 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging
Feb 05, 2026Model merging combines multiple fine-tuned models into a single model by adding their weight updates, providing a lightweight alternative to retraining. Existing methods primarily target resolving conflicts between task updates, leaving the failure mode of over-counting shared knowledge unaddressed. We show that when tasks share aligned spectral directions (i.e., overlapping singular vectors), a simple linear combination repeatedly accumulates these directions, inflating the singular values and biasing the merged model toward shared subspaces. To mitigate this issue, we propose Singular Value Calibration (SVC), a training-free and data-free post-processing method that quantifies subspace overlap and rescales inflated singular values to restore a balanced spectrum. Across vision and language benchmarks, SVC consistently improves strong merging baselines and achieves state-of-the-art performance. Furthermore, by modifying only the singular values, SVC improves the performance of Task Arithmetic by 13.0%. Code is available at: https://github.com/lyymuwu/SVC.
MAGIC: Achieving Superior Model Merging via Magnitude Calibration
Dec 22, 2025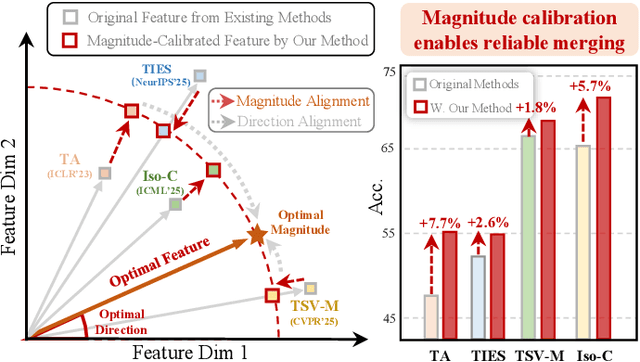
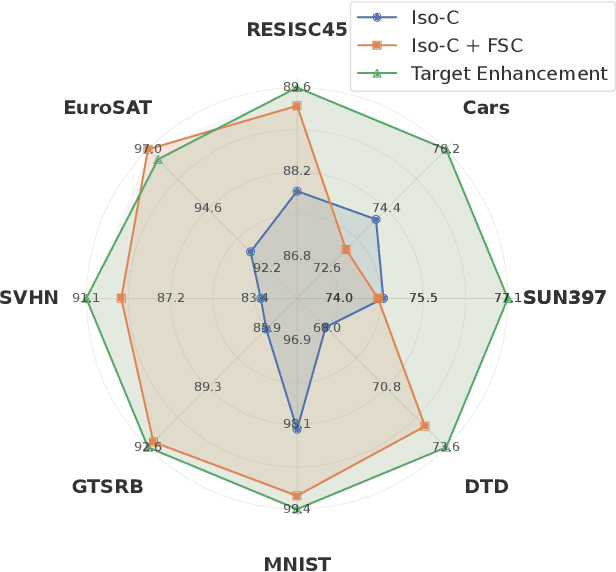
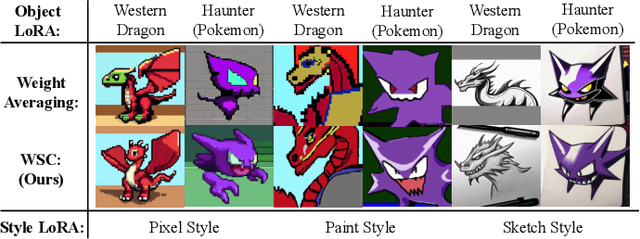
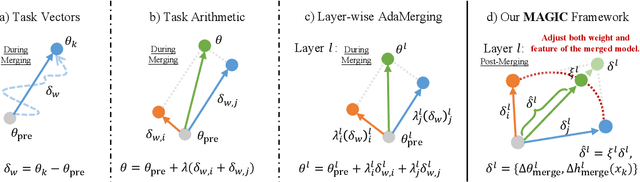
The proliferation of pre-trained models has given rise to a wide array of specialised, fine-tuned models. Model merging aims to merge the distinct capabilities of these specialised models into a unified model, requiring minimal or even no additional training. A core objective of model merging is to ensure the merged model retains the behavioural characteristics of the specialised models, typically achieved through feature alignment. We identify that features consist of two critical components: direction and magnitude. Prior research has predominantly focused on directional alignment, while the influence of magnitude remains largely neglected, despite its pronounced vulnerability to perturbations introduced by common merging operations (e.g., parameter fusion and sparsification). Such perturbations to magnitude inevitably lead to feature deviations in the merged model from the specialised models, resulting in subsequent performance degradation. To address this, we propose MAGnItude Calibration (MAGIC), a plug-and-play framework that rectifies layer-wise magnitudes in feature and weight spaces, with three variants. Specifically, our Feature Space Calibration (FSC) realigns the merged model's features using a small set of unlabelled data, while Weight Space Calibration (WSC) extends this calibration to the weight space without requiring additional data. Combining these yields Dual Space Calibration (DSC). Comprehensive experiments demonstrate that MAGIC consistently boosts performance across diverse Computer Vision tasks (+4.3% on eight datasets) and NLP tasks (+8.0% on Llama) without additional training. Our code is available at: https://github.com/lyymuwu/MAGIC
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025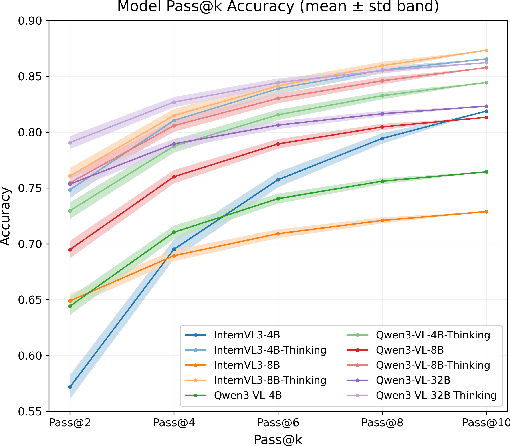

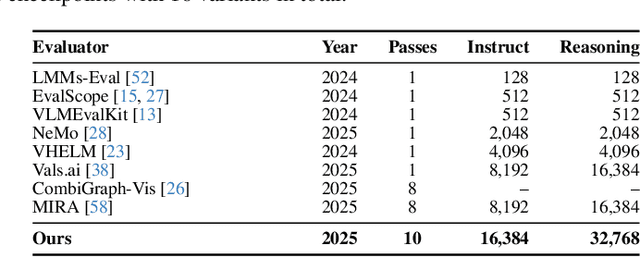
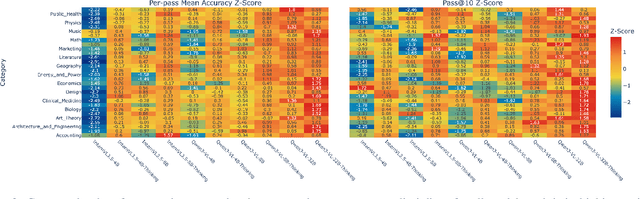
Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
Explainable Procedural Mistake Detection
Dec 16, 2024Automated task guidance has recently attracted attention from the AI research community. Procedural mistake detection (PMD) is a challenging sub-problem of classifying whether a human user (observed through egocentric video) has successfully executed the task at hand (specified by a procedural text). Despite significant efforts in building resources and models for PMD, machine performance remains nonviable, and the reasoning processes underlying this performance are opaque. As such, we recast PMD to an explanatory self-dialog of questions and answers, which serve as evidence for a decision. As this reformulation enables an unprecedented transparency, we leverage a fine-tuned natural language inference (NLI) model to formulate two automated coherence metrics for generated explanations. Our results show that while open-source VLMs struggle with this task off-the-shelf, their accuracy, coherence, and dialog efficiency can be vastly improved by incorporating these coherence metrics into common inference and fine-tuning methods. Furthermore, our multi-faceted metrics can visualize common outcomes at a glance, highlighting areas for improvement.
Text and Image Are Mutually Beneficial: Enhancing Training-Free Few-Shot Classification with CLIP
Dec 16, 2024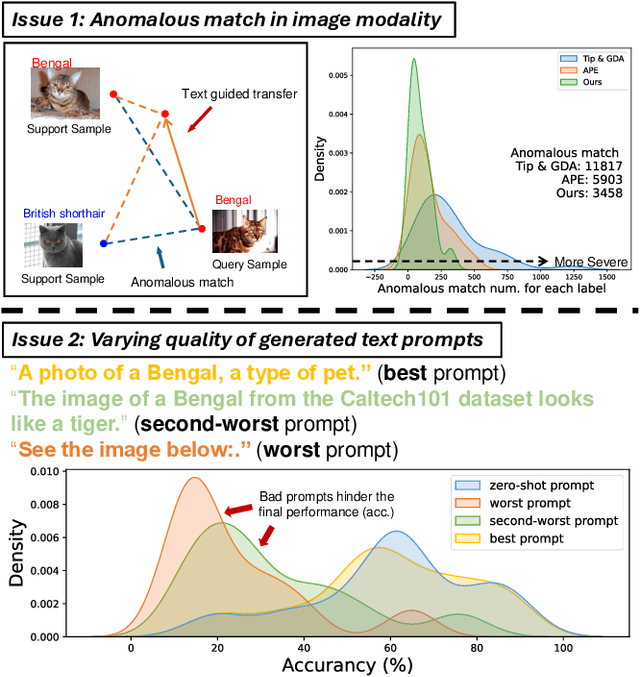
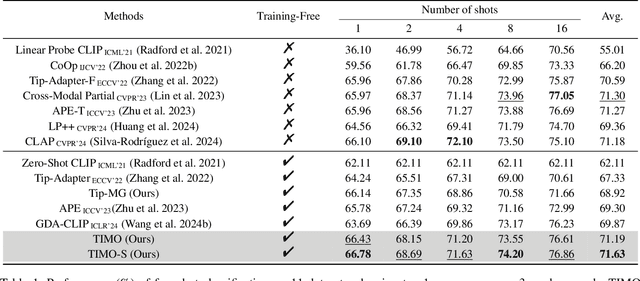
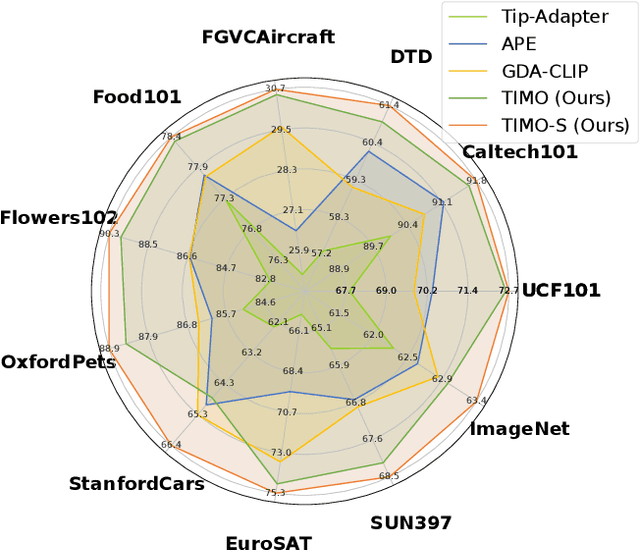

Contrastive Language-Image Pretraining (CLIP) has been widely used in vision tasks. Notably, CLIP has demonstrated promising performance in few-shot learning (FSL). However, existing CLIP-based methods in training-free FSL (i.e., without the requirement of additional training) mainly learn different modalities independently, leading to two essential issues: 1) severe anomalous match in image modality; 2) varying quality of generated text prompts. To address these issues, we build a mutual guidance mechanism, that introduces an Image-Guided-Text (IGT) component to rectify varying quality of text prompts through image representations, and a Text-Guided-Image (TGI) component to mitigate the anomalous match of image modality through text representations. By integrating IGT and TGI, we adopt a perspective of Text-Image Mutual guidance Optimization, proposing TIMO. Extensive experiments show that TIMO significantly outperforms the state-of-the-art (SOTA) training-free method. Additionally, by exploring the extent of mutual guidance, we propose an enhanced variant, TIMO-S, which even surpasses the best training-required methods by 0.33% with approximately 100 times less time cost. Our code is available at https://github.com/lyymuwu/TIMO.
Instructional Video Generation
Dec 05, 2024



Despite the recent strides in video generation, state-of-the-art methods still struggle with elements of visual detail. One particularly challenging case is the class of egocentric instructional videos in which the intricate motion of the hand coupled with a mostly stable and non-distracting environment is necessary to convey the appropriate visual action instruction. To address these challenges, we introduce a new method for instructional video generation. Our diffusion-based method incorporates two distinct innovations. First, we propose an automatic method to generate the expected region of motion, guided by both the visual context and the action text. Second, we introduce a critical hand structure loss to guide the diffusion model to focus on smooth and consistent hand poses. We evaluate our method on augmented instructional datasets based on EpicKitchens and Ego4D, demonstrating significant improvements over state-of-the-art methods in terms of instructional clarity, especially of the hand motion in the target region, across diverse environments and actions.Video results can be found on the project webpage: https://excitedbutter.github.io/Instructional-Video-Generation/