 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

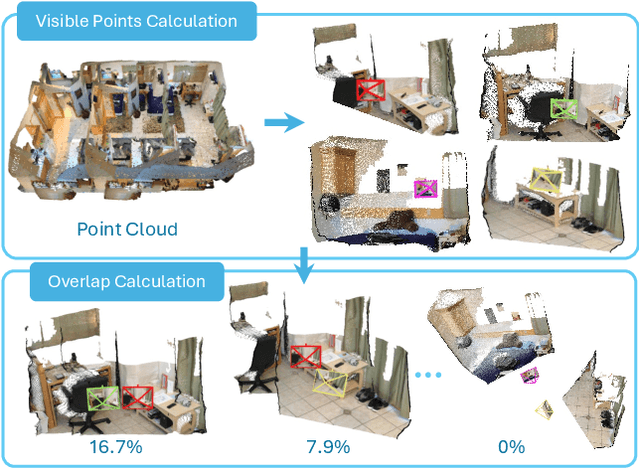

Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025



We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Jan 23, 2025Multi-view 3D reconstruction remains a core challenge in computer vision, particularly in applications requiring accurate and scalable representations across diverse perspectives. Current leading methods such as DUSt3R employ a fundamentally pairwise approach, processing images in pairs and necessitating costly global alignment procedures to reconstruct from multiple views. In this work, we propose Fast 3D Reconstruction (Fast3R), a novel multi-view generalization to DUSt3R that achieves efficient and scalable 3D reconstruction by processing many views in parallel. Fast3R's Transformer-based architecture forwards N images in a single forward pass, bypassing the need for iterative alignment. Through extensive experiments on camera pose estimation and 3D reconstruction, Fast3R demonstrates state-of-the-art performance, with significant improvements in inference speed and reduced error accumulation. These results establish Fast3R as a robust alternative for multi-view applications, offering enhanced scalability without compromising reconstruction accuracy.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
OmniPose6D: Towards Short-Term Object Pose Tracking in Dynamic Scenes from Monocular RGB
Oct 09, 2024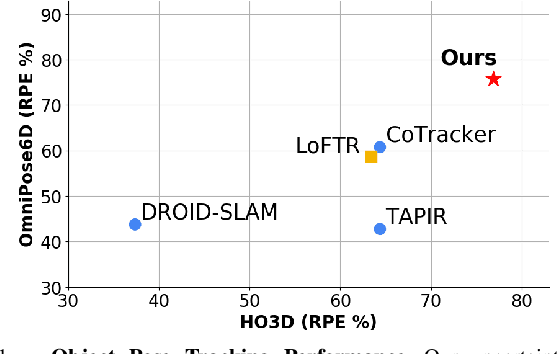

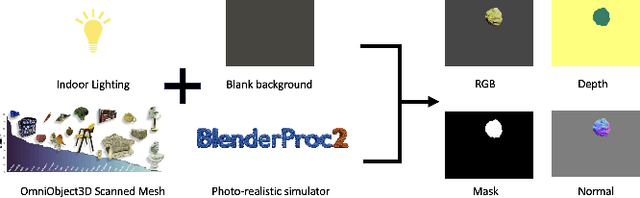
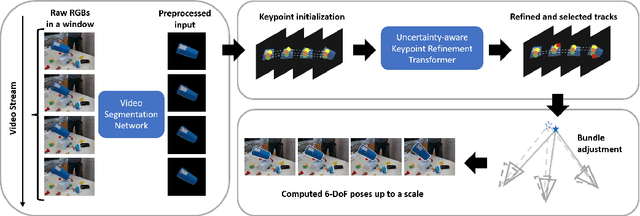
To address the challenge of short-term object pose tracking in dynamic environments with monocular RGB input, we introduce a large-scale synthetic dataset OmniPose6D, crafted to mirror the diversity of real-world conditions. We additionally present a benchmarking framework for a comprehensive comparison of pose tracking algorithms. We propose a pipeline featuring an uncertainty-aware keypoint refinement network, employing probabilistic modeling to refine pose estimation. Comparative evaluations demonstrate that our approach achieves performance superior to existing baselines on real datasets, underscoring the effectiveness of our synthetic dataset and refinement technique in enhancing tracking precision in dynamic contexts. Our contributions set a new precedent for the development and assessment of object pose tracking methodologies in complex scenes.
ADen: Adaptive Density Representations for Sparse-view Camera Pose Estimation
Aug 16, 2024Recovering camera poses from a set of images is a foundational task in 3D computer vision, which powers key applications such as 3D scene/object reconstructions. Classic methods often depend on feature correspondence, such as keypoints, which require the input images to have large overlap and small viewpoint changes. Such requirements present considerable challenges in scenarios with sparse views. Recent data-driven approaches aim to directly output camera poses, either through regressing the 6DoF camera poses or formulating rotation as a probability distribution. However, each approach has its limitations. On one hand, directly regressing the camera poses can be ill-posed, since it assumes a single mode, which is not true under symmetry and leads to sub-optimal solutions. On the other hand, probabilistic approaches are capable of modeling the symmetry ambiguity, yet they sample the entire space of rotation uniformly by brute-force. This leads to an inevitable trade-off between high sample density, which improves model precision, and sample efficiency that determines the runtime. In this paper, we propose ADen to unify the two frameworks by employing a generator and a discriminator: the generator is trained to output multiple hypotheses of 6DoF camera pose to represent a distribution and handle multi-mode ambiguity, and the discriminator is trained to identify the hypothesis that best explains the data. This allows ADen to combine the best of both worlds, achieving substantially higher precision as well as lower runtime than previous methods in empirical evaluations.
3x2: 3D Object Part Segmentation by 2D Semantic Correspondences
Jul 12, 2024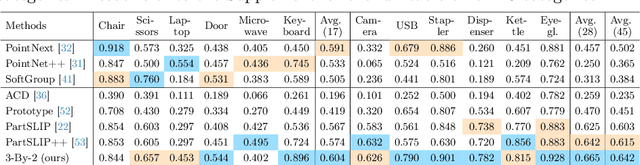

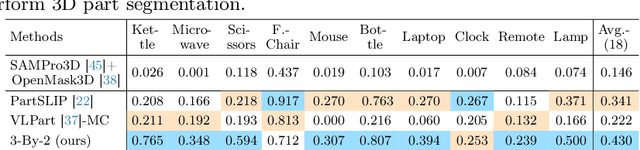
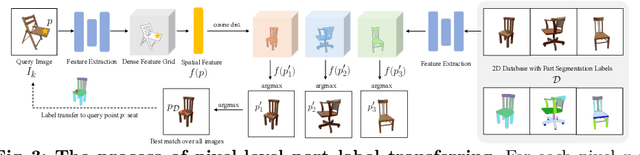
3D object part segmentation is essential in computer vision applications. While substantial progress has been made in 2D object part segmentation, the 3D counterpart has received less attention, in part due to the scarcity of annotated 3D datasets, which are expensive to collect. In this work, we propose to leverage a few annotated 3D shapes or richly annotated 2D datasets to perform 3D object part segmentation. We present our novel approach, termed 3-By-2 that achieves SOTA performance on different benchmarks with various granularity levels. By using features from pretrained foundation models and exploiting semantic and geometric correspondences, we are able to overcome the challenges of limited 3D annotations. Our approach leverages available 2D labels, enabling effective 3D object part segmentation. Our method 3-By-2 can accommodate various part taxonomies and granularities, demonstrating interesting part label transfer ability across different object categories. Project website: \url{https://ngailapdi.github.io/projects/3by2/}.
ICON: Incremental CONfidence for Joint Pose and Radiance Field Optimization
Jan 17, 2024Neural Radiance Fields (NeRF) exhibit remarkable performance for Novel View Synthesis (NVS) given a set of 2D images. However, NeRF training requires accurate camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Recent works have attempted to relax this constraint, but they still often rely on decent initial poses which they can refine. Here we aim at removing the requirement for pose initialization. We present Incremental CONfidence (ICON), an optimization procedure for training NeRFs from 2D video frames. ICON only assumes smooth camera motion to estimate initial guess for poses. Further, ICON introduces ``confidence": an adaptive measure of model quality used to dynamically reweight gradients. ICON relies on high-confidence poses to learn NeRF, and high-confidence 3D structure (as encoded by NeRF) to learn poses. We show that ICON, without prior pose initialization, achieves superior performance in both CO3D and HO3D versus methods which use SfM pose.
NOVIS: A Case for End-to-End Near-Online Video Instance Segmentation
Aug 29, 2023



Until recently, the Video Instance Segmentation (VIS) community operated under the common belief that offline methods are generally superior to a frame by frame online processing. However, the recent success of online methods questions this belief, in particular, for challenging and long video sequences. We understand this work as a rebuttal of those recent observations and an appeal to the community to focus on dedicated near-online VIS approaches. To support our argument, we present a detailed analysis on different processing paradigms and the new end-to-end trainable NOVIS (Near-Online Video Instance Segmentation) method. Our transformer-based model directly predicts spatio-temporal mask volumes for clips of frames and performs instance tracking between clips via overlap embeddings. NOVIS represents the first near-online VIS approach which avoids any handcrafted tracking heuristics. We outperform all existing VIS methods by large margins and provide new state-of-the-art results on both YouTube-VIS (2019/2021) and the OVIS benchmarks.