 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Ensemble Inspired Approach for Effective Training of Binary-Weight Spiking Neural Networks
Aug 18, 2025Spiking Neural Networks (SNNs) are a promising approach to low-power applications on neuromorphic hardware due to their energy efficiency. However, training SNNs is challenging because of the non-differentiable spike generation function. To address this issue, the commonly used approach is to adopt the backpropagation through time framework, while assigning the gradient of the non-differentiable function with some surrogates. Similarly, Binary Neural Networks (BNNs) also face the non-differentiability problem and rely on approximating gradients. However, the deep relationship between these two fields and how their training techniques can benefit each other has not been systematically researched. Furthermore, training binary-weight SNNs is even more difficult. In this work, we present a novel perspective on the dynamics of SNNs and their close connection to BNNs through an analysis of the backpropagation process. We demonstrate that training a feedforward SNN can be viewed as training a self-ensemble of a binary-activation neural network with noise injection. Drawing from this new understanding of SNN dynamics, we introduce the Self-Ensemble Inspired training method for (Binary-Weight) SNNs (SEI-BWSNN), which achieves high-performance results with low latency even for the case of the 1-bit weights. Specifically, we leverage a structure of multiple shortcuts and a knowledge distillation-based training technique to improve the training of (binary-weight) SNNs. Notably, by binarizing FFN layers in a Transformer architecture, our approach achieves 82.52% accuracy on ImageNet with only 2 time steps, indicating the effectiveness of our methodology and the potential of binary-weight SNNs.
Channel-wise Parallelizable Spiking Neuron with Multiplication-free Dynamics and Large Temporal Receptive Fields
Jan 24, 2025Spiking Neural Networks (SNNs) are distinguished from Artificial Neural Networks (ANNs) for their sophisticated neuronal dynamics and sparse binary activations (spikes) inspired by the biological neural system. Traditional neuron models use iterative step-by-step dynamics, resulting in serial computation and slow training speed of SNNs. Recently, parallelizable spiking neuron models have been proposed to fully utilize the massive parallel computing ability of graphics processing units to accelerate the training of SNNs. However, existing parallelizable spiking neuron models involve dense floating operations and can only achieve high long-term dependencies learning ability with a large order at the cost of huge computational and memory costs. To solve the dilemma of performance and costs, we propose the mul-free channel-wise Parallel Spiking Neuron, which is hardware-friendly and suitable for SNNs' resource-restricted application scenarios. The proposed neuron imports the channel-wise convolution to enhance the learning ability, induces the sawtooth dilations to reduce the neuron order, and employs the bit shift operation to avoid multiplications. The algorithm for design and implementation of acceleration methods is discussed meticulously. Our methods are validated in neuromorphic Spiking Heidelberg Digits voices, sequential CIFAR images, and neuromorphic DVS-Lip vision datasets, achieving the best accuracy among SNNs. Training speed results demonstrate the effectiveness of our acceleration methods, providing a practical reference for future research.
High-speed and High-quality Vision Reconstruction of Spike Camera with Spike Stability Theorem
Dec 16, 2024



Neuromorphic vision sensors, such as the dynamic vision sensor (DVS) and spike camera, have gained increasing attention in recent years. The spike camera can detect fine textures by mimicking the fovea in the human visual system, and output a high-frequency spike stream. Real-time high-quality vision reconstruction from the spike stream can build a bridge to high-level vision task applications of the spike camera. To realize high-speed and high-quality vision reconstruction of the spike camera, we propose a new spike stability theorem that reveals the relationship between spike stream characteristics and stable light intensity. Based on the spike stability theorem, two parameter-free algorithms are designed for the real-time vision reconstruction of the spike camera. To demonstrate the performances of our algorithms, two datasets (a public dataset PKU-Spike-High-Speed and a newly constructed dataset SpikeCityPCL) are used to compare the reconstruction quality and speed of various reconstruction methods. Experimental results show that, compared with the current state-of-the-art (SOTA) reconstruction methods, our reconstruction methods obtain the best tradeoff between the reconstruction quality and speed. Additionally, we design the FPGA implementation method of our algorithms to realize the real-time (running at 20,000 FPS) visual reconstruction. Our work provides new theorem and algorithm foundations for the real-time edge-end vision processing of the spike camera.
A High Energy-Efficiency Multi-core Neuromorphic Architecture for Deep SNN Training
Dec 10, 2024
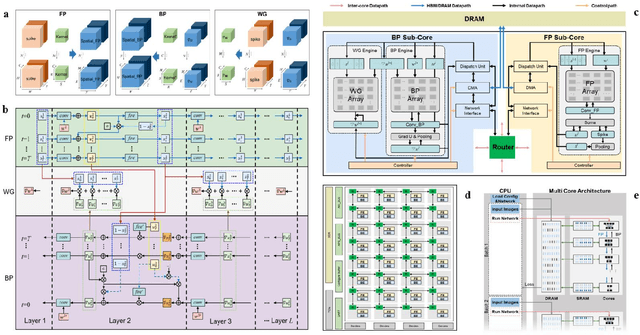
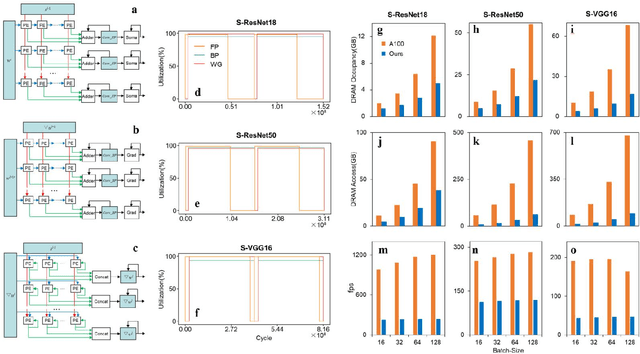
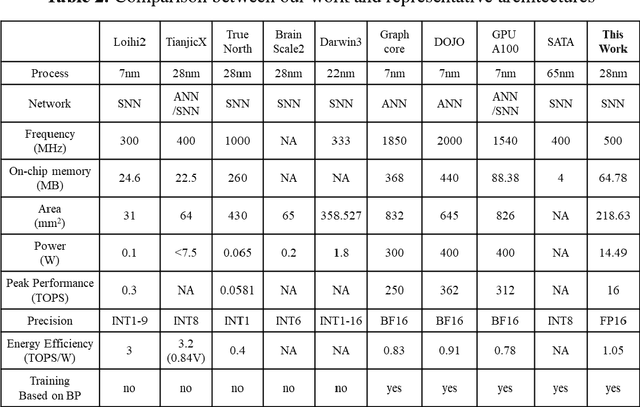
There is a growing necessity for edge training to adapt to dynamically changing environment. Neuromorphic computing represents a significant pathway for high-efficiency intelligent computation in energy-constrained edges, but existing neuromorphic architectures lack the ability of directly training spiking neural networks (SNNs) based on backpropagation. We develop a multi-core neuromorphic architecture with Feedforward-Propagation, Back-Propagation, and Weight-Gradient engines in each core, supporting high efficient parallel computing at both the engine and core levels. It combines various data flows and sparse computation optimization by fully leveraging the sparsity in SNN training, obtaining a high energy efficiency of 1.05TFLOPS/W@ FP16 @ 28nm, 55 ~ 85% reduction of DRAM access compared to A100 GPU in SNN trainings, and a 20-core deep SNN training and a 5-worker federated learning on FPGAs. Our study develops the first multi-core neuromorphic architecture supporting the direct SNN training, facilitating the neuromorphic computing in edge-learnable applications.
Core Placement Optimization of Many-core Brain-Inspired Near-Storage Systems for Spiking Neural Network Training
Nov 29, 2024



With the increasing application scope of spiking neural networks (SNN), the complexity of SNN models has surged, leading to an exponential growth in demand for AI computility. As the new generation computing architecture of the neural networks, the efficiency and power consumption of distributed storage and parallel computing in the many-core near-memory computing system have attracted much attention. Among them, the mapping problem from logical cores to physical cores is one of the research hotspots. In order to improve the computing parallelism and system throughput of the many-core near-memory computing system, and to reduce power consumption, we propose a SNN training many-core deployment optimization method based on Off-policy Deterministic Actor-Critic. We utilize deep reinforcement learning as a nonlinear optimizer, treating the many-core topology as network graph features and using graph convolution to input the many-core structure into the policy network. We update the parameters of the policy network through near-end policy optimization to achieve deployment optimization of SNN models in the many-core near-memory computing architecture to reduce chip power consumption. To handle large-dimensional action spaces, we use continuous values matching the number of cores as the output of the policy network and then discretize them again to obtain new deployment schemes. Furthermore, to further balance inter-core computation latency and improve system throughput, we propose a model partitioning method with a balanced storage and computation strategy. Our method overcomes the problems such as uneven computation and storage loads between cores, and the formation of local communication hotspots, significantly reducing model training time, communication costs, and average flow load between cores in the many-core near-memory computing architecture.
Real-time Stereo-based 3D Object Detection for Streaming Perception
Oct 16, 2024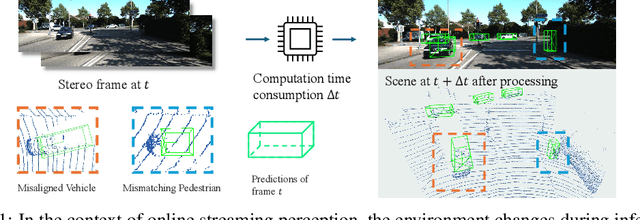
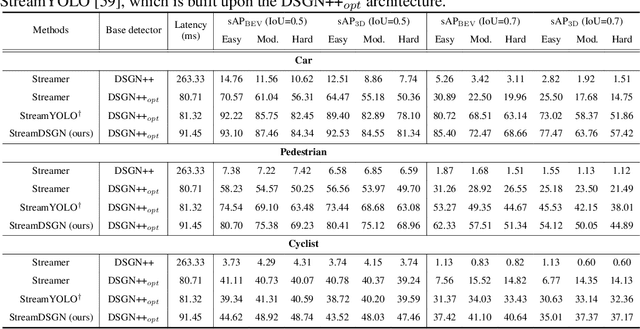
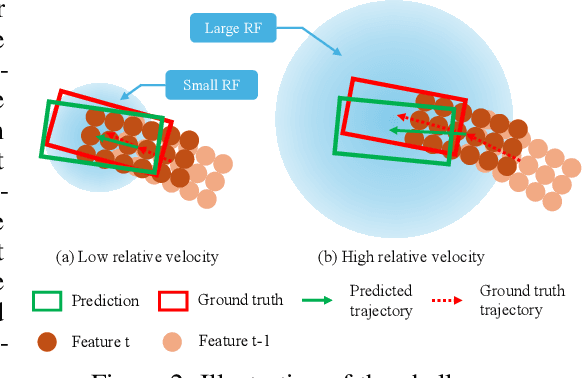
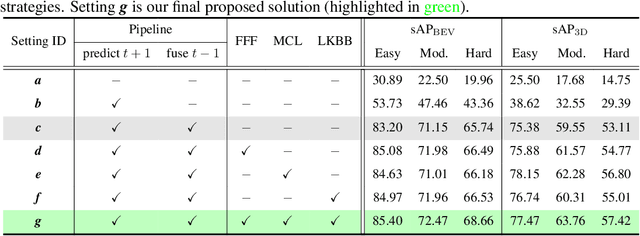
The ability to promptly respond to environmental changes is crucial for the perception system of autonomous driving. Recently, a new task called streaming perception was proposed. It jointly evaluate the latency and accuracy into a single metric for video online perception. In this work, we introduce StreamDSGN, the first real-time stereo-based 3D object detection framework designed for streaming perception. StreamDSGN is an end-to-end framework that directly predicts the 3D properties of objects in the next moment by leveraging historical information, thereby alleviating the accuracy degradation of streaming perception. Further, StreamDSGN applies three strategies to enhance the perception accuracy: (1) A feature-flow-based fusion method, which generates a pseudo-next feature at the current moment to address the misalignment issue between feature and ground truth. (2) An extra regression loss for explicit supervision of object motion consistency in consecutive frames. (3) A large kernel backbone with a large receptive field for effectively capturing long-range spatial contextual features caused by changes in object positions. Experiments on the KITTI Tracking dataset show that, compared with the strong baseline, StreamDSGN significantly improves the streaming average precision by up to 4.33%. Our code is available at https://github.com/weiyangdaren/streamDSGN-pytorch.
Time-Dependent VAE for Building Latent Factor from Visual Neural Activity with Complex Dynamics
Aug 15, 2024



Seeking high-quality neural latent representations to reveal the intrinsic correlation between neural activity and behavior or sensory stimulation has attracted much interest. Currently, some deep latent variable models rely on behavioral information (e.g., movement direction and position) as an aid to build expressive embeddings while being restricted by fixed time scales. Visual neural activity from passive viewing lacks clearly correlated behavior or task information, and high-dimensional visual stimulation leads to intricate neural dynamics. To cope with such conditions, we propose Time-Dependent SwapVAE, following the approach of separating content and style spaces in Swap-VAE, on the basis of which we introduce state variables to construct conditional distributions with temporal dependence for the above two spaces. Our model progressively generates latent variables along neural activity sequences, and we apply self-supervised contrastive learning to shape its latent space. In this way, it can effectively analyze complex neural dynamics from sequences of arbitrary length, even without task or behavioral data as auxiliary inputs. We compare TiDe-SwapVAE with alternative models on synthetic data and neural data from mouse visual cortex. The results show that our model not only accurately decodes complex visual stimuli but also extracts explicit temporal neural dynamics, demonstrating that it builds latent representations more relevant to visual stimulation.
SVFormer: A Direct Training Spiking Transformer for Efficient Video Action Recognition
Jun 21, 2024



Video action recognition (VAR) plays crucial roles in various domains such as surveillance, healthcare, and industrial automation, making it highly significant for the society. Consequently, it has long been a research spot in the computer vision field. As artificial neural networks (ANNs) are flourishing, convolution neural networks (CNNs), including 2D-CNNs and 3D-CNNs, as well as variants of the vision transformer (ViT), have shown impressive performance on VAR. However, they usually demand huge computational cost due to the large data volume and heavy information redundancy introduced by the temporal dimension. To address this challenge, some researchers have turned to brain-inspired spiking neural networks (SNNs), such as recurrent SNNs and ANN-converted SNNs, leveraging their inherent temporal dynamics and energy efficiency. Yet, current SNNs for VAR also encounter limitations, such as nontrivial input preprocessing, intricate network construction/training, and the need for repetitive processing of the same video clip, hindering their practical deployment. In this study, we innovatively propose the directly trained SVFormer (Spiking Video transFormer) for VAR. SVFormer integrates local feature extraction, global self-attention, and the intrinsic dynamics, sparsity, and spike-driven nature of SNNs, to efficiently and effectively extract spatio-temporal features. We evaluate SVFormer on two RGB datasets (UCF101, NTU-RGBD60) and one neuromorphic dataset (DVS128-Gesture), demonstrating comparable performance to the mainstream models in a more efficient way. Notably, SVFormer achieves a top-1 accuracy of 84.03% with ultra-low power consumption (21 mJ/video) on UCF101, which is state-of-the-art among directly trained deep SNNs, showcasing significant advantages over prior models.
Direct Training High-Performance Deep Spiking Neural Networks: A Review of Theories and Methods
May 06, 2024



Spiking neural networks (SNNs) offer a promising energy-efficient alternative to artificial neural networks (ANNs), in virtue of their high biological plausibility, rich spatial-temporal dynamics, and event-driven computation. The direct training algorithms based on the surrogate gradient method provide sufficient flexibility to design novel SNN architectures and explore the spatial-temporal dynamics of SNNs. According to previous studies, the performance of models is highly dependent on their sizes. Recently, direct training deep SNNs have achieved great progress on both neuromorphic datasets and large-scale static datasets. Notably, transformer-based SNNs show comparable performance with their ANN counterparts. In this paper, we provide a new perspective to summarize the theories and methods for training deep SNNs with high performance in a systematic and comprehensive way, including theory fundamentals, spiking neuron models, advanced SNN models and residual architectures, software frameworks and neuromorphic hardware, applications, and future trends. The reviewed papers are collected at https://github.com/zhouchenlin2096/Awesome-Spiking-Neural-Networks
QKFormer: Hierarchical Spiking Transformer using Q-K Attention
Mar 25, 2024



Spiking Transformers, which integrate Spiking Neural Networks (SNNs) with Transformer architectures, have attracted significant attention due to their potential for energy efficiency and high performance. However, existing models in this domain still suffer from suboptimal performance. We introduce several innovations to improve the performance: i) We propose a novel spike-form Q-K attention mechanism, tailored for SNNs, which efficiently models the importance of token or channel dimensions through binary vectors with linear complexity. ii) We incorporate the hierarchical structure, which significantly benefits the performance of both the brain and artificial neural networks, into spiking transformers to obtain multi-scale spiking representation. iii) We design a versatile and powerful patch embedding module with a deformed shortcut specifically for spiking transformers. Together, we develop QKFormer, a hierarchical spiking transformer based on Q-K attention with direct training. QKFormer shows significantly superior performance over existing state-of-the-art SNN models on various mainstream datasets. Notably, with comparable size to Spikformer (66.34 M, 74.81%), QKFormer (64.96 M) achieves a groundbreaking top-1 accuracy of 85.65% on ImageNet-1k, substantially outperforming Spikformer by 10.84%. To our best knowledge, this is the first time that directly training SNNs have exceeded 85% accuracy on ImageNet-1K. The code and models are publicly available at https://github.com/zhouchenlin2096/QKFormer