 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFlow: Hierarchical Task-State Alignment for Long-Horizon Embodied Agents
May 19, 2026Long-horizon embodied agents increasingly delegate navigation, search, approach, and manipulation to specialist executors. As these executors become stronger, the main bottleneck shifts from local skill execution to maintaining a coherent task frontier across planning, monitoring, memory, and execution. We study task-state misalignment, a task-level consistency failure in which the planner's active stage, runtime evidence, remembered context, and delegated executor no longer justify the same next-step decision. This failure can lead to unsupported handoffs, stage lock, executor-context mismatch, and unnecessary replanning. We propose ContextFlow, an inspectable alignment framework that represents stages as explicit contracts, converts runtime observations into evidence packets, and applies scoped updates including continue, refine, transfer, promote, and repair. ContextFlow keeps specialist executors responsible for local closed-loop control while making task-frontier alignment explicit and auditable. Experiments and demonstration traces on long-horizon embodied tasks illustrate how evidence-grounded scoped updates diagnose and mitigate recurring task-state failures.
Monocular Depth Estimation From the Perspective of Feature Restoration: A Diffusion Enhanced Depth Restoration Approach
Apr 09, 2026Monocular Depth Estimation (MDE) is a fundamental computer vision task with important applications in 3D vision. The current mainstream MDE methods employ an encoder-decoder architecture with multi-level/scale feature processing. However, the limitations of the current architecture and the effects of different-level features on the prediction accuracy are not evaluated. In this paper, we first investigate the above problem and show that there is still substantial potential in the current framework if encoder features can be improved. Therefore, we propose to formulate the depth estimation problem from the feature restoration perspective, by treating pretrained encoder features as degraded features of an assumed ground truth feature that yields the ground truth depth map. Then an Invertible Transform-enhanced Indirect Diffusion (InvT-IndDiffusion) module is developed for feature restoration. Due to the absence of direct supervision on feature, only indirect supervision from the final sparse depth map is used. During the iterative procedure of diffusion, this results in feature deviations among steps. The proposed InvT-IndDiffusion solves this problem by using an invertible transform-based decoder under the bi-Lipschitz condition. Finally, a plug-and-play Auxiliary Viewpoint-based Low-level Feature Enhancement module (AV-LFE) is developed to enhance local details with auxiliary viewpoint when available. Experiments demonstrate that the proposed method achieves better performance than the state-of-the-art methods on various datasets. Specifically on the KITTI benchmark, compared with the baseline, the performance is improved by 4.09% and 37.77% under different training settings in terms of RMSE. Code is available at https://github.com/whitehb1/IID-RDepth.
Adaptive Depth-converted-Scale Convolution for Self-supervised Monocular Depth Estimation
Apr 09, 2026Self-supervised monocular depth estimation (MDE) has received increasing interests in the last few years. The objects in the scene, including the object size and relationship among different objects, are the main clues to extract the scene structure. However, previous works lack the explicit handling of the changing sizes of the object due to the change of its depth. Especially in a monocular video, the size of the same object is continuously changed, resulting in size and depth ambiguity. To address this problem, we propose a Depth-converted-Scale Convolution (DcSConv) enhanced monocular depth estimation framework, by incorporating the prior relationship between the object depth and object scale to extract features from appropriate scales of the convolution receptive field. The proposed DcSConv focuses on the adaptive scale of the convolution filter instead of the local deformation of its shape. It establishes that the scale of the convolution filter matters no less (or even more in the evaluated task) than its local deformation. Moreover, a Depth-converted-Scale aware Fusion (DcS-F) is developed to adaptively fuse the DcSConv features and the conventional convolution features. Our DcSConv enhanced monocular depth estimation framework can be applied on top of existing CNN based methods as a plug-and-play module to enhance the conventional convolution block. Extensive experiments with different baselines have been conducted on the KITTI benchmark and our method achieves the best results with an improvement up to 11.6% in terms of SqRel reduction. Ablation study also validates the effectiveness of each proposed module.
CWRNN-INVR: A Coupled WarpRNN based Implicit Neural Video Representation
Apr 08, 2026Implicit Neural Video Representation (INVR) has emerged as a novel approach for video representation and compression, using learnable grids and neural networks. Existing methods focus on developing new grid structures efficient for latent representation and neural network architectures with large representation capability, lacking the study on their roles in video representation. In this paper, the difference between INVR based on neural network and INVR based on grid is first investigated from the perspective of video information composition to specify their own advantages, i.e., neural network for general structure while grid for specific detail. Accordingly, an INVR based on mixed neural network and residual grid framework is proposed, where the neural network is used to represent the regular and structured information and the residual grid is used to represent the remaining irregular information in a video. A Coupled WarpRNN-based multi-scale motion representation and compensation module is specifically designed to explicitly represent the regular and structured information, thus terming our method as CWRNN-INVR. For the irregular information, a mixed residual grid is learned where the irregular appearance and motion information are represented together. The mixed residual grid can be combined with the coupled WarpRNN in a way that allows for network reuse. Experiments show that our method achieves the best reconstruction results compared with the existing methods, with an average PSNR of 33.73 dB on the UVG dataset under the 3M model and outperforms existing INVR methods in other downstream tasks. The code can be found at https://github.com/yiyang-sdu/CWRNN-INVR.git}{https://github.com/yiyang-sdu/CWRNN-INVR.git.
ChainRec: An Agentic Recommender Learning to Route Tool Chains for Diverse and Evolving Interests
Feb 11, 2026Large language models (LLMs) are increasingly integrated into recommender systems, motivating recent interest in agentic and reasoning-based recommendation. However, most existing approaches still rely on fixed workflows, applying the same reasoning procedure across diverse recommendation scenarios. In practice, user contexts vary substantially-for example, in cold-start settings or during interest shifts, so an agent should adaptively decide what evidence to gather next rather than following a scripted process. To address this, we propose ChainRec, an agentic recommender that uses a planner to dynamically select reasoning tools. ChainRec builds a standardized Tool Agent Library from expert trajectories. It then trains a planner using supervised fine-tuning and preference optimization to dynamically select tools, decide their order, and determine when to stop. Experiments on AgentRecBench across Amazon, Yelp, and Goodreads show that ChainRec consistently improves Avg HR@{1,3,5} over strong baselines, with especially notable gains in cold-start and evolving-interest scenarios. Ablation studies further validate the importance of tool standardization and preference-optimized planning.
LoLA: Long Horizon Latent Action Learning for General Robot Manipulation
Dec 23, 2025The capability of performing long-horizon, language-guided robotic manipulation tasks critically relies on leveraging historical information and generating coherent action sequences. However, such capabilities are often overlooked by existing Vision-Language-Action (VLA) models. To solve this challenge, we propose LoLA (Long Horizon Latent Action Learning), a framework designed for robot manipulation that integrates long-term multi-view observations and robot proprioception to enable multi-step reasoning and action generation. We first employ Vision-Language Models to encode rich contextual features from historical sequences and multi-view observations. We further introduces a key module, State-Aware Latent Re-representation, which transforms visual inputs and language commands into actionable robot motion space. Unlike existing VLA approaches that merely concatenate robot proprioception (e.g., joint angles) with VL embeddings, this module leverages such robot states to explicitly ground VL representations in physical scale through a learnable "embodiment-anchored" latent space. We trained LoLA on diverse robotic pre-training datasets and conducted extensive evaluations on simulation benchmarks (SIMPLER and LIBERO), as well as two real-world tasks on Franka and Bi-Manual Aloha robots. Results show that LoLA significantly outperforms prior state-of-the-art methods (e.g., pi0), particularly in long-horizon manipulation tasks.
Sharpness-aware Federated Graph Learning
Dec 18, 2025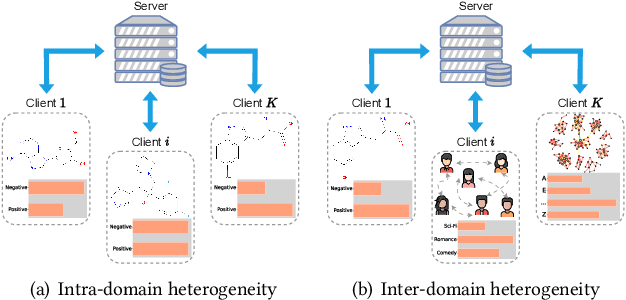
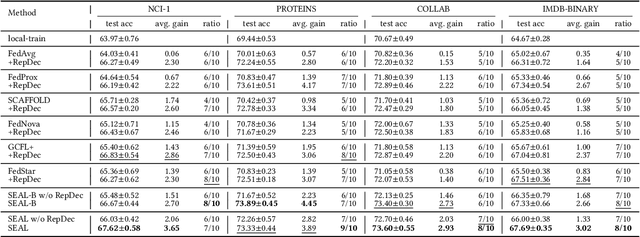
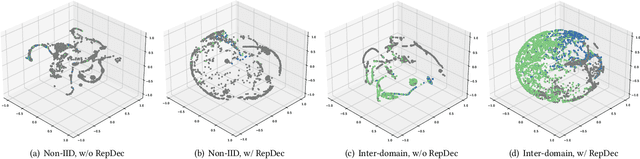
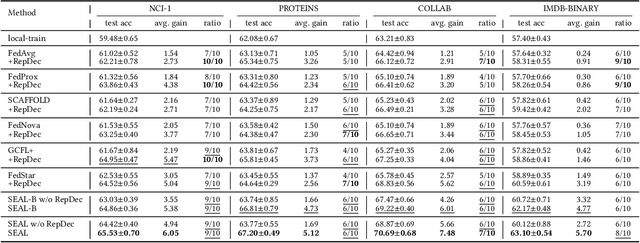
One of many impediments to applying graph neural networks (GNNs) to large-scale real-world graph data is the challenge of centralized training, which requires aggregating data from different organizations, raising privacy concerns. Federated graph learning (FGL) addresses this by enabling collaborative GNN model training without sharing private data. However, a core challenge in FGL systems is the variation in local training data distributions among clients, known as the data heterogeneity problem. Most existing solutions suffer from two problems: (1) The typical optimizer based on empirical risk minimization tends to cause local models to fall into sharp valleys and weakens their generalization to out-of-distribution graph data. (2) The prevalent dimensional collapse in the learned representations of local graph data has an adverse impact on the classification capacity of the GNN model. To this end, we formulate a novel optimization objective that is aware of the sharpness (i.e., the curvature of the loss surface) of local GNN models. By minimizing the loss function and its sharpness simultaneously, we seek out model parameters in a flat region with uniformly low loss values, thus improving the generalization over heterogeneous data. By introducing a regularizer based on the correlation matrix of local representations, we relax the correlations of representations generated by individual local graph samples, so as to alleviate the dimensional collapse of the learned model. The proposed \textbf{S}harpness-aware f\textbf{E}derated gr\textbf{A}ph \textbf{L}earning (SEAL) algorithm can enhance the classification accuracy and generalization ability of local GNN models in federated graph learning. Experimental studies on several graph classification benchmarks show that SEAL consistently outperforms SOTA FGL baselines and provides gains for more participants.
MSDformer: Multi-scale Discrete Transformer For Time Series Generation
May 20, 2025Discrete Token Modeling (DTM), which employs vector quantization techniques, has demonstrated remarkable success in modeling non-natural language modalities, particularly in time series generation. While our prior work SDformer established the first DTM-based framework to achieve state-of-the-art performance in this domain, two critical limitations persist in existing DTM approaches: 1) their inability to capture multi-scale temporal patterns inherent to complex time series data, and 2) the absence of theoretical foundations to guide model optimization. To address these challenges, we proposes a novel multi-scale DTM-based time series generation method, called Multi-Scale Discrete Transformer (MSDformer). MSDformer employs a multi-scale time series tokenizer to learn discrete token representations at multiple scales, which jointly characterize the complex nature of time series data. Subsequently, MSDformer applies a multi-scale autoregressive token modeling technique to capture the multi-scale patterns of time series within the discrete latent space. Theoretically, we validate the effectiveness of the DTM method and the rationality of MSDformer through the rate-distortion theorem. Comprehensive experiments demonstrate that MSDformer significantly outperforms state-of-the-art methods. Both theoretical analysis and experimental results demonstrate that incorporating multi-scale information and modeling multi-scale patterns can substantially enhance the quality of generated time series in DTM-based approaches. The code will be released upon acceptance.
TS-LIF: A Temporal Segment Spiking Neuron Network for Time Series Forecasting
Mar 07, 2025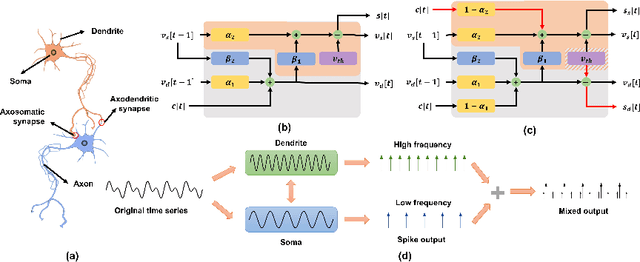



Spiking Neural Networks (SNNs) offer a promising, biologically inspired approach for processing spatiotemporal data, particularly for time series forecasting. However, conventional neuron models like the Leaky Integrate-and-Fire (LIF) struggle to capture long-term dependencies and effectively process multi-scale temporal dynamics. To overcome these limitations, we introduce the Temporal Segment Leaky Integrate-and-Fire (TS-LIF) model, featuring a novel dual-compartment architecture. The dendritic and somatic compartments specialize in capturing distinct frequency components, providing functional heterogeneity that enhances the neuron's ability to process both low- and high-frequency information. Furthermore, the newly introduced direct somatic current injection reduces information loss during intra-neuronal transmission, while dendritic spike generation improves multi-scale information extraction. We provide a theoretical stability analysis of the TS-LIF model and explain how each compartment contributes to distinct frequency response characteristics. Experimental results show that TS-LIF outperforms traditional SNNs in time series forecasting, demonstrating better accuracy and robustness, even with missing data. TS-LIF advances the application of SNNs in time-series forecasting, providing a biologically inspired approach that captures complex temporal dynamics and offers potential for practical implementation in diverse forecasting scenarios. The source code is available at https://github.com/kkking-kk/TS-LIF.
Unveiling Structural Memorization: Structural Membership Inference Attack for Text-to-Image Diffusion Models
Jul 18, 2024With the rapid advancements of large-scale text-to-image diffusion models, various practical applications have emerged, bringing significant convenience to society. However, model developers may misuse the unauthorized data to train diffusion models. These data are at risk of being memorized by the models, thus potentially violating citizens' privacy rights. Therefore, in order to judge whether a specific image is utilized as a member of a model's training set, Membership Inference Attack (MIA) is proposed to serve as a tool for privacy protection. Current MIA methods predominantly utilize pixel-wise comparisons as distinguishing clues, considering the pixel-level memorization characteristic of diffusion models. However, it is practically impossible for text-to-image models to memorize all the pixel-level information in massive training sets. Therefore, we move to the more advanced structure-level memorization. Observations on the diffusion process show that the structures of members are better preserved compared to those of nonmembers, indicating that diffusion models possess the capability to remember the structures of member images from training sets. Drawing on these insights, we propose a simple yet effective MIA method tailored for text-to-image diffusion models. Extensive experimental results validate the efficacy of our approach. Compared to current pixel-level baselines, our approach not only achieves state-of-the-art performance but also demonstrates remarkable robustness against various distortions.