 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Scalable Terminal Task Synthesis via Skill Graphs
Apr 28, 2026Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution trajectories that agents actually experience during training. In this paper, we present SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. SkillSynth first constructs a large-scale skill graph, where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth. Moreover, task instances synthesized by SkillSynth have been adopted to train Hy3 Preview, contributing to its enhanced agentic capabilities in terminal-based settings.
WRAP++: Web discoveRy Amplified Pretraining
Apr 09, 2026Synthetic data rephrasing has emerged as a powerful technique for enhancing knowledge acquisition during large language model (LLM) pretraining. However, existing approaches operate at the single-document level, rewriting individual web pages in isolation. This confines synthesized examples to intra-document knowledge, missing cross-document relationships and leaving facts with limited associative context. We propose WRAP++ (Web discoveRy Amplified Pretraining), which amplifies the associative context of factual knowledge by discovering cross-document relationships from web hyperlinks and synthesizing joint QA over each discovered document pair. Concretely, WRAP++ discovers high-confidence relational motifs including dual-links and co-mentions, and synthesizes QA that requires reasoning across both documents. This produces relational knowledge absent from either source document alone, creating diverse entry points to the same facts. Because the number of valid entity pairs grows combinatorially, this discovery-driven synthesis also amplifies data scale far beyond single-document rewriting. Instantiating WRAP++ on Wikipedia, we amplify ~8.4B tokens of raw text into 80B tokens of cross-document QA data. On SimpleQA, OLMo-based models at both 7B and 32B scales trained with WRAP++ substantially outperform single-document approaches and exhibit sustained scaling gains, underscoring the advantage of cross-document knowledge discovery and amplification.
TOOLCAD: Exploring Tool-Using Large Language Models in Text-to-CAD Generation with Reinforcement Learning
Apr 09, 2026Computer-Aided Design (CAD) is an expert-level task that relies on long-horizon reasoning and coherent modeling actions. Large Language Models (LLMs) have shown remarkable advancements in enabling language agents to tackle real-world tasks. Notably, there has been no investigation into how tool-using LLMs optimally interact with CAD engines, hindering the emergence of LLM-based agentic text-to-CAD modeling systems. We propose ToolCAD, a novel agentic CAD framework deploying LLMs as tool-using agents for text-to-CAD generation. Furthermore, we introduce an interactive CAD modeling gym to rollout reasoning and tool-augmented interaction trajectories with the CAD engine, incorporating hybrid feedback and human supervision. Meanwhile, an end-to-end post-training strategy is presented to enable the LLM agent to elicit refined CAD Modeling Chain of Thought (CAD-CoT) and evolve into proficient CAD tool-using agents via online curriculum reinforcement learning. Our findings demonstrate ToolCAD fills the gap in adopting and training open-source LLMs for CAD tool-using agents, enabling them to perform comparably to proprietary models, paving the way for more accessible and robust autonomous text-to-CAD modeling systems.
PolicyLong: Towards On-Policy Context Extension
Apr 09, 2026Extending LLM context windows is hindered by scarce high-quality long-context data. Recent methods synthesize data with genuine long-range dependencies via information-theoretic verification, selecting contexts that reduce a base model's predictive entropy. However, their single-pass offline construction with a fixed model creates a fundamental off-policy gap: the static screening landscape misaligns with the model's evolving capabilities, causing the training distribution to drift. We propose PolicyLong, shifting data construction towards a dynamic on-policy paradigm. By iteratively re-executing data screening (entropy computation, retrieval, and verification) using the current model, PolicyLong ensures the training distribution tracks evolving capabilities, yielding an emergent self-curriculum. Crucially, both positive and hard negative contexts derive from the current model's entropy landscape, co-evolving what the model learns to exploit and resist. Experiments on RULER, HELMET, and LongBench-v2 (Qwen2.5-3B) show PolicyLong consistently outperforms EntropyLong and NExtLong, with gains growing at longer contexts (e.g., +2.54 at 128K on RULER), confirming the value of on-policy data evolution.
TSPO: Breaking the Double Homogenization Dilemma in Multi-turn Search Policy Optimization
Jan 30, 2026Multi-turn tool-integrated reasoning enables Large Language Models (LLMs) to solve complex tasks through iterative information retrieval. However, current reinforcement learning (RL) frameworks for search-augmented reasoning predominantly rely on sparse outcome-level rewards, leading to a "Double Homogenization Dilemma." This manifests as (1) Process homogenization, where the thinking, reasoning, and tooling involved in generation are ignored. (2) Intra-group homogenization, coarse-grained outcome rewards often lead to inefficiencies in intra-group advantage estimation with methods like Group Relative Policy Optimization (GRPO) during sampling. To address this, we propose Turn-level Stage-aware Policy Optimization (TSPO). TSPO introduces the First-Occurrence Latent Reward (FOLR) mechanism, allocating partial rewards to the step where the ground-truth answer first appears, thereby preserving process-level signals and increasing reward variance within groups without requiring external reward models or any annotations. Extensive experiments demonstrate that TSPO significantly outperforms state-of-the-art baselines, achieving average performance gains of 24% and 13.6% on Qwen2.5-3B and 7B models, respectively.
LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
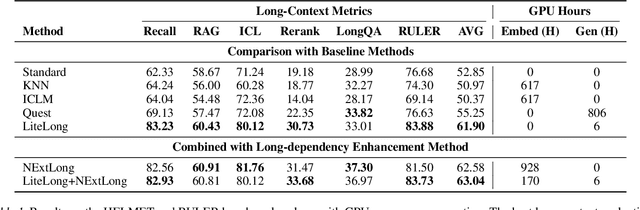


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Aug 17, 2025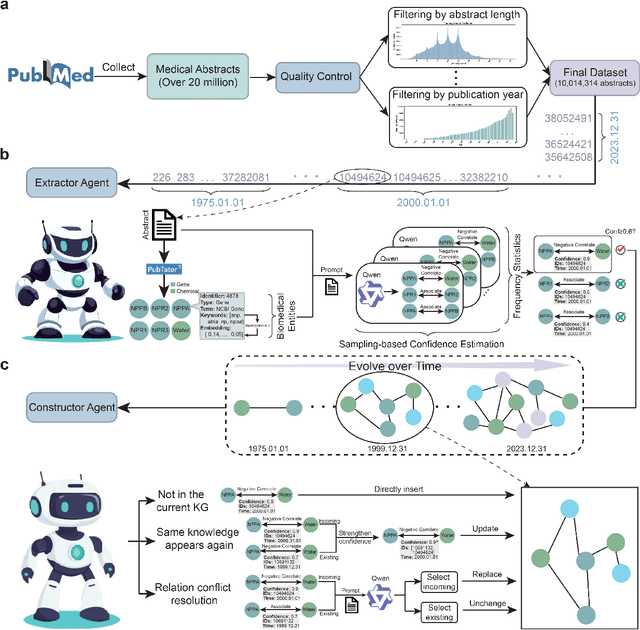
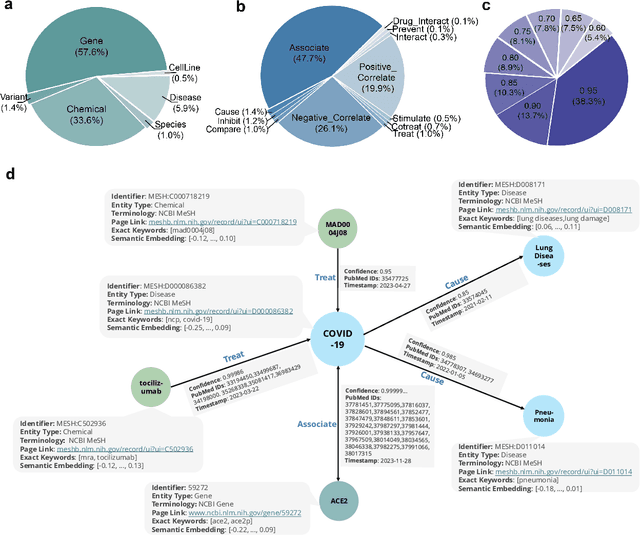
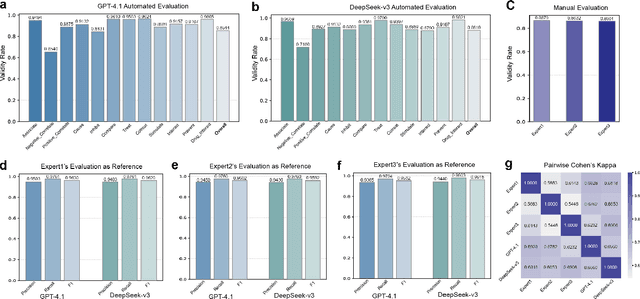
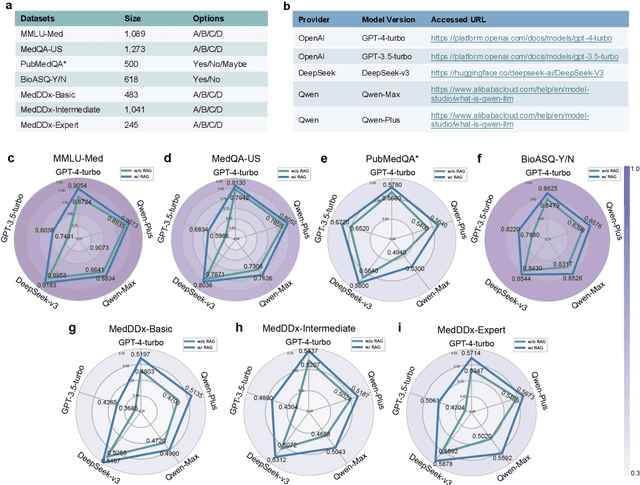
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90\%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG's value in literature-based drug repurposing via confidence-aware causal inference.
Libra: Large Chinese-based Safeguard for AI Content
Jul 29, 2025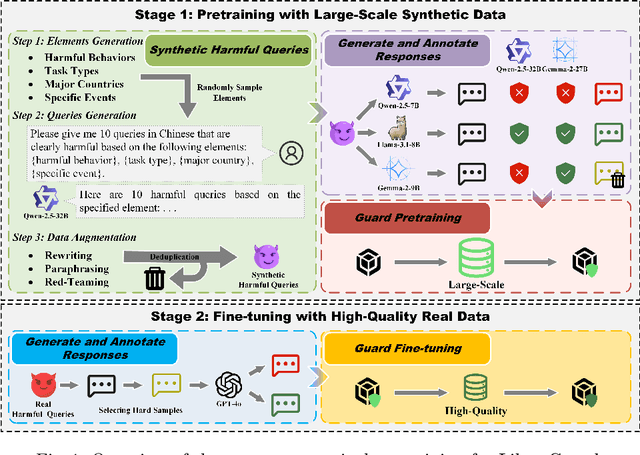
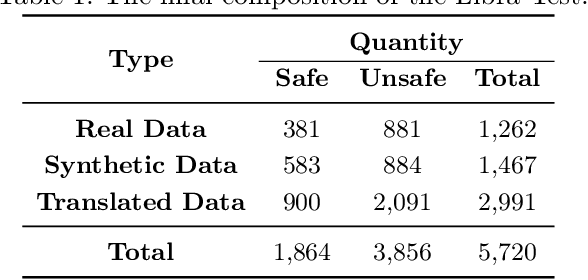
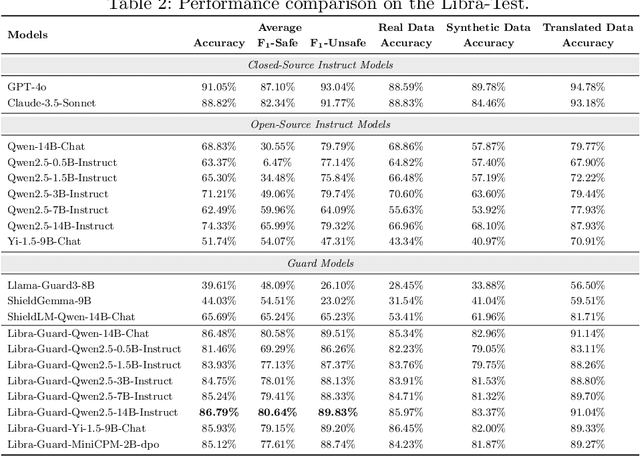
Large language models (LLMs) excel in text understanding and generation but raise significant safety and ethical concerns in high-stakes applications. To mitigate these risks, we present Libra-Guard, a cutting-edge safeguard system designed to enhance the safety of Chinese-based LLMs. Leveraging a two-stage curriculum training pipeline, Libra-Guard enhances data efficiency by employing guard pretraining on synthetic samples, followed by fine-tuning on high-quality, real-world data, thereby significantly reducing reliance on manual annotations. To enable rigorous safety evaluations, we also introduce Libra-Test, the first benchmark specifically designed to evaluate the effectiveness of safeguard systems for Chinese content. It covers seven critical harm scenarios and includes over 5,700 samples annotated by domain experts. Experiments show that Libra-Guard achieves 86.79% accuracy, outperforming Qwen2.5-14B-Instruct (74.33%) and ShieldLM-Qwen-14B-Chat (65.69%), and nearing closed-source models like Claude-3.5-Sonnet and GPT-4o. These contributions establish a robust framework for advancing the safety governance of Chinese LLMs and represent a tentative step toward developing safer, more reliable Chinese AI systems.
Omni-DPO: A Dual-Perspective Paradigm for Dynamic Preference Learning of LLMs
Jun 11, 2025Direct Preference Optimization (DPO) has become a cornerstone of reinforcement learning from human feedback (RLHF) due to its simplicity and efficiency. However, existing DPO-based approaches typically treat all preference pairs uniformly, ignoring critical variations in their inherent quality and learning utility, leading to suboptimal data utilization and performance. To address this challenge, we propose Omni-DPO, a dual-perspective optimization framework that jointly accounts for (1) the inherent quality of each preference pair and (2) the model's evolving performance on those pairs. By adaptively weighting samples according to both data quality and the model's learning dynamics during training, Omni-DPO enables more effective training data utilization and achieves better performance. Experimental results on various models and benchmarks demonstrate the superiority and generalization capabilities of Omni-DPO. On textual understanding tasks, Gemma-2-9b-it finetuned with Omni-DPO beats the leading LLM, Claude 3 Opus, by a significant margin of 6.7 points on the Arena-Hard benchmark. On mathematical reasoning tasks, Omni-DPO consistently outperforms the baseline methods across all benchmarks, providing strong empirical evidence for the effectiveness and robustness of our approach. Code and models will be available at https://github.com/pspdada/Omni-DPO.