 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWS-GRPO: Weakly-Supervised Group-Relative Policy Optimization for Rollout-Efficient Reasoning
Feb 19, 2026Group Relative Policy Optimization (GRPO) is effective for training language models on complex reasoning. However, since the objective is defined relative to a group of sampled trajectories, extended deliberation can create more chances to realize relative gains, leading to inefficient reasoning and overthinking, and complicating the trade-off between correctness and rollout efficiency. Controlling this behavior is difficult in practice, considering (i) Length penalties are hard to calibrate because longer rollouts may reflect harder problems that require longer reasoning, penalizing tokens risks truncating useful reasoning along with redundant continuation; and (ii) supervision that directly indicates when to continue or stop is typically unavailable beyond final answer correctness. We propose Weakly Supervised GRPO (WS-GRPO), which improves rollout efficiency by converting terminal rewards into correctness-aware guidance over partial trajectories. Unlike global length penalties that are hard to calibrate, WS-GRPO trains a preference model from outcome-only correctness to produce prefix-level signals that indicate when additional continuation is beneficial. Thus, WS-GRPO supplies outcome-derived continue/stop guidance, reducing redundant deliberation while maintaining accuracy. We provide theoretical results and empirically show on reasoning benchmarks that WS-GRPO substantially reduces rollout length while remaining competitive with GRPO baselines.
AMPS: Adaptive Modality Preference Steering via Functional Entropy
Feb 13, 2026Multimodal Large Language Models (MLLMs) often exhibit significant modality preference, which is a tendency to favor one modality over another. Depending on the input, they may over-rely on linguistic priors relative to visual evidence, or conversely over-attend to visually salient but facts in textual contexts. Prior work has applied a uniform steering intensity to adjust the modality preference of MLLMs. However, strong steering can impair standard inference and increase error rates, whereas weak steering is often ineffective. In addition, because steering sensitivity varies substantially across multimodal instances, a single global strength is difficult to calibrate. To address this limitation with minimal disruption to inference, we introduce an instance-aware diagnostic metric that quantifies each modality's information contribution and reveals sample-specific susceptibility to steering. Building on these insights, we propose a scaling strategy that reduces steering for sensitive samples and a learnable module that infers scaling patterns, enabling instance-aware control of modality preference. Experimental results show that our instance-aware steering outperforms conventional steering in modulating modality preference, achieving effective adjustment while keeping generation error rates low.
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
Feb 04, 2026Spatial embodied intelligence requires agents to act to acquire information under partial observability. While multimodal foundation models excel at passive perception, their capacity for active, self-directed exploration remains understudied. We propose Theory of Space, defined as an agent's ability to actively acquire information through self-directed, active exploration and to construct, revise, and exploit a spatial belief from sequential, partial observations. We evaluate this through a benchmark where the goal is curiosity-driven exploration to build an accurate cognitive map. A key innovation is spatial belief probing, which prompts models to reveal their internal spatial representations at each step. Our evaluation of state-of-the-art models reveals several critical bottlenecks. First, we identify an Active-Passive Gap, where performance drops significantly when agents must autonomously gather information. Second, we find high inefficiency, as models explore unsystematically compared to program-based proxies. Through belief probing, we diagnose that while perception is an initial bottleneck, global beliefs suffer from instability that causes spatial knowledge to degrade over time. Finally, using a false belief paradigm, we uncover Belief Inertia, where agents fail to update obsolete priors with new evidence. This issue is present in text-based agents but is particularly severe in vision-based models. Our findings suggest that current foundation models struggle to maintain coherent, revisable spatial beliefs during active exploration.
General Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
Error Amplification Limits ANN-to-SNN Conversion in Continuous Control
Jan 29, 2026Spiking Neural Networks (SNNs) can achieve competitive performance by converting already existing well-trained Artificial Neural Networks (ANNs), avoiding further costly training. This property is particularly attractive in Reinforcement Learning (RL), where training through environment interaction is expensive and potentially unsafe. However, existing conversion methods perform poorly in continuous control, where suitable baselines are largely absent. We identify error amplification as the key cause: small action approximation errors become temporally correlated across decision steps, inducing cumulative state distribution shift and severe performance degradation. To address this issue, we propose Cross-Step Residual Potential Initialization (CRPI), a lightweight training-free mechanism that carries over residual membrane potentials across decision steps to suppress temporally correlated errors. Experiments on continuous control benchmarks with both vector and visual observations demonstrate that CRPI can be integrated into existing conversion pipelines and substantially recovers lost performance. Our results highlight continuous control as a critical and challenging benchmark for ANN-to-SNN conversion, where small errors can be strongly amplified and impact performance.
Evaluation on Entity Matching in Recommender Systems
Jan 23, 2026Entity matching is a crucial component in various recommender systems, including conversational recommender systems (CRS) and knowledge-based recommender systems. However, the lack of rigorous evaluation frameworks for cross-dataset entity matching impedes progress in areas such as LLM-driven conversational recommendations and knowledge-grounded dataset construction. In this paper, we introduce Reddit-Amazon-EM, a novel dataset comprising naturally occurring items from Reddit and the Amazon '23 dataset. Through careful manual annotation, we identify corresponding movies across Reddit-Movies and Amazon'23, two existing recommender system datasets with inherently overlapping catalogs. Leveraging Reddit-Amazon-EM, we conduct a comprehensive evaluation of state-of-the-art entity matching methods, including rule-based, graph-based, lexical-based, embedding-based, and LLM-based approaches. For reproducible research, we release our manually annotated entity matching gold set and provide the mapping between the two datasets using the best-performing method from our experiments. This serves as a valuable resource for advancing future work on entity matching in recommender systems.
Data-Efficient Learning of Anomalous Diffusion with Wavelet Representations: Enabling Direct Learning from Experimental Trajectories
Dec 09, 2025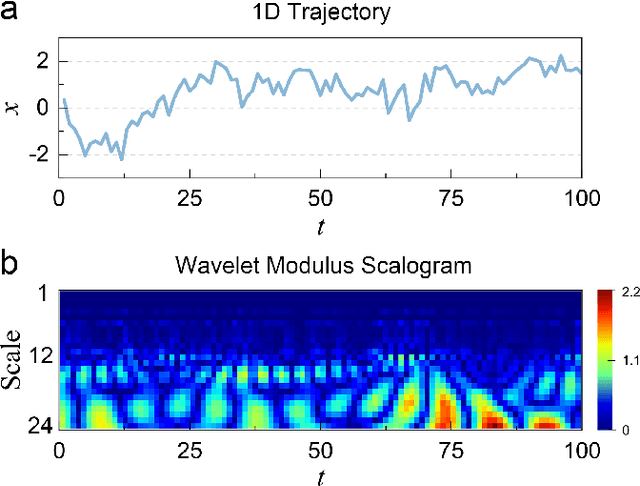
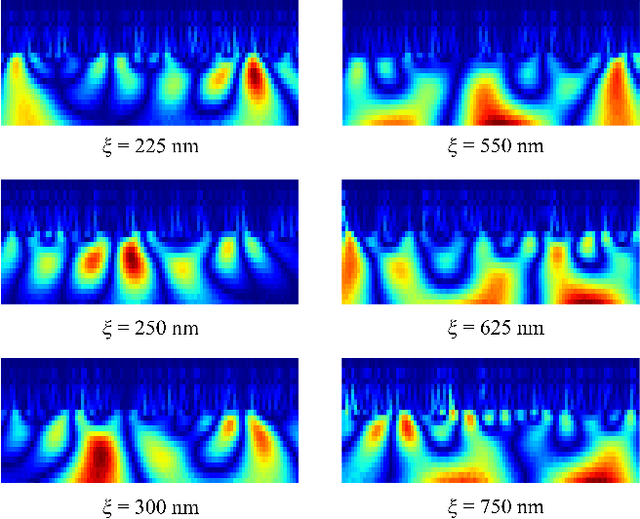
Machine learning (ML) has become a versatile tool for analyzing anomalous diffusion trajectories, yet most existing pipelines are trained on large collections of simulated data. In contrast, experimental trajectories, such as those from single-particle tracking (SPT), are typically scarce and may differ substantially from the idealized models used for simulation, leading to degradation or even breakdown of performance when ML methods are applied to real data. To address this mismatch, we introduce a wavelet-based representation of anomalous diffusion that enables data-efficient learning directly from experimental recordings. This representation is constructed by applying six complementary wavelet families to each trajectory and combining the resulting wavelet modulus scalograms. We first evaluate the wavelet representation on simulated trajectories from the andi-datasets benchmark, where it clearly outperforms both feature-based and trajectory-based methods with as few as 1000 training trajectories and still retains an advantage on large training sets. We then use this representation to learn directly from experimental SPT trajectories of fluorescent beads diffusing in F-actin networks, where the wavelet representation remains superior to existing alternatives for both diffusion-exponent regression and mesh-size classification. In particular, when predicting the diffusion exponents of experimental trajectories, a model trained on 1200 experimental tracks using the wavelet representation achieves significantly lower errors than state-of-the-art deep learning models trained purely on $10^6$ simulated trajectories. We associate this data efficiency with the emergence of distinct scale fingerprints disentangling underlying diffusion mechanisms in the wavelet spectra.
Reinforcement Learning for Active Matter
Mar 30, 2025Active matter refers to systems composed of self-propelled entities that consume energy to produce motion, exhibiting complex non-equilibrium dynamics that challenge traditional models. With the rapid advancements in machine learning, reinforcement learning (RL) has emerged as a promising framework for addressing the complexities of active matter. This review systematically introduces the integration of RL for guiding and controlling active matter systems, focusing on two key aspects: optimal motion strategies for individual active particles and the regulation of collective dynamics in active swarms. We discuss the use of RL to optimize the navigation, foraging, and locomotion strategies for individual active particles. In addition, the application of RL in regulating collective behaviors is also examined, emphasizing its role in facilitating the self-organization and goal-directed control of active swarms. This investigation offers valuable insights into how RL can advance the understanding, manipulation, and control of active matter, paving the way for future developments in fields such as biological systems, robotics, and medical science.
Towards High-performance Spiking Transformers from ANN to SNN Conversion
Feb 28, 2025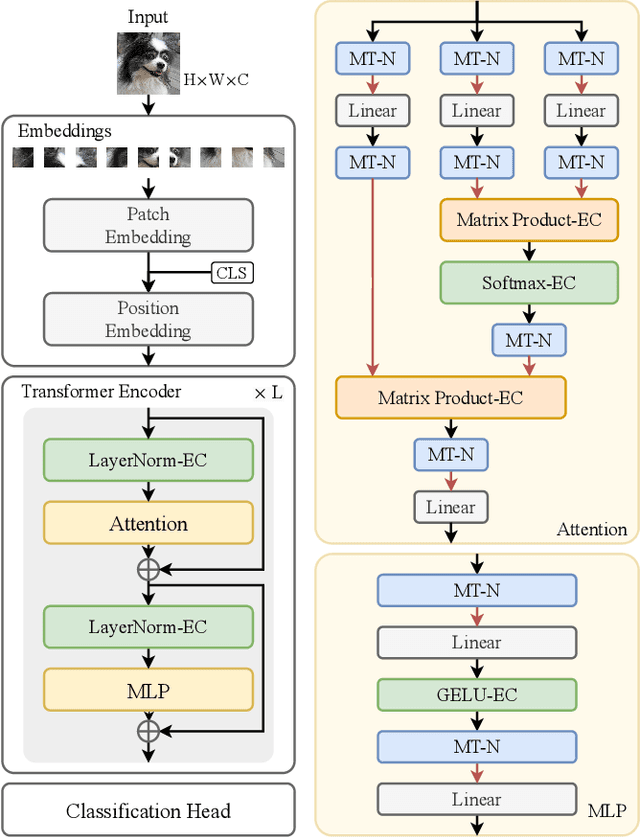
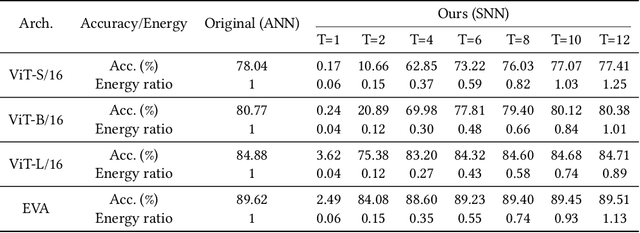
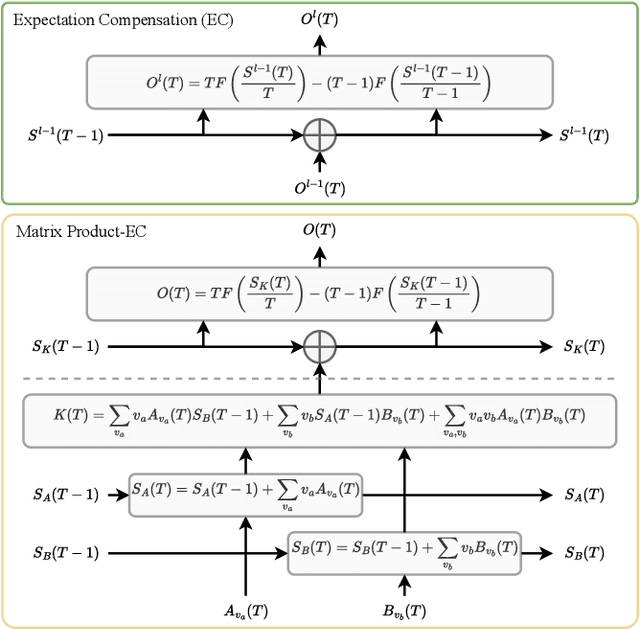
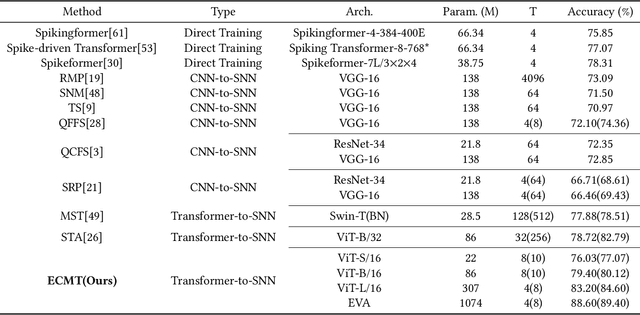
Spiking neural networks (SNNs) show great potential due to their energy efficiency, fast processing capabilities, and robustness. There are two main approaches to constructing SNNs. Direct training methods require much memory, while conversion methods offer a simpler and more efficient option. However, current conversion methods mainly focus on converting convolutional neural networks (CNNs) to SNNs. Converting Transformers to SNN is challenging because of the presence of non-linear modules. In this paper, we propose an Expectation Compensation Module to preserve the accuracy of the conversion. The core idea is to use information from the previous T time-steps to calculate the expected output at time-step T. We also propose a Multi-Threshold Neuron and the corresponding Parallel Parameter normalization to address the challenge of large time steps needed for high accuracy, aiming to reduce network latency and power consumption. Our experimental results demonstrate that our approach achieves state-of-the-art performance. For example, we achieve a top-1 accuracy of 88.60\% with only a 1\% loss in accuracy using 4 time steps while consuming only 35\% of the original power of the Transformer. To our knowledge, this is the first successful Artificial Neural Network (ANN) to SNN conversion for Spiking Transformers that achieves high accuracy, low latency, and low power consumption on complex datasets. The source codes of the proposed method are available at https://github.com/h-z-h-cell/Transformer-to-SNN-ECMT.
Channel-wise Parallelizable Spiking Neuron with Multiplication-free Dynamics and Large Temporal Receptive Fields
Jan 24, 2025Spiking Neural Networks (SNNs) are distinguished from Artificial Neural Networks (ANNs) for their sophisticated neuronal dynamics and sparse binary activations (spikes) inspired by the biological neural system. Traditional neuron models use iterative step-by-step dynamics, resulting in serial computation and slow training speed of SNNs. Recently, parallelizable spiking neuron models have been proposed to fully utilize the massive parallel computing ability of graphics processing units to accelerate the training of SNNs. However, existing parallelizable spiking neuron models involve dense floating operations and can only achieve high long-term dependencies learning ability with a large order at the cost of huge computational and memory costs. To solve the dilemma of performance and costs, we propose the mul-free channel-wise Parallel Spiking Neuron, which is hardware-friendly and suitable for SNNs' resource-restricted application scenarios. The proposed neuron imports the channel-wise convolution to enhance the learning ability, induces the sawtooth dilations to reduce the neuron order, and employs the bit shift operation to avoid multiplications. The algorithm for design and implementation of acceleration methods is discussed meticulously. Our methods are validated in neuromorphic Spiking Heidelberg Digits voices, sequential CIFAR images, and neuromorphic DVS-Lip vision datasets, achieving the best accuracy among SNNs. Training speed results demonstrate the effectiveness of our acceleration methods, providing a practical reference for future research.