 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Mar 04, 2026Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manipulating objects that become temporarily occluded. Recent vision-language-action (VLA) models have begun to incorporate memory mechanisms; however, their evaluations remain confined to narrow, non-standardized settings. This limits their systematic understanding, comparison, and progress measurement. To address these challenges, we introduce RoboMME: a large-scale standardized benchmark for evaluating and advancing VLA models in long-horizon, history-dependent scenarios. Our benchmark comprises 16 manipulation tasks constructed under a carefully designed taxonomy that evaluates temporal, spatial, object, and procedural memory. We further develop a suite of 14 memory-augmented VLA variants built on the π0.5 backbone to systematically explore different memory representations across multiple integration strategies. Experimental results show that the effectiveness of memory representations is highly task-dependent, with each design offering distinct advantages and limitations across different tasks. Videos and code can be found at our website https://robomme.github.io.
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025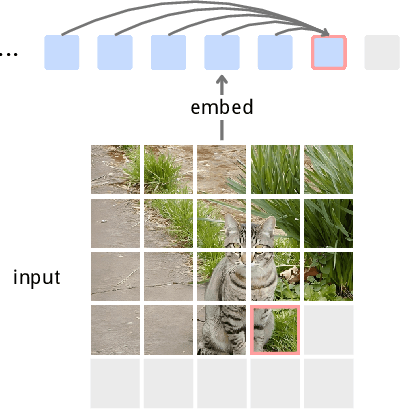
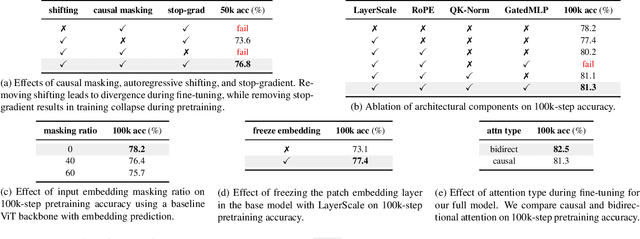
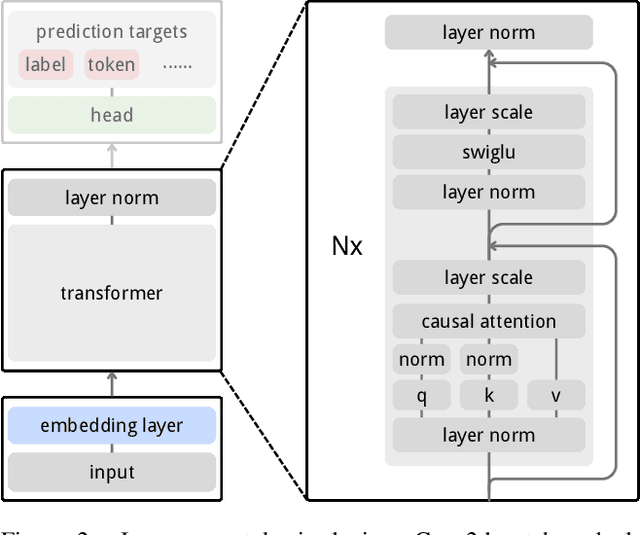
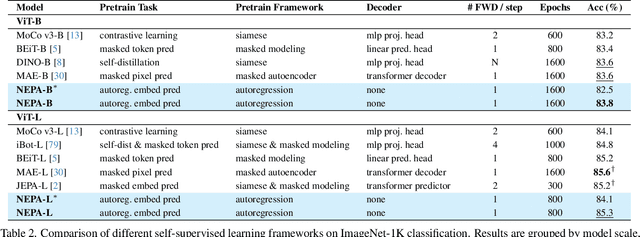
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Proactive Assistant Dialogue Generation from Streaming Egocentric Videos
Jun 06, 2025Recent advances in conversational AI have been substantial, but developing real-time systems for perceptual task guidance remains challenging. These systems must provide interactive, proactive assistance based on streaming visual inputs, yet their development is constrained by the costly and labor-intensive process of data collection and system evaluation. To address these limitations, we present a comprehensive framework with three key contributions. First, we introduce a novel data curation pipeline that synthesizes dialogues from annotated egocentric videos, resulting in \dataset, a large-scale synthetic dialogue dataset spanning multiple domains. Second, we develop a suite of automatic evaluation metrics, validated through extensive human studies. Third, we propose an end-to-end model that processes streaming video inputs to generate contextually appropriate responses, incorporating novel techniques for handling data imbalance and long-duration videos. This work lays the foundation for developing real-time, proactive AI assistants capable of guiding users through diverse tasks. Project page: https://pro-assist.github.io/
Temporally-Grounded Language Generation: A Benchmark for Real-Time Vision-Language Models
May 16, 2025Vision-language models (VLMs) have shown remarkable progress in offline tasks such as image captioning and video question answering. However, real-time interactive environments impose new demands on VLMs, requiring them to generate utterances that are not only semantically accurate but also precisely timed. We identify two core capabilities necessary for such settings -- $\textit{perceptual updating}$ and $\textit{contingency awareness}$ -- and propose a new benchmark task, $\textbf{Temporally-Grounded Language Generation (TGLG)}$, to evaluate them. TGLG requires models to generate utterances in response to streaming video such that both content and timing align with dynamic visual input. To support this benchmark, we curate evaluation datasets from sports broadcasting and egocentric human interaction domains, and introduce a new metric, $\textbf{TRACE}$, to evaluate TGLG by jointly measuring semantic similarity and temporal alignment. Finally, we present $\textbf{Vision-Language Model with Time-Synchronized Interleaving (VLM-TSI)}$, a model that interleaves visual and linguistic tokens in a time-synchronized manner, enabling real-time language generation without relying on turn-based assumptions. Experimental results show that VLM-TSI significantly outperforms a strong baseline, yet overall performance remains modest -- highlighting the difficulty of TGLG and motivating further research in real-time VLMs. Code and data available $\href{https://github.com/yukw777/tglg}{here}$.
Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation
Apr 22, 2025
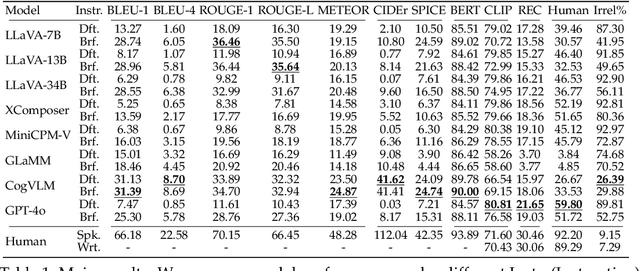

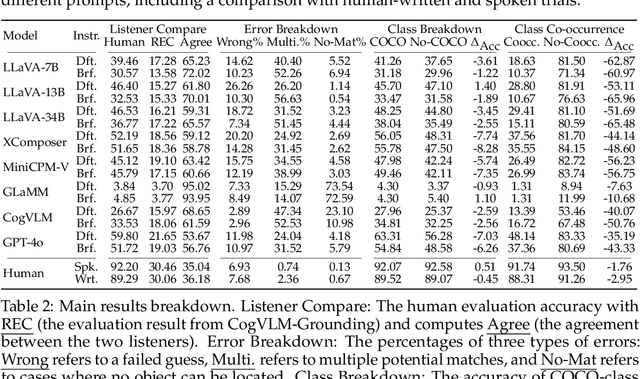
Referring Expression Generation (REG) is a core task for evaluating the pragmatic competence of vision-language systems, requiring not only accurate semantic grounding but also adherence to principles of cooperative communication (Grice, 1975). However, current evaluations of vision-language models (VLMs) often overlook the pragmatic dimension, reducing REG to a region-based captioning task and neglecting Gricean maxims. In this work, we revisit REG from a pragmatic perspective, introducing a new dataset (RefOI) of 1.5k images annotated with both written and spoken referring expressions. Through a systematic evaluation of state-of-the-art VLMs, we identify three key failures of pragmatic competence: (1) failure to uniquely identify the referent, (2) inclusion of excessive or irrelevant information, and (3) misalignment with human pragmatic preference, such as the underuse of minimal spatial cues. We also show that standard automatic evaluations fail to capture these pragmatic violations, reinforcing superficial cues rather than genuine referential success. Our findings call for a renewed focus on pragmatically informed models and evaluation frameworks that align with real human communication.
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Mar 19, 2025Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
Training Turn-by-Turn Verifiers for Dialogue Tutoring Agents: The Curious Case of LLMs as Your Coding Tutors
Feb 18, 2025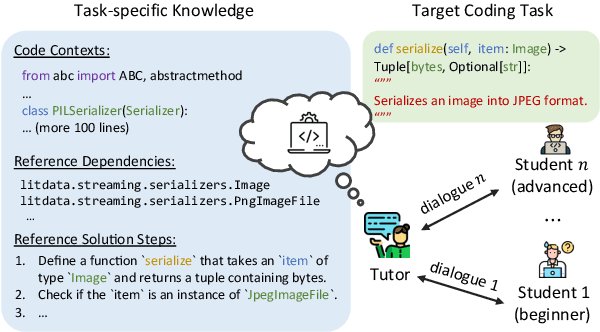
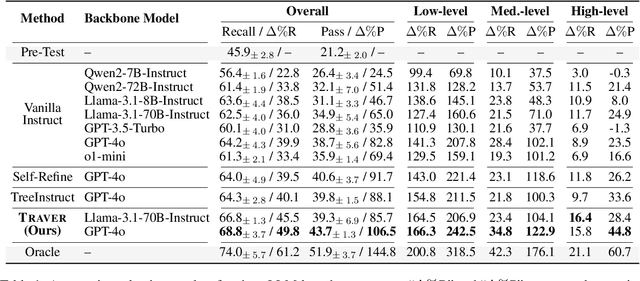
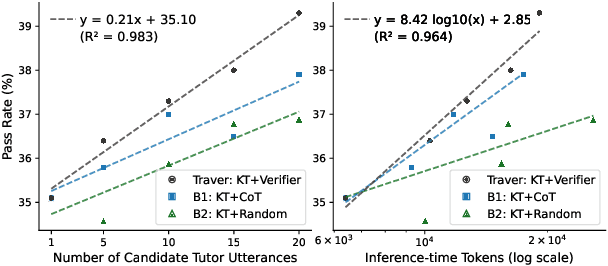

Intelligent tutoring agents powered by large language models (LLMs) have been increasingly explored to deliver personalized guidance in areas such as language learning and science education. However, their capabilities in guiding users to solve complex real-world tasks remain underexplored. To address this limitation, in this work, we focus on coding tutoring, a challenging problem that requires tutors to proactively guide students toward completing predefined coding tasks. We propose a novel agent workflow, Trace-and-Verify (TRAVER), which combines knowledge tracing to estimate a student's knowledge state and turn-by-turn verification to ensure effective guidance toward task completion. We introduce DICT, an automatic evaluation protocol that assesses tutor agents holistically using controlled student simulation and code generation tests. Extensive experiments reveal the challenges of coding tutoring and demonstrate that TRAVER achieves a significantly higher success rate. Although we use code tutoring as an example in this paper, our results and findings can be extended beyond coding, providing valuable insights into advancing tutoring agents for a variety of tasks.
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Jan 23, 2025Multi-view 3D reconstruction remains a core challenge in computer vision, particularly in applications requiring accurate and scalable representations across diverse perspectives. Current leading methods such as DUSt3R employ a fundamentally pairwise approach, processing images in pairs and necessitating costly global alignment procedures to reconstruct from multiple views. In this work, we propose Fast 3D Reconstruction (Fast3R), a novel multi-view generalization to DUSt3R that achieves efficient and scalable 3D reconstruction by processing many views in parallel. Fast3R's Transformer-based architecture forwards N images in a single forward pass, bypassing the need for iterative alignment. Through extensive experiments on camera pose estimation and 3D reconstruction, Fast3R demonstrates state-of-the-art performance, with significant improvements in inference speed and reduced error accumulation. These results establish Fast3R as a robust alternative for multi-view applications, offering enhanced scalability without compromising reconstruction accuracy.