 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartArena: Benchmarking Chart Parsing across Languages, Scenarios, and Formats
May 31, 2026Charts are a primary medium for conveying quantitative and relational information, yet systematically evaluating chart parsing models remains difficult. Existing benchmarks focus on narrow chart types and leave diagrammatic structures such as flowcharts and mind maps largely unaddressed, while models produce outputs in incompatible formats, and datasets rarely include the printed or hand-drawn images encountered in practice. To address these issues, we introduce ChartArena, a comprehensive bilingual benchmark covering eight chart families spanning both numeric charts and diagrammatic structures, each evaluated across three visual scenarios: digital renderings, printed photos, and hand-drawn photos. The dataset is built via a human-agent collaborative annotation pipeline with multi-stage human verification to ensure annotation reliability. To enable fair cross-model comparison, we further design a format-agnostic evaluation protocol that maps heterogeneous outputs into two canonical semantic spaces, a normalized triple view and a directed graph view, and scores them with structure-aware metrics. Through extensive evaluation of 26 leading MLLMs, we observe three consistent findings: (i) frontier proprietary models such as Gemini 3.1 Pro lead overall, yet the strongest open-source systems are rapidly closing the gap; (ii) document parsing models handle numeric charts reasonably but fall sharply behind on diagrammatic structures; and (iii) expert chart parsers remain limited to narrow chart families. Across all models, radar charts and hand-drawn scenarios stay especially challenging. These findings show that ChartArena exposes clear capability gaps and provides a unified foundation for future progress. ChartArena is publicly available at https://github.com/pspdada/ChartArena.
PhoneWorld: Scaling Phone-Use Agent Environments
May 28, 2026A central bottleneck for phone-use agents is that controllable, reproducible environments covering real mobile behavior are hard to build at scale. Existing mobile-agent benchmarks have made important progress on evaluation, but they do not by themselves provide a scalable way to construct many new phone-use environments. We present PhoneWorld, a reusable pipeline that converts real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, automatic verifiers, and training rollouts. Rather than hand-building one mobile benchmark at a time, PhoneWorld uses real trajectories to recover which screens matter, how screens connect, which interactions must change environment state, and which user goals admit automatic verification. From these signals, it builds runnable mock Android apps backed by read-only app content and mutable state, then derives executable tasks, rule-based verifiers, and training rollouts from the same environments. In its current instantiation, PhoneWorld covers 34 apps across 16 domains, spanning common consumer mobile behaviors such as search, browsing, shopping, booking, media, and social interaction. Under a fixed training budget, replacing 10K steps from an auxiliary AndroidWorld corpus in an AndroidWorld-based baseline with broad PhoneWorld supervision improves all four evaluation benchmarks at once, raising HYMobileBench by 17.7 points, AndroidControl by 6.0 points, AndroidWorld by 14.7 points, and PhoneWorld by 52.5 points. We then study two additional scaling questions: increasing the amount of PhoneWorld supervision strongly improves PhoneWorld performance, and under a fixed PhoneWorld budget, expanding app coverage yields even larger gains. Overall, PhoneWorld shifts the focus from building one mobile benchmark at a time to scaling the supply of phone-use environments themselves.
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
May 05, 2026On-policy distillation (OPD) has recently emerged as an effective post-training paradigm for consolidating the capabilities of specialized expert models into a single student model. Despite its empirical success, the conditions under which OPD yields reliable improvement remain poorly understood. In this work, we identify two fundamental bottlenecks that limit effective OPD: insufficient exploration of informative states and unreliable teacher supervision for student rollouts. Building on this insight, we propose Uni-OPD, a unified OPD framework that generalizes across Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), centered on a dual-perspective optimization strategy. Specifically, from the student's perspective, we adopt two data balancing strategies to promote exploration of informative student-generated states during training. From the teacher's perspective, we show that reliable supervision hinges on whether aggregated token-level guidance remains order-consistent with the outcome reward. To this end, we develop an outcome-guided margin calibration mechanism to restore order consistency between correct and incorrect trajectories. We conduct extensive experiments on 5 domains and 16 benchmarks covering diverse settings, including single-teacher and multi-teacher distillation across LLMs and MLLMs, strong-to-weak distillation, and cross-modal distillation. Our results verify the effectiveness and versatility of Uni-OPD and provide practical insights into reliable OPD.
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Apr 28, 2026Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $π_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $π_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
Ego-InBetween: Generating Object State Transitions in Ego-Centric Videos
Apr 20, 2026Understanding physical transformation processes is crucial for both human cognition and artificial intelligence systems, particularly from an egocentric perspective, which serves as a key bridge between humans and machines in action modeling. We define this modeling process as Egocentric Instructed Visual State Transition (EIVST), which involves generating intermediate frames that depict object transformations between initial and target states under a brief action instruction. EIVST poses two challenges for current generative models: (1) understanding the visual scenes of the initial and target states and reasoning about transformation steps from an egocentric view, and (2) generating a consistent intermediate transition that follows the given instruction while preserving object appearance across the two visual states. To address these challenges, we propose the EgoIn framework. It first infers the multi-step transition process between two given states using TransitionVLM, fine-tuned on our curated dataset to better adapt to this task and reduce hallucinated information. It then generates a sequence of frames based on transition conditions produced by the proposed Transition Conditioning module. Additionally, we introduce Object-aware Auxiliary Supervision to preserve consistent object appearance throughout the transition. Extensive experiments on human-object and robot-object interaction datasets demonstrate EgoIn's superior performance in generating semantically meaningful and visually coherent transformation sequences.
Enhancing MLLM Spatial Understanding via Active 3D Scene Exploration for Multi-Perspective Reasoning
Apr 08, 2026Although Multimodal Large Language Models have achieved remarkable progress, they still struggle with complex 3D spatial reasoning due to the reliance on 2D visual priors. Existing approaches typically mitigate this limitation either through computationally expensive post-training procedures on limited 3D datasets or through rigid tool-calling mechanisms that lack explicit geometric understanding and viewpoint flexibility. To address these challenges, we propose a \textit{training-free} framework that introduces a Visual Chain-of-Thought mechanism grounded in explicit 3D reconstruction. The proposed pipeline first reconstructs a high-fidelity 3D mesh from a single image using MLLM-guided keyword extraction and mask generation at multiple granularities. Subsequently, the framework leverages an external knowledge base to iteratively compute optimal camera extrinsic parameters and synthesize novel views, thereby emulating human perspective-taking. Extensive experiments demonstrate that the proposed approach significantly enhances spatial comprehension. Specifically, the framework outperforms specialized spatial models and general-purpose MLLMs, including \textit{GPT-5.2} and \textit{Gemini-2.5-Flash}, on major benchmarks such as 3DSRBench and Rel3D.
VideoTIR: Accurate Understanding for Long Videos with Efficient Tool-Integrated Reasoning
Mar 26, 2026Existing Multimodal Large Language Models (MLLMs) often suffer from hallucinations in long video understanding (LVU), primarily due to the imbalance between textual and visual tokens. Observing that MLLMs handle short visual inputs well, recent LVU works alleviate hallucinations by automatically parsing the vast visual data into manageable segments that can be effectively processed by MLLMs. SFT-based tool-calling methods can serve this purpose, but they typically require vast amounts of fine-grained, high-quality data and suffer from constrained tool-calling trajectories. We propose a novel VideoTIR that leverages Reinforcement Learning (RL) to encourage proper usage of comprehensive multi-level toolkits for efficient long video understanding. VideoTIR explores both Zero-RL and SFT cold-starting to enable MLLMs to retrieve and focus on meaningful video segments/images/regions, enhancing long video understanding both accurately and efficiently. To reduce redundant tool-calling, we propose Toolkit Action Grouped Policy Optimization (TAGPO), which enhances the efficiency of the calling process through stepwise reward assignment and reuse of failed rollouts. Additionally, we develop a sandbox-based trajectory synthesis framework to generate high-quality trajectories data. Extensive experiments on three long-video QA benchmarks demonstrate the effectiveness and efficiency of our method.
MMTIT-Bench: A Multilingual and Multi-Scenario Benchmark with Cognition-Perception-Reasoning Guided Text-Image Machine Translation
Mar 25, 2026End-to-end text-image machine translation (TIMT), which directly translates textual content in images across languages, is crucial for real-world multilingual scene understanding. Despite advances in vision-language large models (VLLMs), robustness across diverse visual scenes and low-resource languages remains underexplored due to limited evaluation resources. We present MMTIT-Bench, a human-verified multilingual and multi-scenario benchmark with 1,400 images spanning fourteen non-English and non-Chinese languages and diverse settings such as documents, scenes, and web images, enabling rigorous assessment of end-to-end TIMT. Beyond benchmarking, we study how reasoning-oriented data design improves translation. Although recent VLLMs have begun to incorporate long Chain-of-Thought (CoT) reasoning, effective thinking paradigms for TIMT are still immature: existing designs either cascade parsing and translation in a sequential manner or focus on language-only reasoning, overlooking the visual cognition central to VLLMs. We propose Cognition-Perception-Reasoning for Translation (CPR-Trans), a data paradigm that integrates scene cognition, text perception, and translation reasoning within a unified reasoning process. Using a VLLM-driven data generation pipeline, CPR-Trans provides structured, interpretable supervision that aligns perception with reasoning. Experiments on 3B and 7B models show consistent gains in accuracy and interpretability. We will release MMTIT-Bench to promote the multilingual and multi-scenario TIMT research upon acceptance.
Towards Real-World Document Parsing via Realistic Scene Synthesis and Document-Aware Training
Mar 25, 2026Document parsing has recently advanced with multimodal large language models (MLLMs) that directly map document images to structured outputs. Traditional cascaded pipelines depend on precise layout analysis and often fail under casually captured or non-standard conditions. Although end-to-end approaches mitigate this dependency, they still exhibit repetitive, hallucinated, and structurally inconsistent predictions - primarily due to the scarcity of large-scale, high-quality full-page (document-level) end-to-end parsing data and the lack of structure-aware training strategies. To address these challenges, we propose a data-training co-design framework for robust end-to-end document parsing. A Realistic Scene Synthesis strategy constructs large-scale, structurally diverse full-page end-to-end supervision by composing layout templates with rich document elements, while a Document-Aware Training Recipe introduces progressive learning and structure-token optimization to enhance structural fidelity and decoding stability. We further build Wild-OmniDocBench, a benchmark derived from real-world captured documents for robustness evaluation. Integrated into a 1B-parameter MLLM, our method achieves superior accuracy and robustness across both scanned/digital and real-world captured scenarios. All models, data synthesis pipelines, and benchmarks will be publicly released to advance future research in document understanding.
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
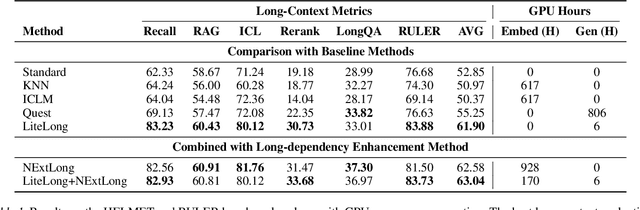


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.