantages in interpretability, scalability, and scenario adaptability.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025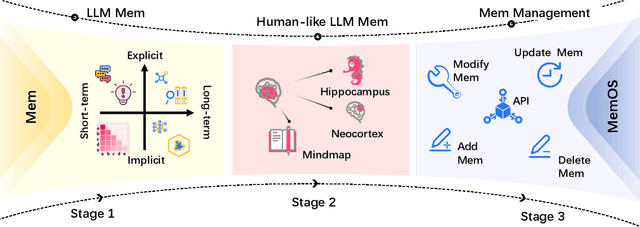
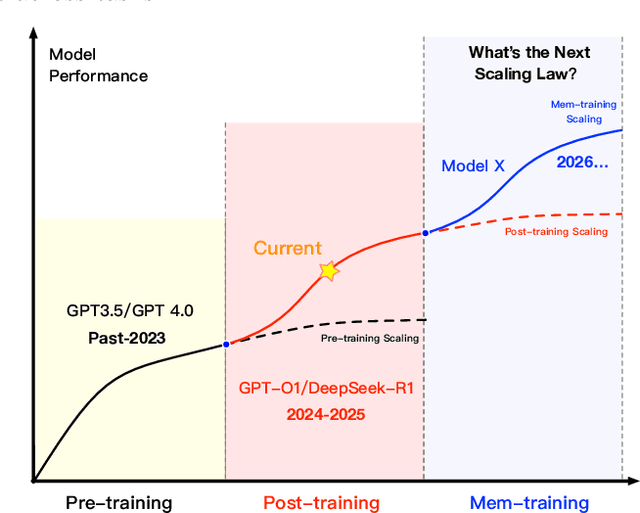
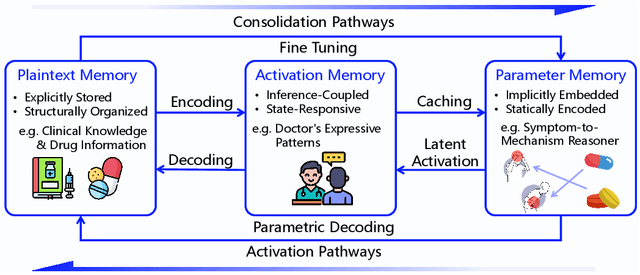
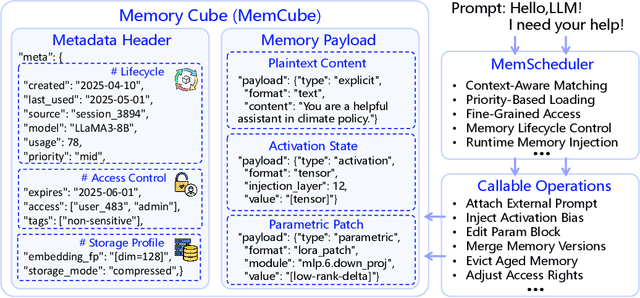
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
xVerify: Efficient Answer Verifier for Reasoning Model Evaluations
Apr 14, 2025With the release of the o1 model by OpenAI, reasoning models adopting slow thinking strategies have gradually emerged. As the responses generated by such models often include complex reasoning, intermediate steps, and self-reflection, existing evaluation methods are often inadequate. They struggle to determine whether the LLM output is truly equivalent to the reference answer, and also have difficulty identifying and extracting the final answer from long, complex responses. To address this issue, we propose xVerify, an efficient answer verifier for reasoning model evaluations. xVerify demonstrates strong capability in equivalence judgment, enabling it to effectively determine whether the answers produced by reasoning models are equivalent to reference answers across various types of objective questions. To train and evaluate xVerify, we construct the VAR dataset by collecting question-answer pairs generated by multiple LLMs across various datasets, leveraging multiple reasoning models and challenging evaluation sets designed specifically for reasoning model assessment. A multi-round annotation process is employed to ensure label accuracy. Based on the VAR dataset, we train multiple xVerify models of different scales. In evaluation experiments conducted on both the test set and generalization set, all xVerify models achieve overall F1 scores and accuracy exceeding 95\%. Notably, the smallest variant, xVerify-0.5B-I, outperforms all evaluation methods except GPT-4o, while xVerify-3B-Ib surpasses GPT-4o in overall performance. These results validate the effectiveness and generalizability of xVerify.