 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic and perceptual differences between standard and accented Chinese speech and their voice clones
Apr 02, 2026Voice cloning is often evaluated in terms of overall quality, but less is known about accent preservation and its perceptual consequences. We compare standard and heavily accented Mandarin speech and their voice clones using a combined computational and perceptual design. Embedding-based analyses show no reliable accented-standard difference in original-clone distances across systems. In the perception study, clones are rated as more similar to their originals for standard than for accented speakers, and intelligibility increases from original to clone, with a larger gain for accented speech. These results show that accent variation can shape perceived identity match and intelligibility in voice cloning even when it is not reflected in an off-the-shelf speaker-embedding distance, and they motivate evaluating speaker identity preservation and accent preservation as separable dimensions.
Assessing the Ability of Neural TTS Systems to Model Consonant-Induced F0 Perturbation
Mar 22, 2026This study proposes a segmental-level prosodic probing framework to evaluate neural TTS models' ability to reproduce consonant-induced f0 perturbation, a fine-grained segmental-prosodic effect that reflects local articulatory mechanisms. We compare synthetic and natural speech realizations for thousands of words, stratified by lexical frequency, using Tacotron 2 and FastSpeech 2 trained on the same speech corpus (LJ Speech). These controlled analyses are then complemented by a large-scale evaluation spanning multiple advanced TTS systems. Results show accurate reproduction for high-frequency words but poor generalization to low-frequency items, suggesting that the examined TTS architectures rely more on lexical-level memorization than on abstract segmental-prosodic encoding. This finding highlights a limitation in such TTS systems' ability to generalize prosodic detail beyond seen data. The proposed probe offers a linguistically informed diagnostic framework that may inform future TTS evaluation methods, and has implications for interpretability and authenticity assessment in synthetic speech.
* Accepted for publication in Computer Speech & Language
BrandFusion: A Multi-Agent Framework for Seamless Brand Integration in Text-to-Video Generation
Mar 03, 2026The rapid advancement of text-to-video (T2V) models has revolutionized content creation, yet their commercial potential remains largely untapped. We introduce, for the first time, the task of seamless brand integration in T2V: automatically embedding advertiser brands into prompt-generated videos while preserving semantic fidelity to user intent. This task confronts three core challenges: maintaining prompt fidelity, ensuring brand recognizability, and achieving contextually natural integration. To address them, we propose BrandFusion, a novel multi-agent framework comprising two synergistic phases. In the offline phase (advertiser-facing), we construct a Brand Knowledge Base by probing model priors and adapting to novel brands via lightweight fine-tuning. In the online phase (user-facing), five agents jointly refine user prompts through iterative refinement, leveraging the shared knowledge base and real-time contextual tracking to ensure brand visibility and semantic alignment. Experiments on 18 established and 2 custom brands across multiple state-of-the-art T2V models demonstrate that BrandFusion significantly outperforms baselines in semantic preservation, brand recognizability, and integration naturalness. Human evaluations further confirm higher user satisfaction, establishing a practical pathway for sustainable T2V monetization.
Analyzing and Improving Fast Sampling of Text-to-Image Diffusion Models
Feb 28, 2026Text-to-image diffusion models have achieved unprecedented success but still struggle to produce high-quality results under limited sampling budgets. Existing training-free sampling acceleration methods are typically developed independently, leaving the overall performance and compatibility among these methods unexplored. In this paper, we bridge this gap by systematically elucidating the design space, and our comprehensive experiments identify the sampling time schedule as the most pivotal factor. Inspired by the geometric properties of diffusion models revealed through the Frenet-Serret formulas, we propose constant total rotation schedule (TORS), a scheduling strategy that ensures uniform geometric variation along the sampling trajectory. TORS outperforms previous training-free acceleration methods and produces high-quality images with 10 sampling steps on Flux.1-Dev and Stable Diffusion 3.5. Extensive experiments underscore the adaptability of our method to unseen models, hyperparameters, and downstream applications.
Unveiling Covert Toxicity in Multimodal Data via Toxicity Association Graphs: A Graph-Based Metric and Interpretable Detection Framework
Feb 03, 2026Detecting toxicity in multimodal data remains a significant challenge, as harmful meanings often lurk beneath seemingly benign individual modalities: only emerging when modalities are combined and semantic associations are activated. To address this, we propose a novel detection framework based on Toxicity Association Graphs (TAGs), which systematically model semantic associations between innocuous entities and latent toxic implications. Leveraging TAGs, we introduce the first quantifiable metric for hidden toxicity, the Multimodal Toxicity Covertness (MTC), which measures the degree of concealment in toxic multimodal expressions. By integrating our detection framework with the MTC metric, our approach enables precise identification of covert toxicity while preserving full interpretability of the decision-making process, significantly enhancing transparency in multimodal toxicity detection. To validate our method, we construct the Covert Toxic Dataset, the first benchmark specifically designed to capture high-covertness toxic multimodal instances. This dataset encodes nuanced cross-modal associations and serves as a rigorous testbed for evaluating both the proposed metric and detection framework. Extensive experiments demonstrate that our approach outperforms existing methods across both low- and high-covertness toxicity regimes, while delivering clear, interpretable, and auditable detection outcomes. Together, our contributions advance the state of the art in explainable multimodal toxicity detection and lay the foundation for future context-aware and interpretable approaches. Content Warning: This paper contains examples of toxic multimodal content that may be offensive or disturbing to some readers. Reader discretion is advised.
DeepfakeBench-MM: A Comprehensive Benchmark for Multimodal Deepfake Detection
Oct 26, 2025The misuse of advanced generative AI models has resulted in the widespread proliferation of falsified data, particularly forged human-centric audiovisual content, which poses substantial societal risks (e.g., financial fraud and social instability). In response to this growing threat, several works have preliminarily explored countermeasures. However, the lack of sufficient and diverse training data, along with the absence of a standardized benchmark, hinder deeper exploration. To address this challenge, we first build Mega-MMDF, a large-scale, diverse, and high-quality dataset for multimodal deepfake detection. Specifically, we employ 21 forgery pipelines through the combination of 10 audio forgery methods, 12 visual forgery methods, and 6 audio-driven face reenactment methods. Mega-MMDF currently contains 0.1 million real samples and 1.1 million forged samples, making it one of the largest and most diverse multimodal deepfake datasets, with plans for continuous expansion. Building on it, we present DeepfakeBench-MM, the first unified benchmark for multimodal deepfake detection. It establishes standardized protocols across the entire detection pipeline and serves as a versatile platform for evaluating existing methods as well as exploring novel approaches. DeepfakeBench-MM currently supports 5 datasets and 11 multimodal deepfake detectors. Furthermore, our comprehensive evaluations and in-depth analyses uncover several key findings from multiple perspectives (e.g., augmentation, stacked forgery). We believe that DeepfakeBench-MM, together with our large-scale Mega-MMDF, will serve as foundational infrastructures for advancing multimodal deepfake detection.
PIA: Deepfake Detection Using Phoneme-Temporal and Identity-Dynamic Analysis
Oct 16, 2025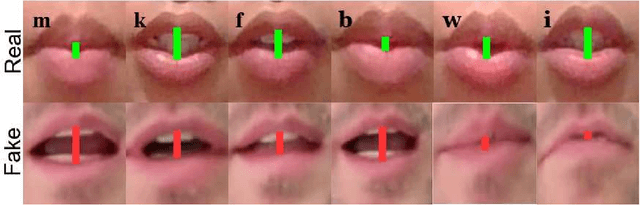
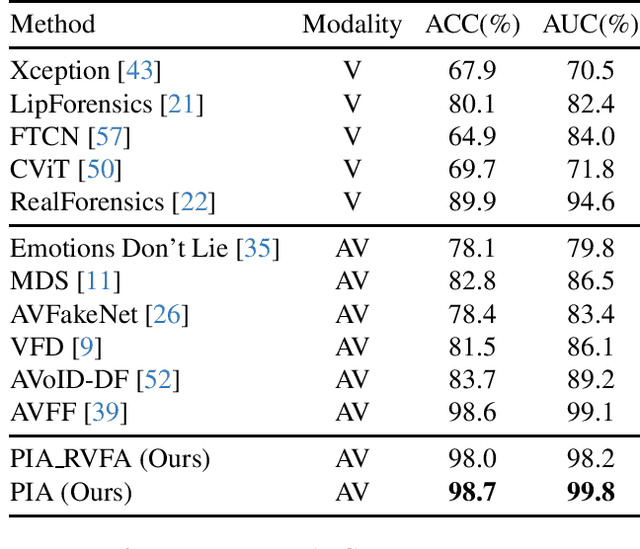
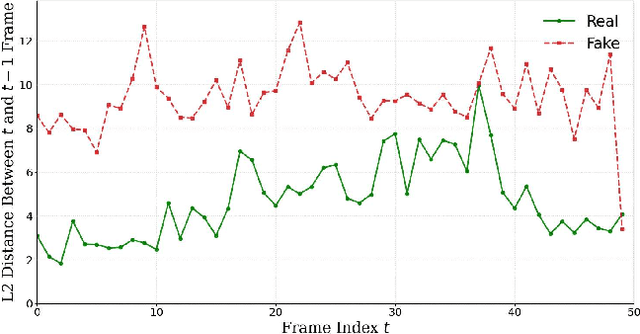
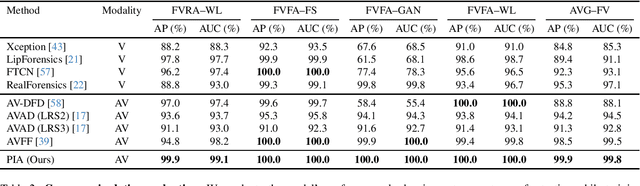
The rise of manipulated media has made deepfakes a particularly insidious threat, involving various generative manipulations such as lip-sync modifications, face-swaps, and avatar-driven facial synthesis. Conventional detection methods, which predominantly depend on manually designed phoneme-viseme alignment thresholds, fundamental frame-level consistency checks, or a unimodal detection strategy, inadequately identify modern-day deepfakes generated by advanced generative models such as GANs, diffusion models, and neural rendering techniques. These advanced techniques generate nearly perfect individual frames yet inadvertently create minor temporal discrepancies frequently overlooked by traditional detectors. We present a novel multimodal audio-visual framework, Phoneme-Temporal and Identity-Dynamic Analysis(PIA), incorporating language, dynamic face motion, and facial identification cues to address these limitations. We utilize phoneme sequences, lip geometry data, and advanced facial identity embeddings. This integrated method significantly improves the detection of subtle deepfake alterations by identifying inconsistencies across multiple complementary modalities. Code is available at https://github.com/skrantidatta/PIA
Celeb-DF++: A Large-scale Challenging Video DeepFake Benchmark for Generalizable Forensics
Jul 24, 2025The rapid advancement of AI technologies has significantly increased the diversity of DeepFake videos circulating online, posing a pressing challenge for \textit{generalizable forensics}, \ie, detecting a wide range of unseen DeepFake types using a single model. Addressing this challenge requires datasets that are not only large-scale but also rich in forgery diversity. However, most existing datasets, despite their scale, include only a limited variety of forgery types, making them insufficient for developing generalizable detection methods. Therefore, we build upon our earlier Celeb-DF dataset and introduce {Celeb-DF++}, a new large-scale and challenging video DeepFake benchmark dedicated to the generalizable forensics challenge. Celeb-DF++ covers three commonly encountered forgery scenarios: Face-swap (FS), Face-reenactment (FR), and Talking-face (TF). Each scenario contains a substantial number of high-quality forged videos, generated using a total of 22 various recent DeepFake methods. These methods differ in terms of architectures, generation pipelines, and targeted facial regions, covering the most prevalent DeepFake cases witnessed in the wild. We also introduce evaluation protocols for measuring the generalizability of 24 recent detection methods, highlighting the limitations of existing detection methods and the difficulty of our new dataset.
Geometric Regularity in Deterministic Sampling of Diffusion-based Generative Models
Jun 11, 2025Diffusion-based generative models employ stochastic differential equations (SDEs) and their equivalent probability flow ordinary differential equations (ODEs) to establish a smooth transformation between complex high-dimensional data distributions and tractable prior distributions. In this paper, we reveal a striking geometric regularity in the deterministic sampling dynamics: each simulated sampling trajectory lies within an extremely low-dimensional subspace, and all trajectories exhibit an almost identical ''boomerang'' shape, regardless of the model architecture, applied conditions, or generated content. We characterize several intriguing properties of these trajectories, particularly under closed-form solutions based on kernel-estimated data modeling. We also demonstrate a practical application of the discovered trajectory regularity by proposing a dynamic programming-based scheme to better align the sampling time schedule with the underlying trajectory structure. This simple strategy requires minimal modification to existing ODE-based numerical solvers, incurs negligible computational overhead, and achieves superior image generation performance, especially in regions with only $5 \sim 10$ function evaluations.
Forensic deepfake audio detection using segmental speech features
May 20, 2025This study explores the potential of using acoustic features of segmental speech sounds to detect deepfake audio. These features are highly interpretable because of their close relationship with human articulatory processes and are expected to be more difficult for deepfake models to replicate. The results demonstrate that certain segmental features commonly used in forensic voice comparison are effective in identifying deep-fakes, whereas some global features provide little value. These findings underscore the need to approach audio deepfake detection differently for forensic voice comparison and offer a new perspective on leveraging segmental features for this purpose.