 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableMind: Source-Free Cross-Subject fMRI Decoding with Regularized Adaptation
May 04, 2026Existing cross-subject fMRI decoding methods typically train a model on multiple scanned subjects and then adapt it to a new subject using substantial paired fMRI-image data. However, in realistic scenarios, new-subject fMRI data are often limited due to costly data acquisition, and raw data from previous subjects may be inaccessible, leading existing methods to suffer performance degradation during new-subject adaptation. In this paper, we identify that this degradation stems from two key issues: brain-side instability caused by large subject differences in fMRI responses, and image-side supervision unreliability caused by fine-grained visual details that are not reliably supported by limited fMRI signals. To address these challenges, we propose StableMind, a regularized adaptation framework designed to improve brain-side representation stability and image-side supervision reliability. (1) To stabilize brain representations, StableMind reuses ridge projections from the pretrained model as adaptation priors to constrain limited-data new-subject adaptation, and applies Fourier-based feature-level brain augmentation to improve robustness to individual variability. (2) To improve image supervision reliability, StableMind introduces difficulty-aware image blur for brain-image alignment, reducing the influence of fine-grained visual details that are weakly supported by limited fMRI signals while preserving stable visual structure. Experiments on the Natural Scenes Dataset under a unified 1-hour adaptation protocol demonstrate that StableMind achieves 84.02% image retrieval accuracy and 81.66% brain retrieval accuracy averaged over four subjects, surpassing the state-of-the-art method by 5.71% brain retrieval accuracy with fewer trainable adaptation parameters. Our code is available at https://github.com/lingeringlight/StableMind.
Duala: Dual-Level Alignment of Subjects and Stimuli for Cross-Subject fMRI Decoding
Mar 08, 2026Cross-subject visual decoding aims to reconstruct visual experiences from brain activity across individuals, enabling more scalable and practical brain-computer interfaces. However, existing methods often suffer from degraded performance when adapting to new subjects with limited data, as they struggle to preserve both the semantic consistency of stimuli and the alignment of brain responses. To address these challenges, we propose Duala, a dual-level alignment framework designed to achieve stimulus-level consistency and subject-level alignment in fMRI-based cross-subject visual decoding. (1) At the stimulus level, Duala introduces a semantic alignment and relational consistency strategy that preserves intra-class similarity and inter-class separability, maintaining clear semantic boundaries during adaptation. (2) At the subject level, a distribution-based feature perturbation mechanism is developed to capture both global and subject-specific variations, enabling adaptation to individual neural representations without overfitting. Experiments on the Natural Scenes Dataset (NSD) demonstrate that Duala effectively improves alignment across subjects. Remarkably, even when fine-tuned with only about one hour of fMRI data, Duala achieves over 81.1% image-to-brain retrieval accuracy and consistently outperforms existing fine-tuning strategies in both retrieval and reconstruction. Our code is available at https://github.com/ShumengLI/Duala.
When Shared Knowledge Hurts: Spectral Over-Accumulation in Model Merging
Feb 05, 2026Model merging combines multiple fine-tuned models into a single model by adding their weight updates, providing a lightweight alternative to retraining. Existing methods primarily target resolving conflicts between task updates, leaving the failure mode of over-counting shared knowledge unaddressed. We show that when tasks share aligned spectral directions (i.e., overlapping singular vectors), a simple linear combination repeatedly accumulates these directions, inflating the singular values and biasing the merged model toward shared subspaces. To mitigate this issue, we propose Singular Value Calibration (SVC), a training-free and data-free post-processing method that quantifies subspace overlap and rescales inflated singular values to restore a balanced spectrum. Across vision and language benchmarks, SVC consistently improves strong merging baselines and achieves state-of-the-art performance. Furthermore, by modifying only the singular values, SVC improves the performance of Task Arithmetic by 13.0%. Code is available at: https://github.com/lyymuwu/SVC.
MAGIC: Achieving Superior Model Merging via Magnitude Calibration
Dec 22, 2025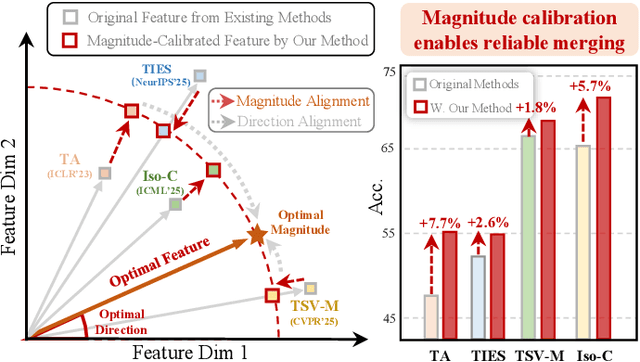
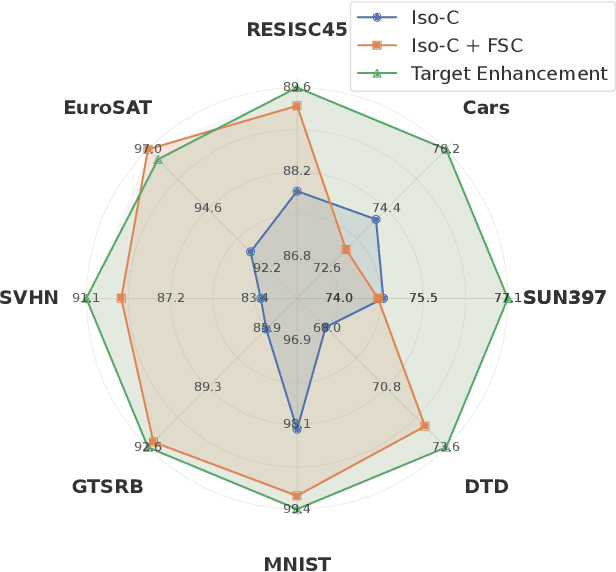
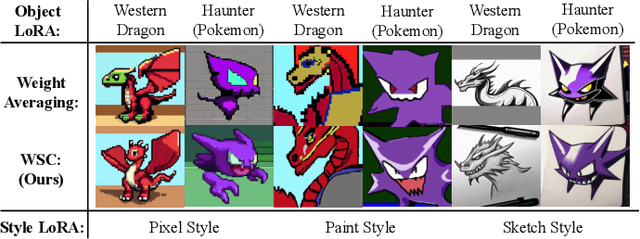
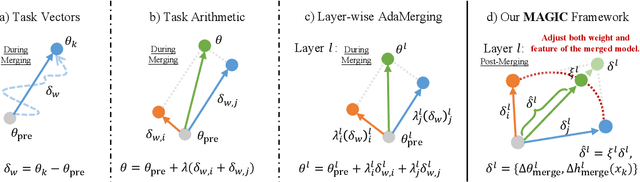
The proliferation of pre-trained models has given rise to a wide array of specialised, fine-tuned models. Model merging aims to merge the distinct capabilities of these specialised models into a unified model, requiring minimal or even no additional training. A core objective of model merging is to ensure the merged model retains the behavioural characteristics of the specialised models, typically achieved through feature alignment. We identify that features consist of two critical components: direction and magnitude. Prior research has predominantly focused on directional alignment, while the influence of magnitude remains largely neglected, despite its pronounced vulnerability to perturbations introduced by common merging operations (e.g., parameter fusion and sparsification). Such perturbations to magnitude inevitably lead to feature deviations in the merged model from the specialised models, resulting in subsequent performance degradation. To address this, we propose MAGnItude Calibration (MAGIC), a plug-and-play framework that rectifies layer-wise magnitudes in feature and weight spaces, with three variants. Specifically, our Feature Space Calibration (FSC) realigns the merged model's features using a small set of unlabelled data, while Weight Space Calibration (WSC) extends this calibration to the weight space without requiring additional data. Combining these yields Dual Space Calibration (DSC). Comprehensive experiments demonstrate that MAGIC consistently boosts performance across diverse Computer Vision tasks (+4.3% on eight datasets) and NLP tasks (+8.0% on Llama) without additional training. Our code is available at: https://github.com/lyymuwu/MAGIC
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
May 05, 2025

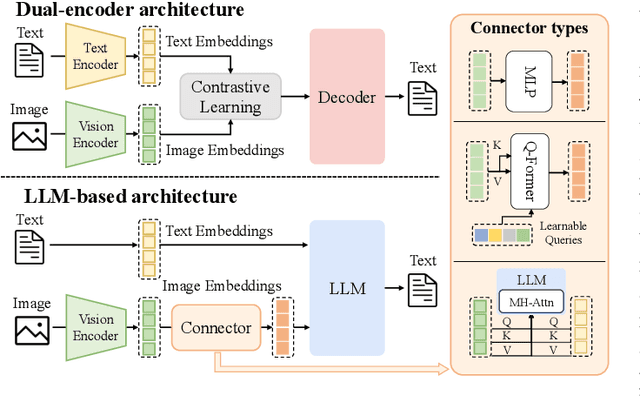

Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o's new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey will be available on GitHub soon.
Mamba-Sea: A Mamba-based Framework with Global-to-Local Sequence Augmentation for Generalizable Medical Image Segmentation
Apr 24, 2025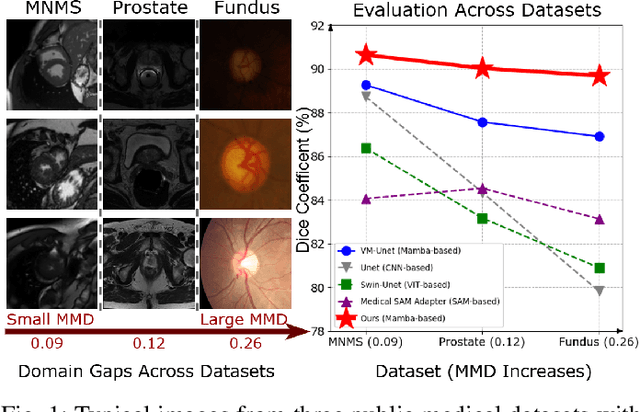
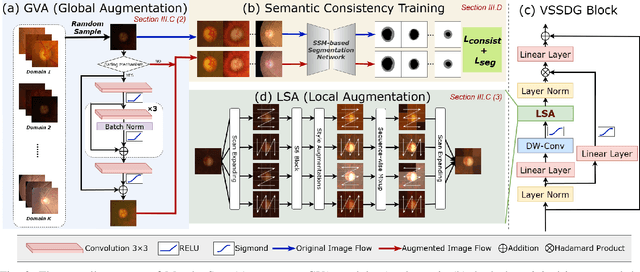

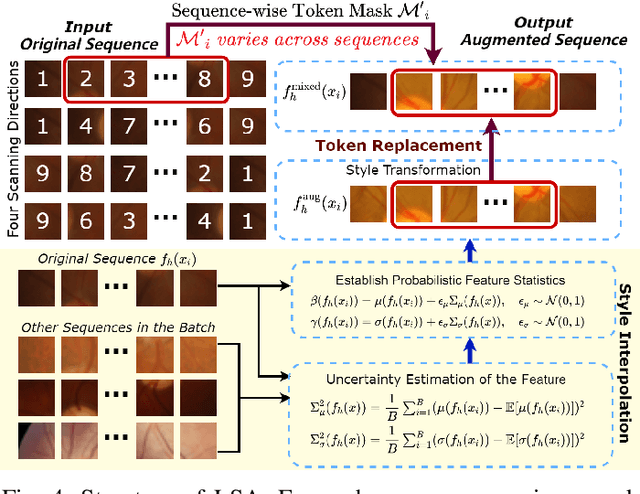
To segment medical images with distribution shifts, domain generalization (DG) has emerged as a promising setting to train models on source domains that can generalize to unseen target domains. Existing DG methods are mainly based on CNN or ViT architectures. Recently, advanced state space models, represented by Mamba, have shown promising results in various supervised medical image segmentation. The success of Mamba is primarily owing to its ability to capture long-range dependencies while keeping linear complexity with input sequence length, making it a promising alternative to CNNs and ViTs. Inspired by the success, in the paper, we explore the potential of the Mamba architecture to address distribution shifts in DG for medical image segmentation. Specifically, we propose a novel Mamba-based framework, Mamba-Sea, incorporating global-to-local sequence augmentation to improve the model's generalizability under domain shift issues. Our Mamba-Sea introduces a global augmentation mechanism designed to simulate potential variations in appearance across different sites, aiming to suppress the model's learning of domain-specific information. At the local level, we propose a sequence-wise augmentation along input sequences, which perturbs the style of tokens within random continuous sub-sequences by modeling and resampling style statistics associated with domain shifts. To our best knowledge, Mamba-Sea is the first work to explore the generalization of Mamba for medical image segmentation, providing an advanced and promising Mamba-based architecture with strong robustness to domain shifts. Remarkably, our proposed method is the first to surpass a Dice coefficient of 90% on the Prostate dataset, which exceeds previous SOTA of 88.61%. The code is available at https://github.com/orange-czh/Mamba-Sea.
Text and Image Are Mutually Beneficial: Enhancing Training-Free Few-Shot Classification with CLIP
Dec 16, 2024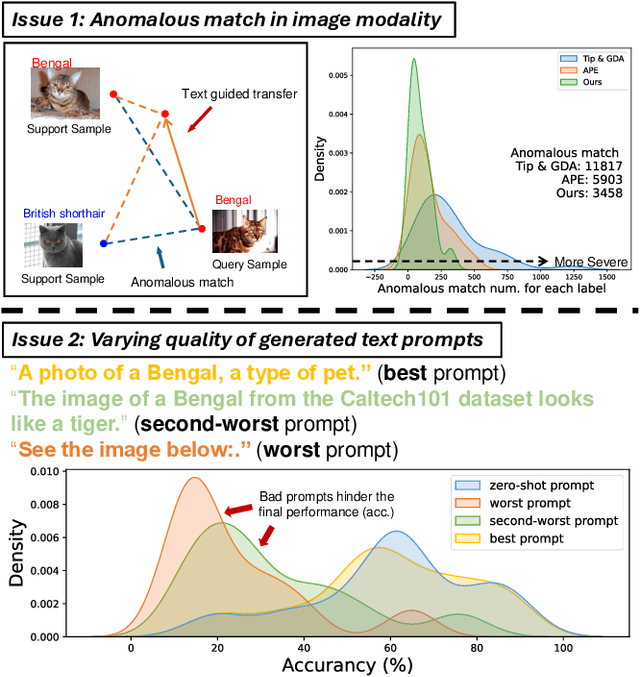
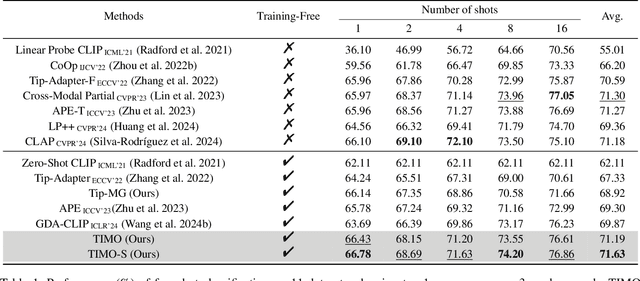
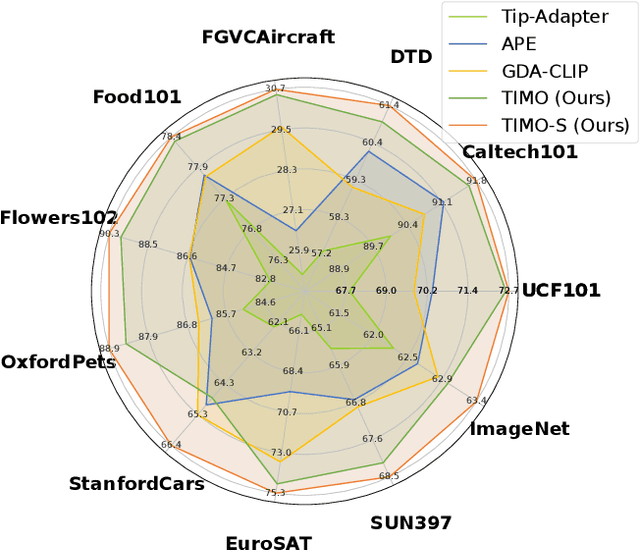

Contrastive Language-Image Pretraining (CLIP) has been widely used in vision tasks. Notably, CLIP has demonstrated promising performance in few-shot learning (FSL). However, existing CLIP-based methods in training-free FSL (i.e., without the requirement of additional training) mainly learn different modalities independently, leading to two essential issues: 1) severe anomalous match in image modality; 2) varying quality of generated text prompts. To address these issues, we build a mutual guidance mechanism, that introduces an Image-Guided-Text (IGT) component to rectify varying quality of text prompts through image representations, and a Text-Guided-Image (TGI) component to mitigate the anomalous match of image modality through text representations. By integrating IGT and TGI, we adopt a perspective of Text-Image Mutual guidance Optimization, proposing TIMO. Extensive experiments show that TIMO significantly outperforms the state-of-the-art (SOTA) training-free method. Additionally, by exploring the extent of mutual guidance, we propose an enhanced variant, TIMO-S, which even surpasses the best training-required methods by 0.33% with approximately 100 times less time cost. Our code is available at https://github.com/lyymuwu/TIMO.
START: A Generalized State Space Model with Saliency-Driven Token-Aware Transformation
Oct 21, 2024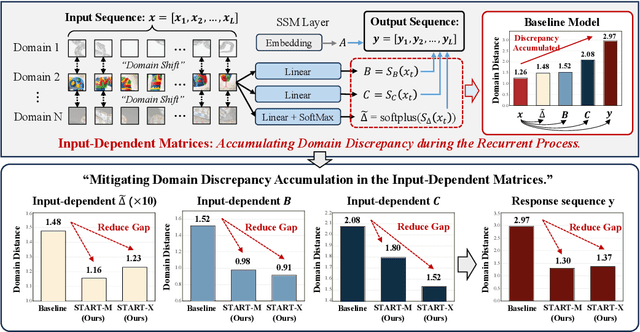
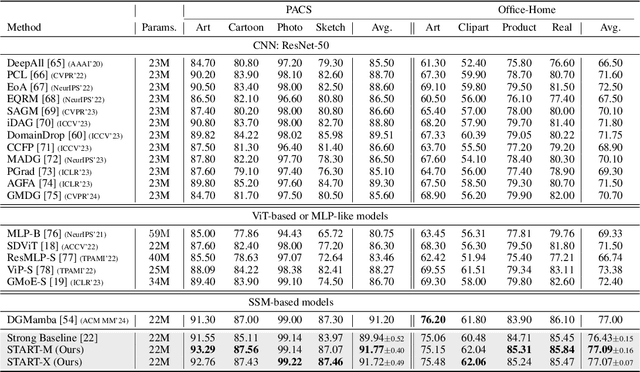
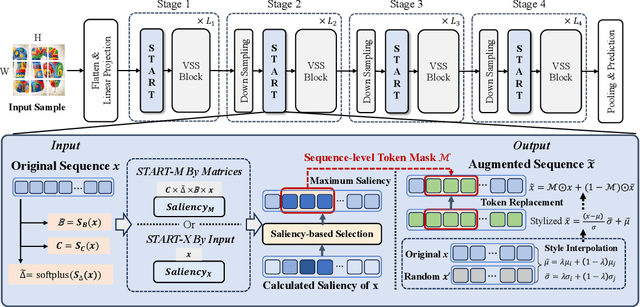
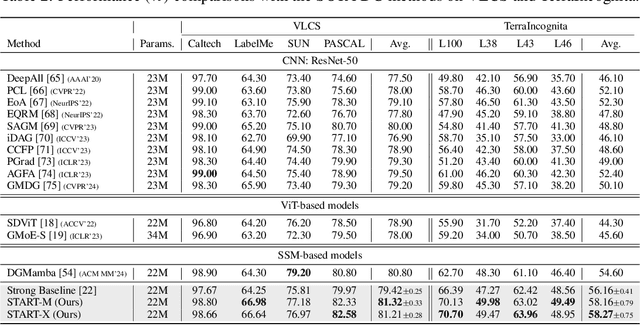
Domain Generalization (DG) aims to enable models to generalize to unseen target domains by learning from multiple source domains. Existing DG methods primarily rely on convolutional neural networks (CNNs), which inherently learn texture biases due to their limited receptive fields, making them prone to overfitting source domains. While some works have introduced transformer-based methods (ViTs) for DG to leverage the global receptive field, these methods incur high computational costs due to the quadratic complexity of self-attention. Recently, advanced state space models (SSMs), represented by Mamba, have shown promising results in supervised learning tasks by achieving linear complexity in sequence length during training and fast RNN-like computation during inference. Inspired by this, we investigate the generalization ability of the Mamba model under domain shifts and find that input-dependent matrices within SSMs could accumulate and amplify domain-specific features, thus hindering model generalization. To address this issue, we propose a novel SSM-based architecture with saliency-based token-aware transformation (namely START), which achieves state-of-the-art (SOTA) performances and offers a competitive alternative to CNNs and ViTs. Our START can selectively perturb and suppress domain-specific features in salient tokens within the input-dependent matrices of SSMs, thus effectively reducing the discrepancy between different domains. Extensive experiments on five benchmarks demonstrate that START outperforms existing SOTA DG methods with efficient linear complexity. Our code is available at https://github.com/lingeringlight/START.
SETA: Semantic-Aware Token Augmentation for Domain Generalization
Mar 18, 2024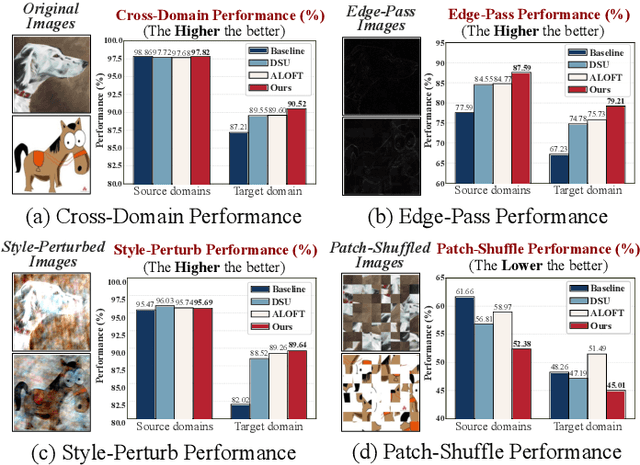
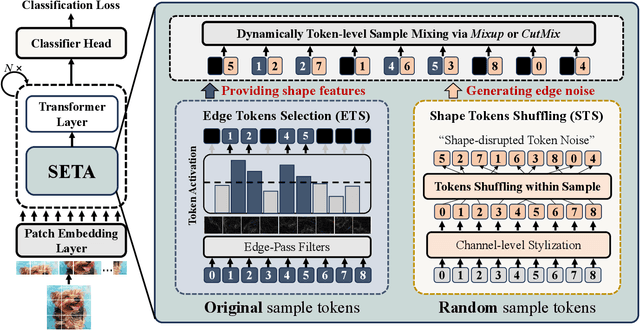
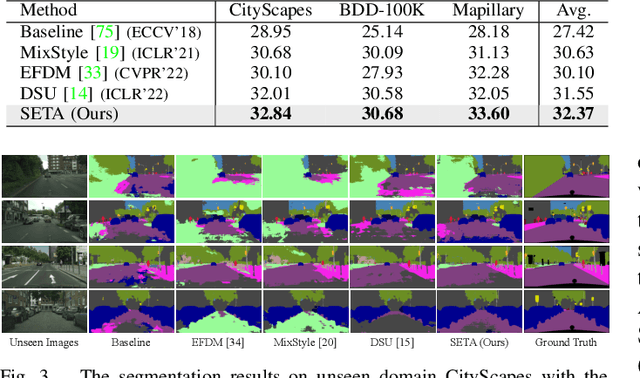
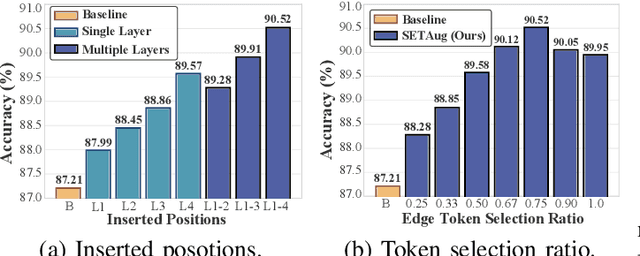
Domain generalization (DG) aims to enhance the model robustness against domain shifts without accessing target domains. A prevalent category of methods for DG is data augmentation, which focuses on generating virtual samples to simulate domain shifts. However, existing augmentation techniques in DG are mainly tailored for convolutional neural networks (CNNs), with limited exploration in token-based architectures, i.e., vision transformer (ViT) and multi-layer perceptrons (MLP) models. In this paper, we study the impact of prior CNN-based augmentation methods on token-based models, revealing their performance is suboptimal due to the lack of incentivizing the model to learn holistic shape information. To tackle the issue, we propose the SEmantic-aware Token Augmentation (SETA) method. SETA transforms token features by perturbing local edge cues while preserving global shape features, thereby enhancing the model learning of shape information. To further enhance the generalization ability of the model, we introduce two stylized variants of our method combined with two state-of-the-art style augmentation methods in DG. We provide a theoretical insight into our method, demonstrating its effectiveness in reducing the generalization risk bound. Comprehensive experiments on five benchmarks prove that our method achieves SOTA performances across various ViT and MLP architectures. Our code is available at https://github.com/lingeringlight/SETA.
Learning Generalizable Models via Disentangling Spurious and Enhancing Potential Correlations
Jan 11, 2024Domain generalization (DG) intends to train a model on multiple source domains to ensure that it can generalize well to an arbitrary unseen target domain. The acquisition of domain-invariant representations is pivotal for DG as they possess the ability to capture the inherent semantic information of the data, mitigate the influence of domain shift, and enhance the generalization capability of the model. Adopting multiple perspectives, such as the sample and the feature, proves to be effective. The sample perspective facilitates data augmentation through data manipulation techniques, whereas the feature perspective enables the extraction of meaningful generalization features. In this paper, we focus on improving the generalization ability of the model by compelling it to acquire domain-invariant representations from both the sample and feature perspectives by disentangling spurious correlations and enhancing potential correlations. 1) From the sample perspective, we develop a frequency restriction module, guiding the model to focus on the relevant correlations between object features and labels, thereby disentangling spurious correlations. 2) From the feature perspective, the simple Tail Interaction module implicitly enhances potential correlations among all samples from all source domains, facilitating the acquisition of domain-invariant representations across multiple domains for the model. The experimental results show that Convolutional Neural Networks (CNNs) or Multi-Layer Perceptrons (MLPs) with a strong baseline embedded with these two modules can achieve superior results, e.g., an average accuracy of 92.30% on Digits-DG.