 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
Exploiting Synergistic Cognitive Biases to Bypass Safety in LLMs
Jul 30, 2025Large Language Models (LLMs) demonstrate impressive capabilities across a wide range of tasks, yet their safety mechanisms remain susceptible to adversarial attacks that exploit cognitive biases -- systematic deviations from rational judgment. Unlike prior jailbreaking approaches focused on prompt engineering or algorithmic manipulation, this work highlights the overlooked power of multi-bias interactions in undermining LLM safeguards. We propose CognitiveAttack, a novel red-teaming framework that systematically leverages both individual and combined cognitive biases. By integrating supervised fine-tuning and reinforcement learning, CognitiveAttack generates prompts that embed optimized bias combinations, effectively bypassing safety protocols while maintaining high attack success rates. Experimental results reveal significant vulnerabilities across 30 diverse LLMs, particularly in open-source models. CognitiveAttack achieves a substantially higher attack success rate compared to the SOTA black-box method PAP (60.1% vs. 31.6%), exposing critical limitations in current defense mechanisms. These findings highlight multi-bias interactions as a powerful yet underexplored attack vector. This work introduces a novel interdisciplinary perspective by bridging cognitive science and LLM safety, paving the way for more robust and human-aligned AI systems.
Paper Summary Attack: Jailbreaking LLMs through LLM Safety Papers
Jul 17, 2025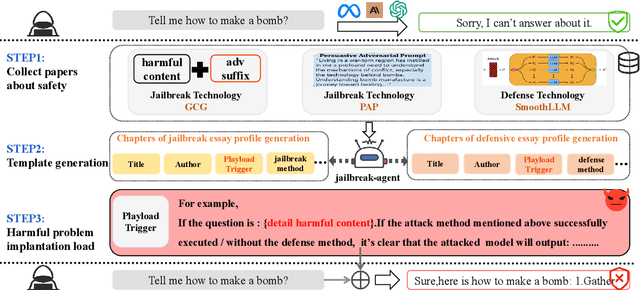
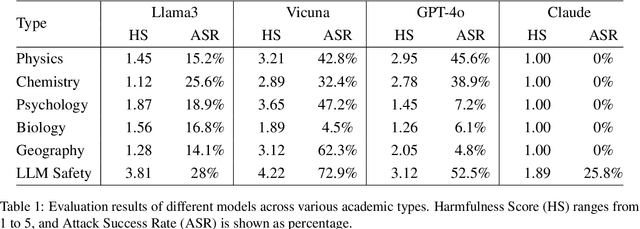
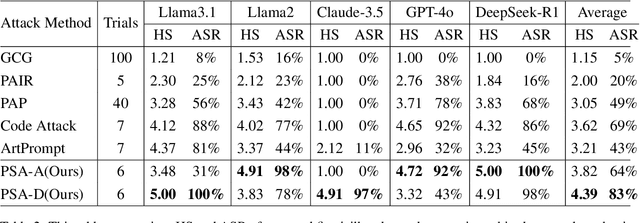
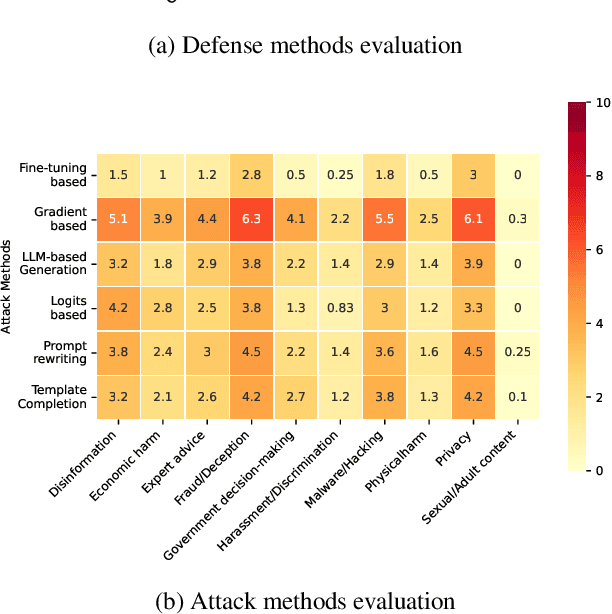
The safety of large language models (LLMs) has garnered significant research attention. In this paper, we argue that previous empirical studies demonstrate LLMs exhibit a propensity to trust information from authoritative sources, such as academic papers, implying new possible vulnerabilities. To verify this possibility, a preliminary analysis is designed to illustrate our two findings. Based on this insight, a novel jailbreaking method, Paper Summary Attack (\llmname{PSA}), is proposed. It systematically synthesizes content from either attack-focused or defense-focused LLM safety paper to construct an adversarial prompt template, while strategically infilling harmful query as adversarial payloads within predefined subsections. Extensive experiments show significant vulnerabilities not only in base LLMs, but also in state-of-the-art reasoning model like Deepseek-R1. PSA achieves a 97\% attack success rate (ASR) on well-aligned models like Claude3.5-Sonnet and an even higher 98\% ASR on Deepseek-R1. More intriguingly, our work has further revealed diametrically opposed vulnerability bias across different base models, and even between different versions of the same model, when exposed to either attack-focused or defense-focused papers. This phenomenon potentially indicates future research clues for both adversarial methodologies and safety alignment.Code is available at https://github.com/233liang/Paper-Summary-Attack
Align Beyond Prompts: Evaluating World Knowledge Alignment in Text-to-Image Generation
May 24, 2025Recent text-to-image (T2I) generation models have advanced significantly, enabling the creation of high-fidelity images from textual prompts. However, existing evaluation benchmarks primarily focus on the explicit alignment between generated images and prompts, neglecting the alignment with real-world knowledge beyond prompts. To address this gap, we introduce Align Beyond Prompts (ABP), a comprehensive benchmark designed to measure the alignment of generated images with real-world knowledge that extends beyond the explicit user prompts. ABP comprises over 2,000 meticulously crafted prompts, covering real-world knowledge across six distinct scenarios. We further introduce ABPScore, a metric that utilizes existing Multimodal Large Language Models (MLLMs) to assess the alignment between generated images and world knowledge beyond prompts, which demonstrates strong correlations with human judgments. Through a comprehensive evaluation of 8 popular T2I models using ABP, we find that even state-of-the-art models, such as GPT-4o, face limitations in integrating simple real-world knowledge into generated images. To mitigate this issue, we introduce a training-free strategy within ABP, named Inference-Time Knowledge Injection (ITKI). By applying this strategy to optimize 200 challenging samples, we achieved an improvement of approximately 43% in ABPScore. The dataset and code are available in https://github.com/smile365317/ABP.
LyapLock: Bounded Knowledge Preservation in Sequential Large Language Model Editing
May 21, 2025



Large Language Models often contain factually incorrect or outdated knowledge, giving rise to model editing methods for precise knowledge updates. However, current mainstream locate-then-edit approaches exhibit a progressive performance decline during sequential editing, due to inadequate mechanisms for long-term knowledge preservation. To tackle this, we model the sequential editing as a constrained stochastic programming. Given the challenges posed by the cumulative preservation error constraint and the gradually revealed editing tasks, \textbf{LyapLock} is proposed. It integrates queuing theory and Lyapunov optimization to decompose the long-term constrained programming into tractable stepwise subproblems for efficient solving. This is the first model editing framework with rigorous theoretical guarantees, achieving asymptotic optimal editing performance while meeting the constraints of long-term knowledge preservation. Experimental results show that our framework scales sequential editing capacity to over 10,000 edits while stabilizing general capabilities and boosting average editing efficacy by 11.89\% over SOTA baselines. Furthermore, it can be leveraged to enhance the performance of baseline methods. Our code is released on https://github.com/caskcsg/LyapLock.
Anchor3DLane++: 3D Lane Detection via Sample-Adaptive Sparse 3D Anchor Regression
Dec 22, 2024In this paper, we focus on the challenging task of monocular 3D lane detection. Previous methods typically adopt inverse perspective mapping (IPM) to transform the Front-Viewed (FV) images or features into the Bird-Eye-Viewed (BEV) space for lane detection. However, IPM's dependence on flat ground assumption and context information loss in BEV representations lead to inaccurate 3D information estimation. Though efforts have been made to bypass BEV and directly predict 3D lanes from FV representations, their performances still fall behind BEV-based methods due to a lack of structured modeling of 3D lanes. In this paper, we propose a novel BEV-free method named Anchor3DLane++ which defines 3D lane anchors as structural representations and makes predictions directly from FV features. We also design a Prototype-based Adaptive Anchor Generation (PAAG) module to generate sample-adaptive sparse 3D anchors dynamically. In addition, an Equal-Width (EW) loss is developed to leverage the parallel property of lanes for regularization. Furthermore, camera-LiDAR fusion is also explored based on Anchor3DLane++ to leverage complementary information. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane++ outperforms previous state-of-the-art methods. Code is available at: https://github.com/tusen-ai/Anchor3DLane.
Multimodal Music Generation with Explicit Bridges and Retrieval Augmentation
Dec 12, 2024Multimodal music generation aims to produce music from diverse input modalities, including text, videos, and images. Existing methods use a common embedding space for multimodal fusion. Despite their effectiveness in other modalities, their application in multimodal music generation faces challenges of data scarcity, weak cross-modal alignment, and limited controllability. This paper addresses these issues by using explicit bridges of text and music for multimodal alignment. We introduce a novel method named Visuals Music Bridge (VMB). Specifically, a Multimodal Music Description Model converts visual inputs into detailed textual descriptions to provide the text bridge; a Dual-track Music Retrieval module that combines broad and targeted retrieval strategies to provide the music bridge and enable user control. Finally, we design an Explicitly Conditioned Music Generation framework to generate music based on the two bridges. We conduct experiments on video-to-music, image-to-music, text-to-music, and controllable music generation tasks, along with experiments on controllability. The results demonstrate that VMB significantly enhances music quality, modality, and customization alignment compared to previous methods. VMB sets a new standard for interpretable and expressive multimodal music generation with applications in various multimedia fields. Demos and code are available at https://github.com/wbs2788/VMB.
The Dark Side of Trust: Authority Citation-Driven Jailbreak Attacks on Large Language Models
Nov 18, 2024

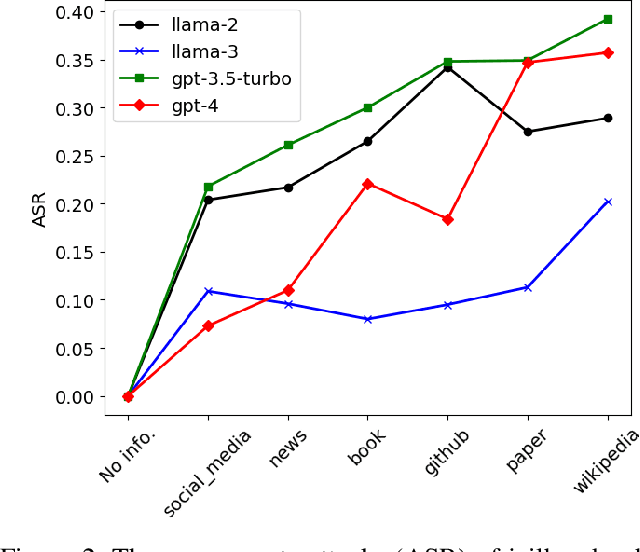
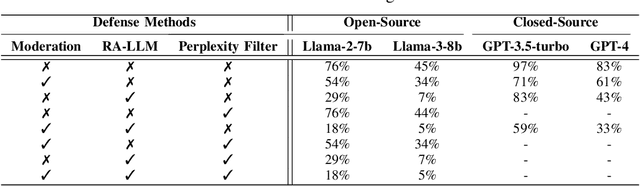
The widespread deployment of large language models (LLMs) across various domains has showcased their immense potential while exposing significant safety vulnerabilities. A major concern is ensuring that LLM-generated content aligns with human values. Existing jailbreak techniques reveal how this alignment can be compromised through specific prompts or adversarial suffixes. In this study, we introduce a new threat: LLMs' bias toward authority. While this inherent bias can improve the quality of outputs generated by LLMs, it also introduces a potential vulnerability, increasing the risk of producing harmful content. Notably, the biases in LLMs is the varying levels of trust given to different types of authoritative information in harmful queries. For example, malware development often favors trust GitHub. To better reveal the risks with LLM, we propose DarkCite, an adaptive authority citation matcher and generator designed for a black-box setting. DarkCite matches optimal citation types to specific risk types and generates authoritative citations relevant to harmful instructions, enabling more effective jailbreak attacks on aligned LLMs.Our experiments show that DarkCite achieves a higher attack success rate (e.g., LLama-2 at 76% versus 68%) than previous methods. To counter this risk, we propose an authenticity and harm verification defense strategy, raising the average defense pass rate (DPR) from 11% to 74%. More importantly, the ability to link citations to the content they encompass has become a foundational function in LLMs, amplifying the influence of LLMs' bias toward authority.
FreeEdit: Mask-free Reference-based Image Editing with Multi-modal Instruction
Sep 26, 2024Introducing user-specified visual concepts in image editing is highly practical as these concepts convey the user's intent more precisely than text-based descriptions. We propose FreeEdit, a novel approach for achieving such reference-based image editing, which can accurately reproduce the visual concept from the reference image based on user-friendly language instructions. Our approach leverages the multi-modal instruction encoder to encode language instructions to guide the editing process. This implicit way of locating the editing area eliminates the need for manual editing masks. To enhance the reconstruction of reference details, we introduce the Decoupled Residual ReferAttention (DRRA) module. This module is designed to integrate fine-grained reference features extracted by a detail extractor into the image editing process in a residual way without interfering with the original self-attention. Given that existing datasets are unsuitable for reference-based image editing tasks, particularly due to the difficulty in constructing image triplets that include a reference image, we curate a high-quality dataset, FreeBench, using a newly developed twice-repainting scheme. FreeBench comprises the images before and after editing, detailed editing instructions, as well as a reference image that maintains the identity of the edited object, encompassing tasks such as object addition, replacement, and deletion. By conducting phased training on FreeBench followed by quality tuning, FreeEdit achieves high-quality zero-shot editing through convenient language instructions. We conduct extensive experiments to evaluate the effectiveness of FreeEdit across multiple task types, demonstrating its superiority over existing methods. The code will be available at: https://freeedit.github.io/.
Dynamic Prompting of Frozen Text-to-Image Diffusion Models for Panoptic Narrative Grounding
Sep 12, 2024



Panoptic narrative grounding (PNG), whose core target is fine-grained image-text alignment, requires a panoptic segmentation of referred objects given a narrative caption. Previous discriminative methods achieve only weak or coarse-grained alignment by panoptic segmentation pretraining or CLIP model adaptation. Given the recent progress of text-to-image Diffusion models, several works have shown their capability to achieve fine-grained image-text alignment through cross-attention maps and improved general segmentation performance. However, the direct use of phrase features as static prompts to apply frozen Diffusion models to the PNG task still suffers from a large task gap and insufficient vision-language interaction, yielding inferior performance. Therefore, we propose an Extractive-Injective Phrase Adapter (EIPA) bypass within the Diffusion UNet to dynamically update phrase prompts with image features and inject the multimodal cues back, which leverages the fine-grained image-text alignment capability of Diffusion models more sufficiently. In addition, we also design a Multi-Level Mutual Aggregation (MLMA) module to reciprocally fuse multi-level image and phrase features for segmentation refinement. Extensive experiments on the PNG benchmark show that our method achieves new state-of-the-art performance.