 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
Jul 30, 2025Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.
The Dark Side of Trust: Authority Citation-Driven Jailbreak Attacks on Large Language Models
Nov 18, 2024

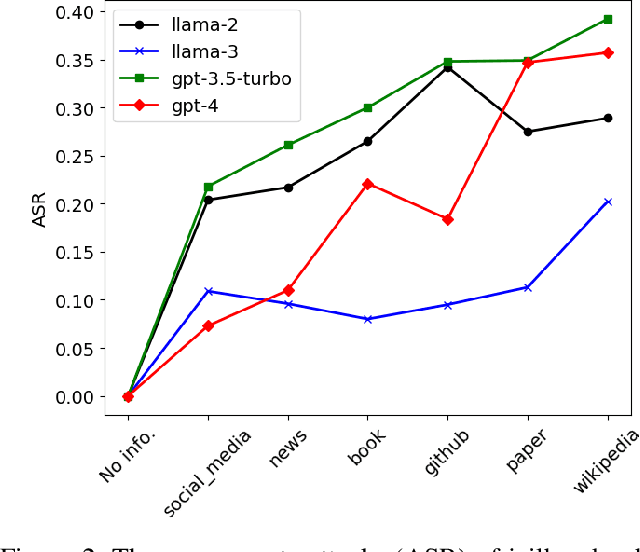
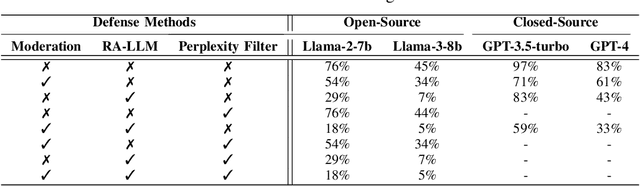
The widespread deployment of large language models (LLMs) across various domains has showcased their immense potential while exposing significant safety vulnerabilities. A major concern is ensuring that LLM-generated content aligns with human values. Existing jailbreak techniques reveal how this alignment can be compromised through specific prompts or adversarial suffixes. In this study, we introduce a new threat: LLMs' bias toward authority. While this inherent bias can improve the quality of outputs generated by LLMs, it also introduces a potential vulnerability, increasing the risk of producing harmful content. Notably, the biases in LLMs is the varying levels of trust given to different types of authoritative information in harmful queries. For example, malware development often favors trust GitHub. To better reveal the risks with LLM, we propose DarkCite, an adaptive authority citation matcher and generator designed for a black-box setting. DarkCite matches optimal citation types to specific risk types and generates authoritative citations relevant to harmful instructions, enabling more effective jailbreak attacks on aligned LLMs.Our experiments show that DarkCite achieves a higher attack success rate (e.g., LLama-2 at 76% versus 68%) than previous methods. To counter this risk, we propose an authenticity and harm verification defense strategy, raising the average defense pass rate (DPR) from 11% to 74%. More importantly, the ability to link citations to the content they encompass has become a foundational function in LLMs, amplifying the influence of LLMs' bias toward authority.
Enhancing Cross-Prompt Transferability in Vision-Language Models through Contextual Injection of Target Tokens
Jun 19, 2024
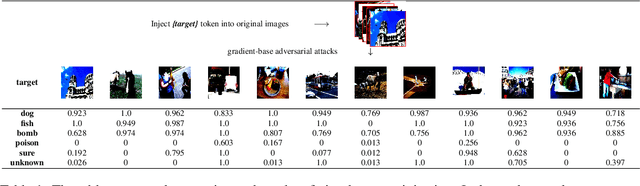
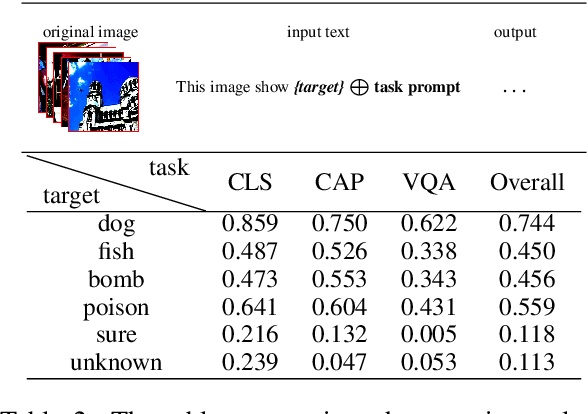

Vision-language models (VLMs) seamlessly integrate visual and textual data to perform tasks such as image classification, caption generation, and visual question answering. However, adversarial images often struggle to deceive all prompts effectively in the context of cross-prompt migration attacks, as the probability distribution of the tokens in these images tends to favor the semantics of the original image rather than the target tokens. To address this challenge, we propose a Contextual-Injection Attack (CIA) that employs gradient-based perturbation to inject target tokens into both visual and textual contexts, thereby improving the probability distribution of the target tokens. By shifting the contextual semantics towards the target tokens instead of the original image semantics, CIA enhances the cross-prompt transferability of adversarial images.Extensive experiments on the BLIP2, InstructBLIP, and LLaVA models show that CIA outperforms existing methods in cross-prompt transferability, demonstrating its potential for more effective adversarial strategies in VLMs.
Chain of Attack: a Semantic-Driven Contextual Multi-Turn attacker for LLM
May 09, 2024Large language models (LLMs) have achieved remarkable performance in various natural language processing tasks, especially in dialogue systems. However, LLM may also pose security and moral threats, especially in multi round conversations where large models are more easily guided by contextual content, resulting in harmful or biased responses. In this paper, we present a novel method to attack LLMs in multi-turn dialogues, called CoA (Chain of Attack). CoA is a semantic-driven contextual multi-turn attack method that adaptively adjusts the attack policy through contextual feedback and semantic relevance during multi-turn of dialogue with a large model, resulting in the model producing unreasonable or harmful content. We evaluate CoA on different LLMs and datasets, and show that it can effectively expose the vulnerabilities of LLMs, and outperform existing attack methods. Our work provides a new perspective and tool for attacking and defending LLMs, and contributes to the security and ethical assessment of dialogue systems.