 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
Paper and Code
Aug 20, 2024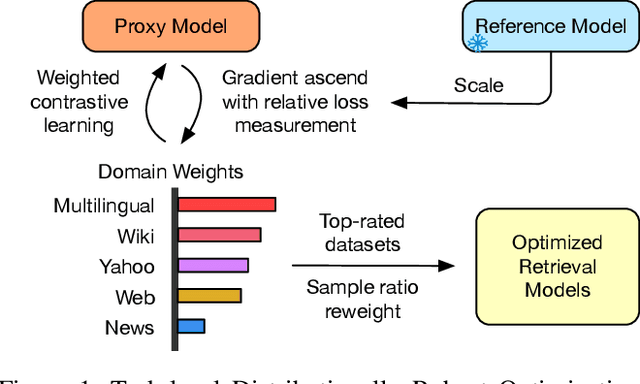

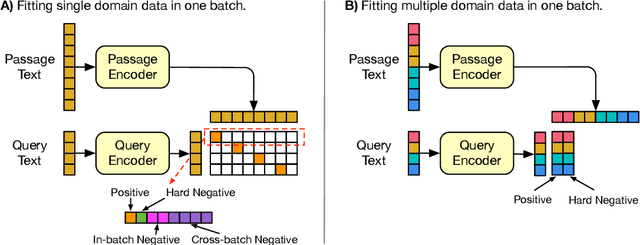
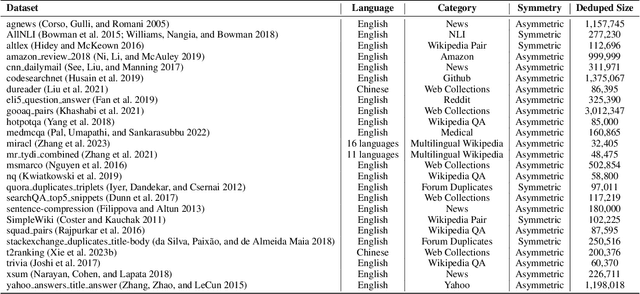
Large Language Model-based Dense Retrieval (LLM-DR) optimizes over numerous heterogeneous fine-tuning collections from different domains. However, the discussion about its training data distribution is still minimal. Previous studies rely on empirically assigned dataset choices or sampling ratios, which inevitably leads to sub-optimal retrieval performances. In this paper, we propose a new task-level Distributionally Robust Optimization (tDRO) algorithm for LLM-DR fine-tuning, targeted at improving the universal domain generalization ability by end-to-end reweighting the data distribution of each task. The tDRO parameterizes the domain weights and updates them with scaled domain gradients. The optimized weights are then transferred to the LLM-DR fine-tuning to train more robust retrievers. Experiments show optimal improvements in large-scale retrieval benchmarks and reduce up to 30% dataset usage after applying our optimization algorithm with a series of different-sized LLM-DR models.