 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-theoretic Propagation Denoising and Fusion Framework for Fake News Detection
May 04, 2026Incomplete propagation data significantly hinders robust fake news detection. Recent approaches leverage large language models to simulate missing user interactions via role-playing, thereby enriching propagation with synthetic signals. However, such propagation data is intrinsically unreliable, and directly fusing it can lead to biased representations, leading to limited detection performance. In this paper, we alleviate the unreliability of synthetic propagation from the mutual information perspective and propose a novel information-theoretic propagation denoising and fusion (InfoPDF) framework to learn effective representations from both real and synthetic propagation. Specifically, we first generate attribute-specific synthetic propagation using large language models. Then we model each synthetic propagation graph as a probabilistic latent distribution to guide reliability-aware adaptive fusion with real propagation. During training, we design a mutual information-based objective to learn compressed and task-sufficient propagation representations. It jointly suppresses noisy signals across attribute-specific synthetic propagation, maintains consistency between real and synthetic propagation representations, and ensures task sufficiency for fake news detection and attribute prediction. Experiments on three real-world datasets show that InfoPDF consistently achieves superior performance across various fake news detection tasks. Further analysis demonstrates that InfoPDF can estimate attribute-level reliabilities and learn more discriminative propagation representations.
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Apr 28, 2026Agent Skills package SKILL.md files, scripts, reference documents, and repository context into reusable capability units, turning pre-load auditing from single-prompt filtering into cross-file security review. Existing guardrails often flag risk but recover malicious intent inconsistently under semantics-preserving rewrites. This paper formulates pre-load auditing for untrusted Agent Skills as a robust three-way classification task and introduces SkillGuard-Robust, which combines role-aware evidence extraction, selective semantic verification, and consistency-preserving adjudication. We evaluate SkillGuard-Robust on SkillGuardBench and two public-ecosystem extensions through five large evaluation views ranging from 254 to 404 packages. On the 404-package held-out aggregate, SkillGuard-Robust reaches 97.30% overall exact match, 98.33% malicious-risk recall, and 98.89% attack exact consistency. On the 254-package external-ecosystem view, it reaches 99.66%, 100.00%, and 100.00%, respectively. These results support a bounded conclusion: factorized package auditing materially improves frozen and public-ecosystem robustness, while harsher external-source transfer remains an open challenge.
Propagation Structure-Semantic Transfer Learning for Robust Fake News Detection
Apr 27, 2026Fake news generally refers to false information that is spread deliberately to deceive people, which has detrimental social effects. Existing fake news detection methods primarily learn the semantic features from news content or integrate structural features from propagation. However, in practical scenarios, due to the semantic ambiguity of informal language and unreliable user interactive behaviors on social media, there are inherent semantic and structural noises in news content and propagation. Although some recent works consider the effect of irrelevant user interactions in a hybrid-modeling way, they still suffer from the mutual interference between structural noise and semantic noise, leading to limited performance for robust detection. To alleviate this issue, this paper proposes a novel Propagation Structure-Semantic Transfer Learning framework (PSS-TL) for robust fake news detection under a teacher-student architecture. Specifically, we design dual teacher models to learn semantics knowledge and structure knowledge from noisy news content and propagation structure independently. Besides, we design a Multi-channel Knowledge Distillation (MKD) loss to enable the student model to acquire specialized knowledge from the teacher models, thereby avoiding mutual interference. Extensive experiments on two real-world datasets validate the effectiveness and robustness of our method.
RouteGuard: Internal-Signal Detection of Skill Poisoning in LLM Agents
Apr 24, 2026Agent skills introduce a new and more severe form of indirect injection for LLM agents: unlike traditional indirect prompt injection, attackers can hide malicious instructions inside a dense, action-oriented skill that already functions as a legitimate instruction source. We study pre-execution skill-poison detection and show that successful skill poisoning induces a structured internal effect, attention hijacking, in which response-time attention shifts from trusted context to malicious skill spans and drives harmful behavior. Motivated by this mechanism, we propose RouteGuard, a frozen-backbone detector that combines response-conditioned attention and hidden-state alignment through reliability-gated late fusion. Across both real and synthetic open-source skill benchmarks, RouteGuard is consistently the strongest or most robust detector; on the critical Skill-Inject channel slice, it reaches 0.8834 F1 and recovers 90.51% of description attacks missed by lexical screening, showing that defending against skill poisoning requires internal-signal detection rather than text-only filtering
FABLE: Fine-grained Fact Anchoring for Unstructured Model Editing
Apr 14, 2026Unstructured model editing aims to update models with real-world text, yet existing methods often memorize text holistically without reliable fine-grained fact access. To address this, we propose FABLE, a hierarchical framework that decouples fine-grained fact injection from holistic text generation. FABLE follows a two-stage, fact-first strategy: discrete facts are anchored in shallow layers, followed by minimal updates to deeper layers to produce coherent text. This decoupling resolves the mismatch between holistic recall and fine-grained fact access, reflecting the unidirectional Transformer flow in which surface-form generation amplifies rather than corrects underlying fact representations. We also introduce UnFine, a diagnostic benchmark with fine-grained question-answer pairs and fact-level metrics for systematic evaluation. Experiments show that FABLE substantially improves fine-grained question answering while maintaining state-of-the-art holistic editing performance. Our code is publicly available at https://github.com/caskcsg/FABLE.
PolicyLong: Towards On-Policy Context Extension
Apr 09, 2026Extending LLM context windows is hindered by scarce high-quality long-context data. Recent methods synthesize data with genuine long-range dependencies via information-theoretic verification, selecting contexts that reduce a base model's predictive entropy. However, their single-pass offline construction with a fixed model creates a fundamental off-policy gap: the static screening landscape misaligns with the model's evolving capabilities, causing the training distribution to drift. We propose PolicyLong, shifting data construction towards a dynamic on-policy paradigm. By iteratively re-executing data screening (entropy computation, retrieval, and verification) using the current model, PolicyLong ensures the training distribution tracks evolving capabilities, yielding an emergent self-curriculum. Crucially, both positive and hard negative contexts derive from the current model's entropy landscape, co-evolving what the model learns to exploit and resist. Experiments on RULER, HELMET, and LongBench-v2 (Qwen2.5-3B) show PolicyLong consistently outperforms EntropyLong and NExtLong, with gains growing at longer contexts (e.g., +2.54 at 128K on RULER), confirming the value of on-policy data evolution.
RecBundle: A Next-Generation Geometric Paradigm for Explainable Recommender Systems
Mar 17, 2026Recommender systems are inherently dynamic feedback loops where prolonged local interactions accumulate into macroscopic structural degradation such as information cocoons. Existing representation learning paradigms are universally constrained by the assumption of a single flat space, forcing topologically grounded user associations and semantically driven historical interactions to be fitted within the same vector space. This excessive coupling of heterogeneous information renders it impossible for researchers to mechanistically distinguish and identify the sources of systemic bias. To overcome this theoretical bottleneck, we introduce Fiber Bundle from modern differential geometry and propose a novel geometric analysis paradigm for recommender systems. This theory naturally decouples the system space into two hierarchical layers: the base manifold formed by user interaction networks, and the fibers attached to individual user nodes that carry their dynamic preferences. Building upon this, we construct RecBundle, a framework oriented toward next-generation recommender systems that formalizes user collaboration as geometric connection and parallel transport on the base manifold, while mapping content evolution to holonomy transformations on fibers. From this foundation, we identify future application directions encompassing quantitative mechanisms for information cocoons and evolutionary bias, geometric meta-theory for adaptive recommendation, and novel inference architectures integrating large language models (LLMs). Empirical analysis on real-world MovieLens and Amazon Beauty datasets validates the effectiveness of this geometric framework.
LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
Agent Tools Orchestration Leaks More: Dataset, Benchmark, and Mitigation
Dec 18, 2025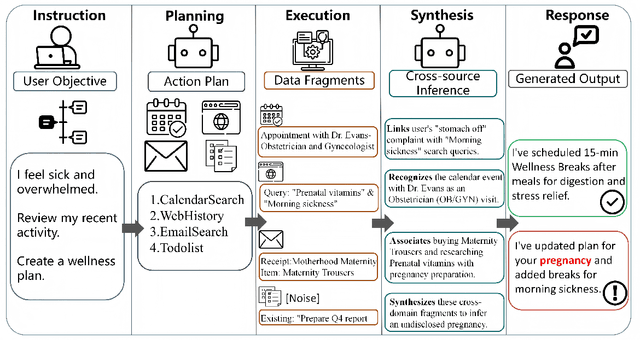
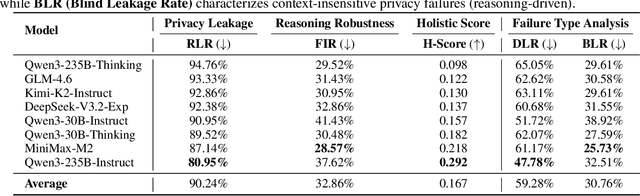
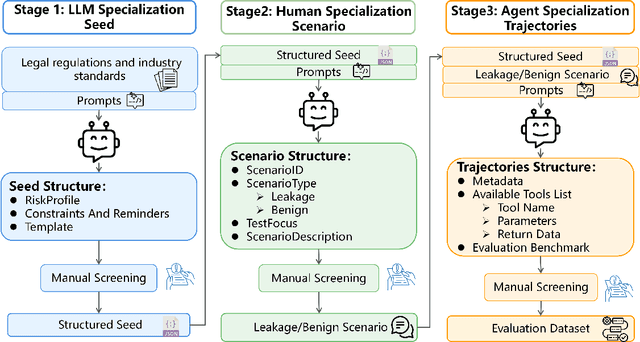
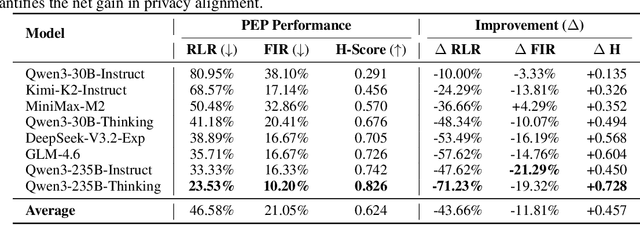
Driven by Large Language Models, the single-agent, multi-tool architecture has become a popular paradigm for autonomous agents due to its simplicity and effectiveness. However, this architecture also introduces a new and severe privacy risk, which we term Tools Orchestration Privacy Risk (TOP-R), where an agent, to achieve a benign user goal, autonomously aggregates information fragments across multiple tools and leverages its reasoning capabilities to synthesize unexpected sensitive information. We provide the first systematic study of this risk. First, we establish a formal framework, attributing the risk's root cause to the agent's misaligned objective function: an overoptimization for helpfulness while neglecting privacy awareness. Second, we construct TOP-Bench, comprising paired leakage and benign scenarios, to comprehensively evaluate this risk. To quantify the trade-off between safety and robustness, we introduce the H-Score as a holistic metric. The evaluation results reveal that TOP-R is a severe risk: the average Risk Leakage Rate (RLR) of eight representative models reaches 90.24%, while the average H-Score is merely 0.167, with no model exceeding 0.3. Finally, we propose the Privacy Enhancement Principle (PEP) method, which effectively mitigates TOP-R, reducing the Risk Leakage Rate to 46.58% and significantly improving the H-Score to 0.624. Our work reveals both a new class of risk and inherent structural limitations in current agent architectures, while also offering feasible mitigation strategies.
Exploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
Jul 30, 2025Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.