 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Controllability-Fidelity Frontier in Diffusion Editing
Jun 05, 2026Diffusion-based generative models enable powerful image editing capabilities, but achieving precise control while maintaining fidelity and safety remains challenging. We present a comprehensive theoretical and empirical study of controllable diffusion-based image editing, analyzing the trade-offs between adherence to user intent, preservation of non-target content, and output quality. Our work spans text- and mask-guided edits, point/drag manipulation, and inversion-based pipelines. We derive mathematical formulations of editing objectives and analyze dynamics of noise injection, score guidance, and inversion error. We provide theoretical bounds on reconstruction error, stability under repeated edits, and locality of changes. We propose algorithmic frameworks (with pseudocode) for mask-localized and instruction-guided editing, and present extensive experiments comparing state-of-the-art methods (e.g.\ TF-ICON \cite{lu2023tficone}, DragFlow \cite{zhou2025dragflow}, InstructPix2Pix \cite{brooks2023instructpix2pix}, UltraEdit \cite{zhao2024ultraedit}) on multiple tasks and metrics (FID, identity similarity, CLIP alignment, artifact scores, etc). Our results reveal key failure modes, such as identity drift, prompt sensitivity, and compositional errors. We also discuss ethical considerations in image editing, including misuse risks, bias, consent, and concept erasure techniques (e.g.\ MACE \cite{lu2024mace}, ANT \cite{li2025ant}, EraseAnything \cite{gao2024eraseanything}) as safeguards. We conclude with best practices and future directions for responsible, high-fidelity diffusion-based editing.
Position: How can Graphs Help Large Language Models?
May 04, 2026With the rapid advancement of large language models (LLMs), classic graph learning tasks have greatly benefited from LLMs, including improved encoding of textual features, more efficient construction of graphs from text, and enhanced reasoning over knowledge graphs. In this paper, we ask a complementary question: How can graphs help LLMs? We address this question from three perspectives: 1) graphs provide an up-to-date knowledge source that helps reduce LLM hallucinations, 2) graph-based prompting techniques-such as Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT)-enhance LLM reasoning capabilities, and 3) integrating graphs into LLMs improves their understanding of structured data, expanding their applicability to domains such as e-commerce, code, and relational databases (RDBs). We further outlook some future directions including designing sparse LLM architectures based on graphs and brain-inspired memory systems.
SoccerRef-Agents: Multi-Agent System for Automated Soccer Refereeing
Apr 25, 2026Refereeing is vital in sports, where fair, accurate, and explainable decisions are fundamental. While intelligent assistant technologies are being widely adopted in soccer refereeing, current AI-assisted approaches remain preliminary. Existing research mostly focuses on isolated video perception tasks and lacks the ability to understand and reason about foul scenarios. To fill this gap, we propose SoccerRef-Agents, a holistic and explainable multi-agent decision-making framework for soccer refereeing. The main contributions are: (i) constructing the multimodal benchmark SoccerRefBench with over 1,200 referee theory questions and 600 foul video clips; (ii) building a vector-based knowledge base RefKnowledgeDB using the latest "Laws of the Game" and a classic case database for precise, knowledge-driven reasoning; (iii) designing a novel multi-agent architecture that collaborates via cross-modal RAG to bridge the semantic gap between visual content and regulatory texts. This work explores the technical capability of integrating MLLMs with refereeing expertise, and evaluations show our system significantly outperforms general-purpose MLLMs in decision accuracy and explanation quality. All databases, benchmarks, and code will be made available.
FODMP: Fast One-Step Diffusion of Movement Primitives Generation for Time-Dependent Robot Actions
Mar 25, 2026Diffusion models are increasingly used for robot learning, but current designs face a clear trade-off. Action-chunking diffusion policies like ManiCM are fast to run, yet they only predict short segments of motion. This makes them reactive, but unable to capture time-dependent motion primitives, such as following a spring-damper-like behavior with built-in dynamic profiles of acceleration and deceleration. Recently, Movement Primitive Diffusion (MPD) partially addresses this limitation by parameterizing full trajectories using Probabilistic Dynamic Movement Primitives (ProDMPs), thereby enabling the generation of temporally structured motions. Nevertheless, MPD integrates the motion decoder directly into a multi-step diffusion process, resulting in prohibitively high inference latency that limits its applicability in real-time control settings. We propose FODMP (Fast One-step Diffusion of Movement Primitives), a new framework that distills diffusion models into the ProDMPs trajectory parameter space and generates motion using a single-step decoder. FODMP retains the temporal structure of movement primitives while eliminating the inference bottleneck through single-step consistency distillation. This enables robots to execute time-dependent primitives at high inference speed, suitable for closed-loop vision-based control. On standard manipulation benchmarks (MetaWorld, ManiSkill), FODMP runs up to 10 times faster than MPD and 7 times faster than action-chunking diffusion policies, while matching or exceeding their success rates. Beyond speed, by generating fast acceleration-deceleration motion primitives, FODMP allows the robot to intercept and securely catch a fast-flying ball, whereas action-chunking diffusion policy and MPD respond too slowly for real-time interception.
HVR-Met: A Hypothesis-Verification-Replaning Agentic System for Extreme Weather Diagnosis
Mar 01, 2026While deep learning-based weather forecasting paradigms have made significant strides, addressing extreme weather diagnostics remains a formidable challenge. This gap exists primarily because the diagnostic process demands sophisticated multi-step logical reasoning, dynamic tool invocation, and expert-level prior judgment. Although agents possess inherent advantages in task decomposition and autonomous execution, current architectures are still hampered by critical bottlenecks: inadequate expert knowledge integration, a lack of professional-grade iterative reasoning loops, and the absence of fine-grained validation and evaluation systems for complex workflows under extreme conditions. To this end, we propose HVR-Met, a multi-agent meteorological diagnostic system characterized by the deep integration of expert knowledge. Its central innovation is the ``Hypothesis-Verification-Replanning'' closed-loop mechanism, which facilitates sophisticated iterative reasoning for anomalous meteorological signals during extreme weather events. To bridge gaps within existing evaluation frameworks, we further introduce a novel benchmark focused on atomic-level subtasks. Experimental evidence demonstrates that the system excels in complex diagnostic scenarios.
A Large-Scale Dataset for Molecular Structure-Language Description via a Rule-Regularized Method
Feb 02, 2026Molecular function is largely determined by structure. Accurately aligning molecular structure with natural language is therefore essential for enabling large language models (LLMs) to reason about downstream chemical tasks. However, the substantial cost of human annotation makes it infeasible to construct large-scale, high-quality datasets of structure-grounded descriptions. In this work, we propose a fully automated annotation framework for generating precise molecular structure descriptions at scale. Our approach builds upon and extends a rule-based chemical nomenclature parser to interpret IUPAC names and construct enriched, structured XML metadata that explicitly encodes molecular structure. This metadata is then used to guide LLMs in producing accurate natural-language descriptions. Using this framework, we curate a large-scale dataset of approximately $163$k molecule-description pairs. A rigorous validation protocol combining LLM-based and expert human evaluation on a subset of $2,000$ molecules demonstrates a high description precision of $98.6\%$. The resulting dataset provides a reliable foundation for future molecule-language alignment, and the proposed annotation method is readily extensible to larger datasets and broader chemical tasks that rely on structural descriptions.
Proof-RM: A Scalable and Generalizable Reward Model for Math Proof
Feb 02, 2026While Large Language Models (LLMs) have demonstrated strong math reasoning abilities through Reinforcement Learning with *Verifiable Rewards* (RLVR), many advanced mathematical problems are proof-based, with no guaranteed way to determine the authenticity of a proof by simple answer matching. To enable automatic verification, a Reward Model (RM) capable of reliably evaluating full proof processes is required. In this work, we design a *scalable* data-construction pipeline that, with minimal human effort, leverages LLMs to generate a large quantity of high-quality "**question-proof-check**" triplet data. By systematically varying problem sources, generation methods, and model configurations, we create diverse problem-proof pairs spanning multiple difficulty levels, linguistic styles, and error types, subsequently filtered through hierarchical human review for label alignment. Utilizing these data, we train a proof-checking RM, incorporating additional process reward and token weight balance to stabilize the RL process. Our experiments validate the model's scalability and strong performance from multiple perspectives, including reward accuracy, generalization ability and test-time guidance, providing important practical recipes and tools for strengthening LLM mathematical capabilities.
SubTokenTest: A Practical Benchmark for Real-World Sub-token Understanding
Jan 14, 2026Recent advancements in large language models (LLMs) have significantly enhanced their reasoning capabilities. However, they continue to struggle with basic character-level tasks, such as counting letters in words, a problem rooted in their tokenization process. While existing benchmarks have highlighted this weakness through basic character operations, such failures are often dismissed due to lacking practical relevance. Yet, many real-world applications, such as navigating text-based maps or interpreting structured tables, rely heavily on precise sub-token understanding. In this regard, we introduce SubTokenTest, a comprehensive benchmark that assesses sub-token understanding through practical, utility-driven tasks. Our benchmark includes ten tasks across four domains and isolates tokenization-related failures by decoupling performance from complex reasoning. We provide a comprehensive evaluation of nine advanced LLMs. Additionally, we investigate the impact of test-time scaling on sub-token reasoning and explore how character-level information is encoded within the hidden states.
RecGPT-V2 Technical Report
Dec 16, 2025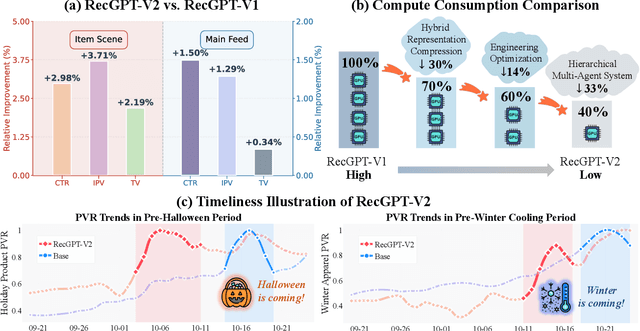
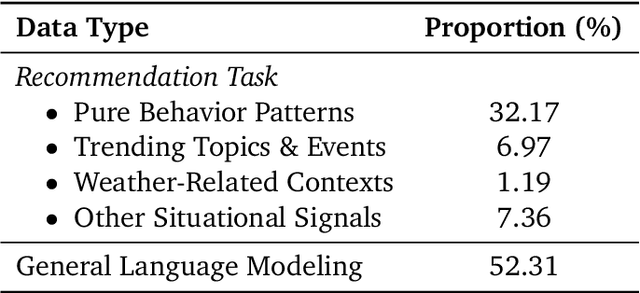
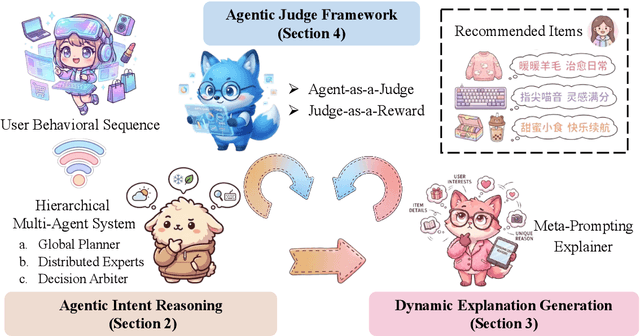

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
What Affects the Effective Depth of Large Language Models?
Dec 16, 2025



The scaling of large language models (LLMs) emphasizes increasing depth, yet performance gains diminish with added layers. Prior work introduces the concept of "effective depth", arguing that deeper models fail to fully utilize their layers for meaningful computation. Building on this, we systematically study how effective depth varies with model scale, training type, and task difficulty. First, we analyze the model behavior of Qwen-2.5 family (1.5B-32B) and find that while the number of effective layers grows with model size, the effective depth ratio remains stable. Besides, comparisons between base and corresponding long-CoT models show no increase in effective depth, suggesting that improved reasoning stems from longer context rather than deeper per-token computation. Furthermore, evaluations across tasks of varying difficulty indicate that models do not dynamically use more layers for harder problems. Our results suggest that current LLMs underuse available depth across scales, training paradigms and tasks of varying difficulties, pointing out research opportunities on increasing the layer utilization rate of LLMs, model pruning, and early exiting. Our code is released at https://github.com/AheadOFpotato/what_affects_effective_depth.