 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Short, Inference Long: Training-free Horizon Extension for Autoregressive Video Generation
Feb 17, 2026Autoregressive video diffusion models have emerged as a scalable paradigm for long video generation. However, they often suffer from severe extrapolation failure, where rapid error accumulation leads to significant temporal degradation when extending beyond training horizons. We identify that this failure primarily stems from the spectral bias of 3D positional embeddings and the lack of dynamic priors in noise sampling. To address these issues, we propose FLEX (Frequency-aware Length EXtension), a training-free inference-time framework that bridges the gap between short-term training and long-term inference. FLEX introduces Frequency-aware RoPE Modulation to adaptively interpolate under-trained low-frequency components while extrapolating high-frequency ones to preserve multi-scale temporal discriminability. This is integrated with Antiphase Noise Sampling (ANS) to inject high-frequency dynamic priors and Inference-only Attention Sink to anchor global structure. Extensive evaluations on VBench demonstrate that FLEX significantly outperforms state-of-the-art models at 6x extrapolation (30s duration) and matches the performance of long-video fine-tuned baselines at 12x scale (60s duration). As a plug-and-play augmentation, FLEX seamlessly integrates into existing inference pipelines for horizon extension. It effectively pushes the generation limits of models such as LongLive, supporting consistent and dynamic video synthesis at a 4-minute scale. Project page is available at https://ga-lee.github.io/FLEX_demo.
Learning to Discover Forgery Cues for Face Forgery Detection
Sep 02, 2024



Locating manipulation maps, i.e., pixel-level annotation of forgery cues, is crucial for providing interpretable detection results in face forgery detection. Related learning objects have also been widely adopted as auxiliary tasks to improve the classification performance of detectors whereas they require comparisons between paired real and forged faces to obtain manipulation maps as supervision. This requirement restricts their applicability to unpaired faces and contradicts real-world scenarios. Moreover, the used comparison methods annotate all changed pixels, including noise introduced by compression and upsampling. Using such maps as supervision hinders the learning of exploitable cues and makes models prone to overfitting. To address these issues, we introduce a weakly supervised model in this paper, named Forgery Cue Discovery (FoCus), to locate forgery cues in unpaired faces. Unlike some detectors that claim to locate forged regions in attention maps, FoCus is designed to sidestep their shortcomings of capturing partial and inaccurate forgery cues. Specifically, we propose a classification attentive regions proposal module to locate forgery cues during classification and a complementary learning module to facilitate the learning of richer cues. The produced manipulation maps can serve as better supervision to enhance face forgery detectors. Visualization of the manipulation maps of the proposed FoCus exhibits superior interpretability and robustness compared to existing methods. Experiments on five datasets and four multi-task models demonstrate the effectiveness of FoCus in both in-dataset and cross-dataset evaluations.
Unveiling Structural Memorization: Structural Membership Inference Attack for Text-to-Image Diffusion Models
Jul 18, 2024With the rapid advancements of large-scale text-to-image diffusion models, various practical applications have emerged, bringing significant convenience to society. However, model developers may misuse the unauthorized data to train diffusion models. These data are at risk of being memorized by the models, thus potentially violating citizens' privacy rights. Therefore, in order to judge whether a specific image is utilized as a member of a model's training set, Membership Inference Attack (MIA) is proposed to serve as a tool for privacy protection. Current MIA methods predominantly utilize pixel-wise comparisons as distinguishing clues, considering the pixel-level memorization characteristic of diffusion models. However, it is practically impossible for text-to-image models to memorize all the pixel-level information in massive training sets. Therefore, we move to the more advanced structure-level memorization. Observations on the diffusion process show that the structures of members are better preserved compared to those of nonmembers, indicating that diffusion models possess the capability to remember the structures of member images from training sets. Drawing on these insights, we propose a simple yet effective MIA method tailored for text-to-image diffusion models. Extensive experimental results validate the efficacy of our approach. Compared to current pixel-level baselines, our approach not only achieves state-of-the-art performance but also demonstrates remarkable robustness against various distortions.
Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection
Apr 30, 2024



With the rising prevalence of deepfakes, there is a growing interest in developing generalizable detection methods for various types of deepfakes. While effective in their specific modalities, traditional detection methods fall short in addressing the generalizability of detection across diverse cross-modal deepfakes. This paper aims to explicitly learn potential cross-modal correlation to enhance deepfake detection towards various generation scenarios. Our approach introduces a correlation distillation task, which models the inherent cross-modal correlation based on content information. This strategy helps to prevent the model from overfitting merely to audio-visual synchronization. Additionally, we present the Cross-Modal Deepfake Dataset (CMDFD), a comprehensive dataset with four generation methods to evaluate the detection of diverse cross-modal deepfakes. The experimental results on CMDFD and FakeAVCeleb datasets demonstrate the superior generalizability of our method over existing state-of-the-art methods. Our code and data can be found at \url{https://github.com/ljj898/CMDFD-Dataset-and-Deepfake-Detection}.
Model Will Tell: Training Membership Inference for Diffusion Models
Mar 13, 2024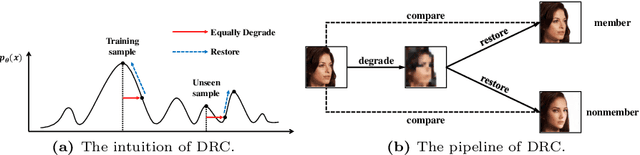
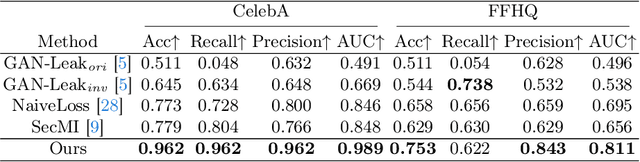
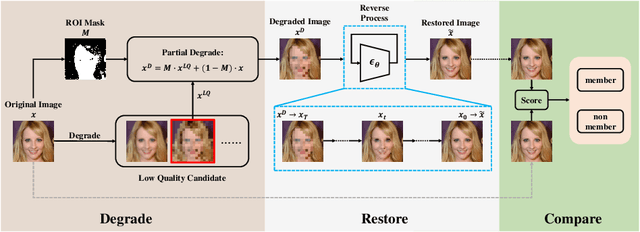
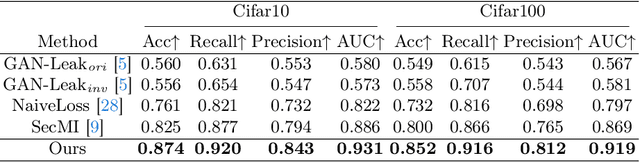
Diffusion models pose risks of privacy breaches and copyright disputes, primarily stemming from the potential utilization of unauthorized data during the training phase. The Training Membership Inference (TMI) task aims to determine whether a specific sample has been used in the training process of a target model, representing a critical tool for privacy violation verification. However, the increased stochasticity inherent in diffusion renders traditional shadow-model-based or metric-based methods ineffective when applied to diffusion models. Moreover, existing methods only yield binary classification labels which lack necessary comprehensibility in practical applications. In this paper, we explore a novel perspective for the TMI task by leveraging the intrinsic generative priors within the diffusion model. Compared with unseen samples, training samples exhibit stronger generative priors within the diffusion model, enabling the successful reconstruction of substantially degraded training images. Consequently, we propose the Degrade Restore Compare (DRC) framework. In this framework, an image undergoes sequential degradation and restoration, and its membership is determined by comparing it with the restored counterpart. Experimental results verify that our approach not only significantly outperforms existing methods in terms of accuracy but also provides comprehensible decision criteria, offering evidence for potential privacy violations.
OSM-Net: One-to-Many One-shot Talking Head Generation with Spontaneous Head Motions
Sep 28, 2023



One-shot talking head generation has no explicit head movement reference, thus it is difficult to generate talking heads with head motions. Some existing works only edit the mouth area and generate still talking heads, leading to unreal talking head performance. Other works construct one-to-one mapping between audio signal and head motion sequences, introducing ambiguity correspondences into the mapping since people can behave differently in head motions when speaking the same content. This unreasonable mapping form fails to model the diversity and produces either nearly static or even exaggerated head motions, which are unnatural and strange. Therefore, the one-shot talking head generation task is actually a one-to-many ill-posed problem and people present diverse head motions when speaking. Based on the above observation, we propose OSM-Net, a \textit{one-to-many} one-shot talking head generation network with natural head motions. OSM-Net constructs a motion space that contains rich and various clip-level head motion features. Each basis of the space represents a feature of meaningful head motion in a clip rather than just a frame, thus providing more coherent and natural motion changes in talking heads. The driving audio is mapped into the motion space, around which various motion features can be sampled within a reasonable range to achieve the one-to-many mapping. Besides, the landmark constraint and time window feature input improve the accurate expression feature extraction and video generation. Extensive experiments show that OSM-Net generates more natural realistic head motions under reasonable one-to-many mapping paradigm compared with other methods.
MFR-Net: Multi-faceted Responsive Listening Head Generation via Denoising Diffusion Model
Aug 31, 2023



Face-to-face communication is a common scenario including roles of speakers and listeners. Most existing research methods focus on producing speaker videos, while the generation of listener heads remains largely overlooked. Responsive listening head generation is an important task that aims to model face-to-face communication scenarios by generating a listener head video given a speaker video and a listener head image. An ideal generated responsive listening video should respond to the speaker with attitude or viewpoint expressing while maintaining diversity in interaction patterns and accuracy in listener identity information. To achieve this goal, we propose the \textbf{M}ulti-\textbf{F}aceted \textbf{R}esponsive Listening Head Generation Network (MFR-Net). Specifically, MFR-Net employs the probabilistic denoising diffusion model to predict diverse head pose and expression features. In order to perform multi-faceted response to the speaker video, while maintaining accurate listener identity preservation, we design the Feature Aggregation Module to boost listener identity features and fuse them with other speaker-related features. Finally, a renderer finetuned with identity consistency loss produces the final listening head videos. Our extensive experiments demonstrate that MFR-Net not only achieves multi-faceted responses in diversity and speaker identity information but also in attitude and viewpoint expression.
FONT: Flow-guided One-shot Talking Head Generation with Natural Head Motions
Mar 31, 2023
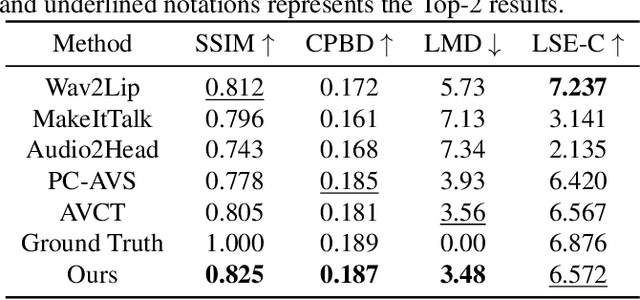
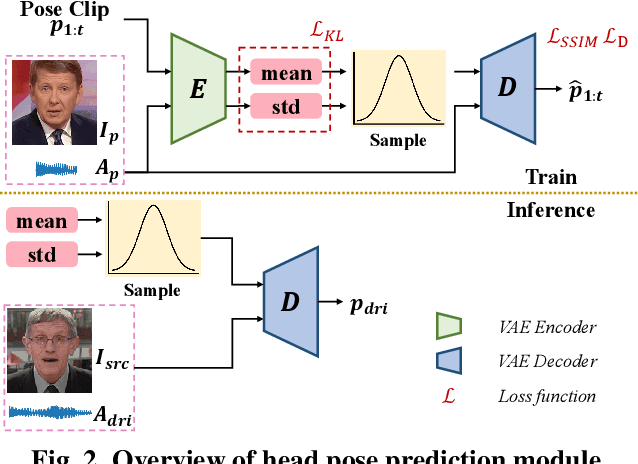

One-shot talking head generation has received growing attention in recent years, with various creative and practical applications. An ideal natural and vivid generated talking head video should contain natural head pose changes. However, it is challenging to map head pose sequences from driving audio since there exists a natural gap between audio-visual modalities. In this work, we propose a Flow-guided One-shot model that achieves NaTural head motions(FONT) over generated talking heads. Specifically, the head pose prediction module is designed to generate head pose sequences from the source face and driving audio. We add the random sampling operation and the structural similarity constraint to model the diversity in the one-to-many mapping between audio-visual modality, thus predicting natural head poses. Then we develop a keypoint predictor that produces unsupervised keypoints from the source face, driving audio and pose sequences to describe the facial structure information. Finally, a flow-guided occlusion-aware generator is employed to produce photo-realistic talking head videos from the estimated keypoints and source face. Extensive experimental results prove that FONT generates talking heads with natural head poses and synchronized mouth shapes, outperforming other compared methods.
OPT: One-shot Pose-Controllable Talking Head Generation
Feb 16, 2023



One-shot talking head generation produces lip-sync talking heads based on arbitrary audio and one source face. To guarantee the naturalness and realness, recent methods propose to achieve free pose control instead of simply editing mouth areas. However, existing methods do not preserve accurate identity of source face when generating head motions. To solve the identity mismatch problem and achieve high-quality free pose control, we present One-shot Pose-controllable Talking head generation network (OPT). Specifically, the Audio Feature Disentanglement Module separates content features from audios, eliminating the influence of speaker-specific information contained in arbitrary driving audios. Later, the mouth expression feature is extracted from the content feature and source face, during which the landmark loss is designed to enhance the accuracy of facial structure and identity preserving quality. Finally, to achieve free pose control, controllable head pose features from reference videos are fed into the Video Generator along with the expression feature and source face to generate new talking heads. Extensive quantitative and qualitative experimental results verify that OPT generates high-quality pose-controllable talking heads with no identity mismatch problem, outperforming previous SOTA methods.