 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence
Oct 25, 2023Spiking neural networks (SNNs) aim to realize brain-inspired intelligence on neuromorphic chips with high energy efficiency by introducing neural dynamics and spike properties. As the emerging spiking deep learning paradigm attracts increasing interest, traditional programming frameworks cannot meet the demands of the automatic differentiation, parallel computation acceleration, and high integration of processing neuromorphic datasets and deployment. In this work, we present the SpikingJelly framework to address the aforementioned dilemma. We contribute a full-stack toolkit for pre-processing neuromorphic datasets, building deep SNNs, optimizing their parameters, and deploying SNNs on neuromorphic chips. Compared to existing methods, the training of deep SNNs can be accelerated $11\times$, and the superior extensibility and flexibility of SpikingJelly enable users to accelerate custom models at low costs through multilevel inheritance and semiautomatic code generation. SpikingJelly paves the way for synthesizing truly energy-efficient SNN-based machine intelligence systems, which will enrich the ecology of neuromorphic computing.
Auto-Spikformer: Spikformer Architecture Search
Jun 01, 2023The integration of self-attention mechanisms into Spiking Neural Networks (SNNs) has garnered considerable interest in the realm of advanced deep learning, primarily due to their biological properties. Recent advancements in SNN architecture, such as Spikformer, have demonstrated promising outcomes by leveraging Spiking Self-Attention (SSA) and Spiking Patch Splitting (SPS) modules. However, we observe that Spikformer may exhibit excessive energy consumption, potentially attributable to redundant channels and blocks. To mitigate this issue, we propose Auto-Spikformer, a one-shot Transformer Architecture Search (TAS) method, which automates the quest for an optimized Spikformer architecture. To facilitate the search process, we propose methods Evolutionary SNN neurons (ESNN), which optimizes the SNN parameters, and apply the previous method of weight entanglement supernet training, which optimizes the Vision Transformer (ViT) parameters. Moreover, we propose an accuracy and energy balanced fitness function $\mathcal{F}_{AEB}$ that jointly considers both energy consumption and accuracy, and aims to find a Pareto optimal combination that balances these two objectives. Our experimental results demonstrate the effectiveness of Auto-Spikformer, which outperforms the state-of-the-art method including CNN or ViT models that are manually or automatically designed while significantly reducing energy consumption.
Temporal Contrastive Learning for Spiking Neural Networks
May 23, 2023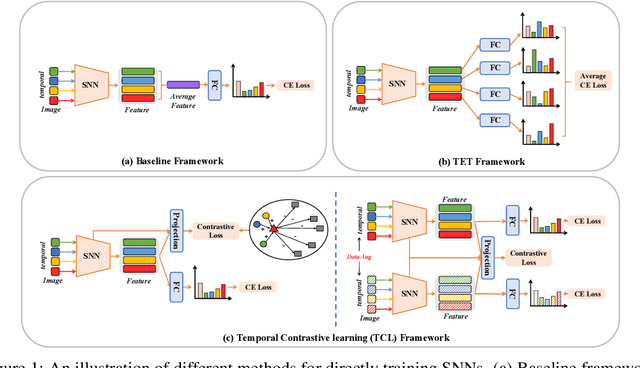
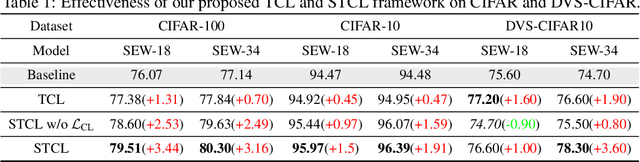
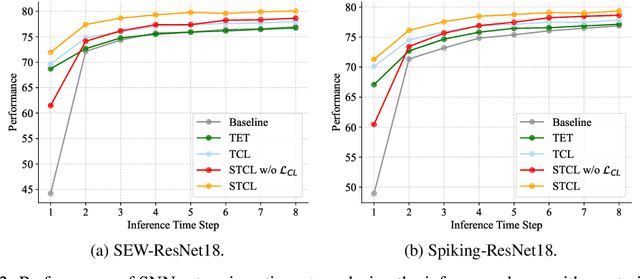

Biologically inspired spiking neural networks (SNNs) have garnered considerable attention due to their low-energy consumption and spatio-temporal information processing capabilities. Most existing SNNs training methods first integrate output information across time steps, then adopt the cross-entropy (CE) loss to supervise the prediction of the average representations. However, in this work, we find the method above is not ideal for the SNNs training as it omits the temporal dynamics of SNNs and degrades the performance quickly with the decrease of inference time steps. One tempting method to model temporal correlations is to apply the same label supervision at each time step and treat them identically. Although it can acquire relatively consistent performance across various time steps, it still faces challenges in obtaining SNNs with high performance. Inspired by these observations, we propose Temporal-domain supervised Contrastive Learning (TCL) framework, a novel method to obtain SNNs with low latency and high performance by incorporating contrastive supervision with temporal domain information. Contrastive learning (CL) prompts the network to discern both consistency and variability in the representation space, enabling it to better learn discriminative and generalizable features. We extend this concept to the temporal domain of SNNs, allowing us to flexibly and fully leverage the correlation between representations at different time steps. Furthermore, we propose a Siamese Temporal-domain supervised Contrastive Learning (STCL) framework to enhance the SNNs via augmentation, temporal and class constraints simultaneously. Extensive experimental results demonstrate that SNNs trained by our TCL and STCL can achieve both high performance and low latency, achieving state-of-the-art performance on a variety of datasets (e.g., CIFAR-10, CIFAR-100, and DVS-CIFAR10).
Parallel Spiking Neurons with High Efficiency and Long-term Dependencies Learning Ability
Apr 25, 2023



Vanilla spiking neurons in Spiking Neural Networks (SNNs) use charge-fire-reset neuronal dynamics, which can only be simulated in serial and can hardly learn long-time dependencies. We find that when removing reset, the neuronal dynamics are reformulated in a non-iterative form and can be parallelized. By rewriting neuronal dynamics without resetting to a general formulation, we propose the Parallel Spiking Neuron (PSN), which uses dense connections between time-steps to maximize the utilization of temporal information. To avoid the use of future inputs for low-latency inference, we add masks on the weights and obtain the masked PSN. By sharing weights across time-steps, the sliding PSN is proposed with the ability to deal with sequences with variant lengths. We evaluate the PSN family on simulation speed and temporal/static data classification, and the results show the overwhelming advantage of the PSN family in efficiency and accuracy. To our best knowledge, this is the first research about parallelizing spiking neurons and can be a cornerstone for the spiking deep learning community. Our codes are available at \url{https://github.com/fangwei123456/Parallel-Spiking-Neuron}.
A Unified Framework for Soft Threshold Pruning
Feb 25, 2023Soft threshold pruning is among the cutting-edge pruning methods with state-of-the-art performance. However, previous methods either perform aimless searching on the threshold scheduler or simply set the threshold trainable, lacking theoretical explanation from a unified perspective. In this work, we reformulate soft threshold pruning as an implicit optimization problem solved using the Iterative Shrinkage-Thresholding Algorithm (ISTA), a classic method from the fields of sparse recovery and compressed sensing. Under this theoretical framework, all threshold tuning strategies proposed in previous studies of soft threshold pruning are concluded as different styles of tuning $L_1$-regularization term. We further derive an optimal threshold scheduler through an in-depth study of threshold scheduling based on our framework. This scheduler keeps $L_1$-regularization coefficient stable, implying a time-invariant objective function from the perspective of optimization. In principle, the derived pruning algorithm could sparsify any mathematical model trained via SGD. We conduct extensive experiments and verify its state-of-the-art performance on both Artificial Neural Networks (ResNet-50 and MobileNet-V1) and Spiking Neural Networks (SEW ResNet-18) on ImageNet datasets. On the basis of this framework, we derive a family of pruning methods, including sparsify-during-training, early pruning, and pruning at initialization. The code is available at https://github.com/Yanqi-Chen/LATS.
TrafficCAM: A Versatile Dataset for Traffic Flow Segmentation
Nov 17, 2022



Traffic flow analysis is revolutionising traffic management. Qualifying traffic flow data, traffic control bureaus could provide drivers with real-time alerts, advising the fastest routes and therefore optimising transportation logistics and reducing congestion. The existing traffic flow datasets have two major limitations. They feature a limited number of classes, usually limited to one type of vehicle, and the scarcity of unlabelled data. In this paper, we introduce a new benchmark traffic flow image dataset called TrafficCAM. Our dataset distinguishes itself by two major highlights. Firstly, TrafficCAM provides both pixel-level and instance-level semantic labelling along with a large range of types of vehicles and pedestrians. It is composed of a large and diverse set of video sequences recorded in streets from eight Indian cities with stationary cameras. Secondly, TrafficCAM aims to establish a new benchmark for developing fully-supervised tasks, and importantly, semi-supervised learning techniques. It is the first dataset that provides a vast amount of unlabelled data, helping to better capture traffic flow qualification under a low cost annotation requirement. More precisely, our dataset has 4,402 image frames with semantic and instance annotations along with 59,944 unlabelled image frames. We validate our new dataset through a large and comprehensive range of experiments on several state-of-the-art approaches under four different settings: fully-supervised semantic and instance segmentation, and semi-supervised semantic and instance segmentation tasks. Our benchmark dataset will be released.
Pruning of Deep Spiking Neural Networks through Gradient Rewiring
May 20, 2021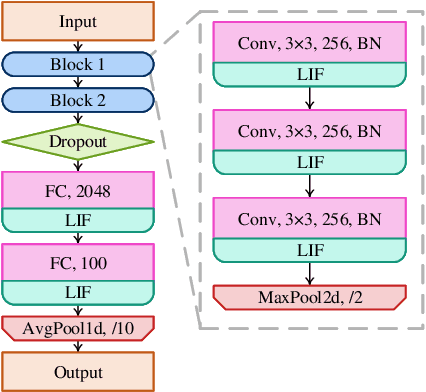
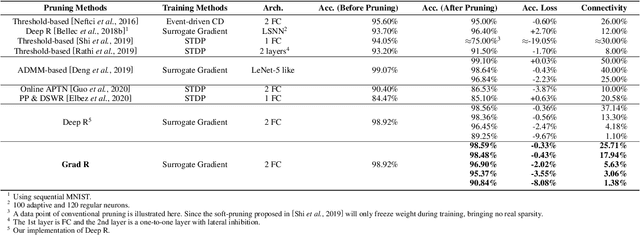
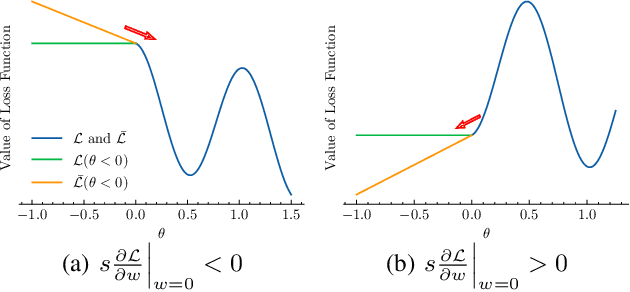

Spiking Neural Networks (SNNs) have been attached great importance due to their biological plausibility and high energy-efficiency on neuromorphic chips. As these chips are usually resource-constrained, the compression of SNNs is thus crucial along the road of practical use of SNNs. Most existing methods directly apply pruning approaches in artificial neural networks (ANNs) to SNNs, which ignore the difference between ANNs and SNNs, thus limiting the performance of the pruned SNNs. Besides, these methods are only suitable for shallow SNNs. In this paper, inspired by synaptogenesis and synapse elimination in the neural system, we propose gradient rewiring (Grad R), a joint learning algorithm of connectivity and weight for SNNs, that enables us to seamlessly optimize network structure without retrain. Our key innovation is to redefine the gradient to a new synaptic parameter, allowing better exploration of network structures by taking full advantage of the competition between pruning and regrowth of connections. The experimental results show that the proposed method achieves minimal loss of SNNs' performance on MNIST and CIFAR-10 dataset so far. Moreover, it reaches a $\sim$3.5% accuracy loss under unprecedented 0.73% connectivity, which reveals remarkable structure refining capability in SNNs. Our work suggests that there exists extremely high redundancy in deep SNNs. Our codes are available at https://github.com/Yanqi-Chen/Gradient-Rewiring .
Spike-based Residual Blocks
Feb 08, 2021



Deep Spiking Neural Networks (SNNs) are harder to train than ANNs because of their discrete binary activation and spatio-temporal domain error back-propagation. Considering the huge success of ResNet in ANNs' deep learning, it is natural to attempt to use residual learning to train deep SNNs. Previous Spiking ResNet used a similar residual block to the standard block of ResNet, which we regard as inadequate for SNNs and which still causes the degradation problem. In this paper, we propose the spike-element-wise (SEW) residual block and prove that it can easily implement the residual learning. We evaluate our SEW ResNet on ImageNet. The experiment results show that the SEW ResNet can obtain higher performance by simply adding more layers, providing a simple method to train deep SNNs.