 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating Multi-Suction Item Picking at Scale via Multi-Modal Learning of Pick Success
Jun 12, 2025This work demonstrates how autonomously learning aspects of robotic operation from sparsely-labeled, real-world data of deployed, engineered solutions at industrial scale can provide with solutions that achieve improved performance. Specifically, it focuses on multi-suction robot picking and performs a comprehensive study on the application of multi-modal visual encoders for predicting the success of candidate robotic picks. Picking diverse items from unstructured piles is an important and challenging task for robot manipulation in real-world settings, such as warehouses. Methods for picking from clutter must work for an open set of items while simultaneously meeting latency constraints to achieve high throughput. The demonstrated approach utilizes multiple input modalities, such as RGB, depth and semantic segmentation, to estimate the quality of candidate multi-suction picks. The strategy is trained from real-world item picking data, with a combination of multimodal pretrain and finetune. The manuscript provides comprehensive experimental evaluation performed over a large item-picking dataset, an item-picking dataset targeted to include partial occlusions, and a package-picking dataset, which focuses on containers, such as boxes and envelopes, instead of unpackaged items. The evaluation measures performance for different item configurations, pick scenes, and object types. Ablations help to understand the effects of in-domain pretraining, the impact of different modalities and the importance of finetuning. These ablations reveal both the importance of training over multiple modalities but also the ability of models to learn during pretraining the relationship between modalities so that during finetuning and inference, only a subset of them can be used as input.
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

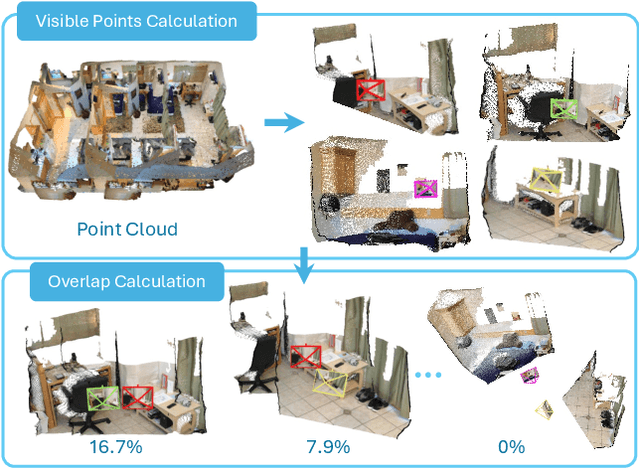

Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025



We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
OmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
Oct 09, 2024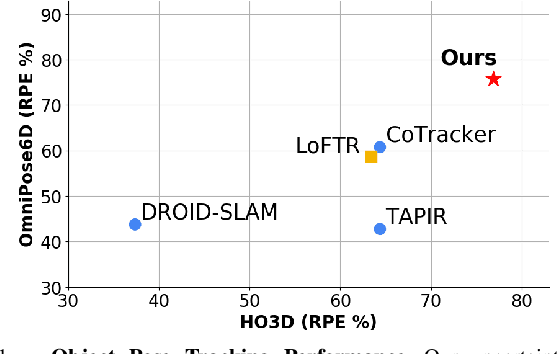

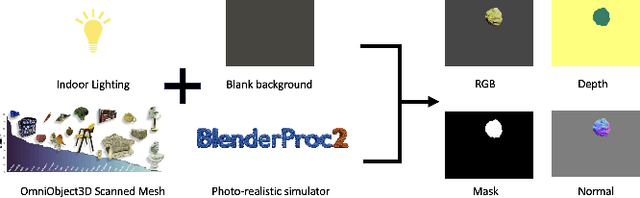
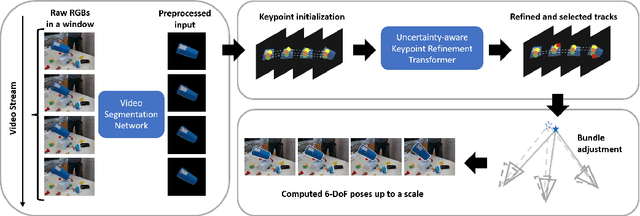
To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.
ADen: Adaptive Density Representations for Sparse-view Camera Pose Estimation
Aug 16, 2024Recovering camera poses from a set of images is a foundational task in 3D computer vision, which powers key applications such as 3D scene/object reconstructions. Classic methods often depend on feature correspondence, such as keypoints, which require the input images to have large overlap and small viewpoint changes. Such requirements present considerable challenges in scenarios with sparse views. Recent data-driven approaches aim to directly output camera poses, either through regressing the 6DoF camera poses or formulating rotation as a probability distribution. However, each approach has its limitations. On one hand, directly regressing the camera poses can be ill-posed, since it assumes a single mode, which is not true under symmetry and leads to sub-optimal solutions. On the other hand, probabilistic approaches are capable of modeling the symmetry ambiguity, yet they sample the entire space of rotation uniformly by brute-force. This leads to an inevitable trade-off between high sample density, which improves model precision, and sample efficiency that determines the runtime. In this paper, we propose ADen to unify the two frameworks by employing a generator and a discriminator: the generator is trained to output multiple hypotheses of 6DoF camera pose to represent a distribution and handle multi-mode ambiguity, and the discriminator is trained to identify the hypothesis that best explains the data. This allows ADen to combine the best of both worlds, achieving substantially higher precision as well as lower runtime than previous methods in empirical evaluations.
Domain Adaptation of Visual Policies with a Single Demonstration
Jul 23, 2024


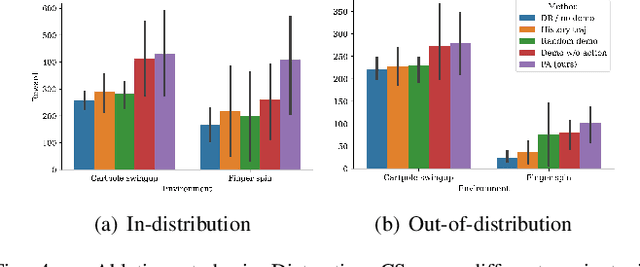
Deploying machine learning algorithms for robot tasks in real-world applications presents a core challenge: overcoming the domain gap between the training and the deployment environment. This is particularly difficult for visuomotor policies that utilize high-dimensional images as input, particularly when those images are generated via simulation. A common method to tackle this issue is through domain randomization, which aims to broaden the span of the training distribution to cover the test-time distribution. However, this approach is only effective when the domain randomization encompasses the actual shifts in the test-time distribution. We take a different approach, where we make use of a single demonstration (a prompt) to learn policy that adapts to the testing target environment. Our proposed framework, PromptAdapt, leverages the Transformer architecture's capacity to model sequential data to learn demonstration-conditioned visual policies, allowing for in-context adaptation to a target domain that is distinct from training. Our experiments in both simulation and real-world settings show that PromptAdapt is a strong domain-adapting policy that outperforms baseline methods by a large margin under a range of domain shifts, including variations in lighting, color, texture, and camera pose. Videos and more information can be viewed at project webpage: https://sites.google.com/view/promptadapt.
Adapting Image-based RL Policies via Predicted Rewards
Jul 23, 2024Image-based reinforcement learning (RL) faces significant challenges in generalization when the visual environment undergoes substantial changes between training and deployment. Under such circumstances, learned policies may not perform well leading to degraded results. Previous approaches to this problem have largely focused on broadening the training observation distribution, employing techniques like data augmentation and domain randomization. However, given the sequential nature of the RL decision-making problem, it is often the case that residual errors are propagated by the learned policy model and accumulate throughout the trajectory, resulting in highly degraded performance. In this paper, we leverage the observation that predicted rewards under domain shift, even though imperfect, can still be a useful signal to guide fine-tuning. We exploit this property to fine-tune a policy using reward prediction in the target domain. We have found that, even under significant domain shift, the predicted reward can still provide meaningful signal and fine-tuning substantially improves the original policy. Our approach, termed Predicted Reward Fine-tuning (PRFT), improves performance across diverse tasks in both simulated benchmarks and real-world experiments. More information is available at project web page: https://sites.google.com/view/prft.
3x2: 3D Object Part Segmentation by 2D Semantic Correspondences
Jul 12, 2024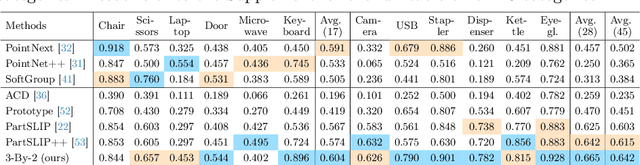

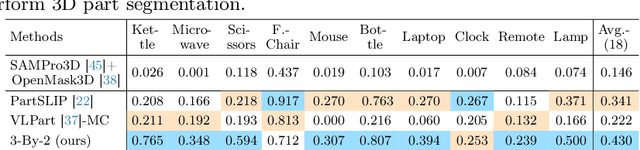
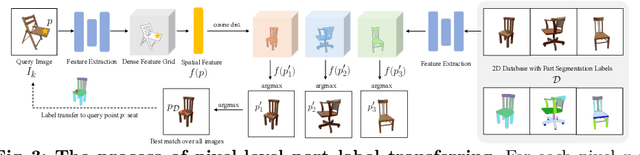
3D object part segmentation is essential in computer vision applications. While substantial progress has been made in 2D object part segmentation, the 3D counterpart has received less attention, in part due to the scarcity of annotated 3D datasets, which are expensive to collect. In this work, we propose to leverage a few annotated 3D shapes or richly annotated 2D datasets to perform 3D object part segmentation. We present our novel approach, termed 3-By-2 that achieves SOTA performance on different benchmarks with various granularity levels. By using features from pretrained foundation models and exploiting semantic and geometric correspondences, we are able to overcome the challenges of limited 3D annotations. Our approach leverages available 2D labels, enabling effective 3D object part segmentation. Our method 3-By-2 can accommodate various part taxonomies and granularities, demonstrating interesting part label transfer ability across different object categories. Project website: \url{https://ngailapdi.github.io/projects/3by2/}.
VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
Mar 19, 2024In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. VIHE autoregressively refines actions in multiple stages by conditioning on rendered views posed from action predictions in the earlier stages. These virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand, especially for challenging high-precision tasks such as peg insertion. On 18 manipulation tasks in RLBench simulated environments, VIHE achieves a new state-of-the-art, with a 12% absolute improvement, increasing from 65% to 77% over the existing state-of-the-art model using 100 demonstrations per task. In real-world scenarios, VIHE can learn manipulation tasks with just a handful of demonstrations, highlighting its practical utility. Videos and code implementation can be found at our project site: https://vihe-3d.github.io.