 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwT-v2: Practical, Effective and Efficient Post-Training Quantization
May 27, 2025Network quantization is arguably one of the most practical network compression approaches for reducing the enormous resource consumption of modern deep neural networks. They usually require diverse and subtle design choices for specific architecture and tasks. Instead, the QwT method is a simple and general approach which introduces lightweight additional structures to improve quantization. But QwT incurs extra parameters and latency. More importantly, QwT is not compatible with many hardware platforms. In this paper, we propose QwT-v2, which not only enjoys all advantages of but also resolves major defects of QwT. By adopting a very lightweight channel-wise affine compensation (CWAC) module, QwT-v2 introduces significantly less extra parameters and computations compared to QwT, and at the same time matches or even outperforms QwT in accuracy. The compensation module of QwT-v2 can be integrated into quantization inference engines with little effort, which not only effectively removes the extra costs but also makes it compatible with most existing hardware platforms.
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
May 05, 2025

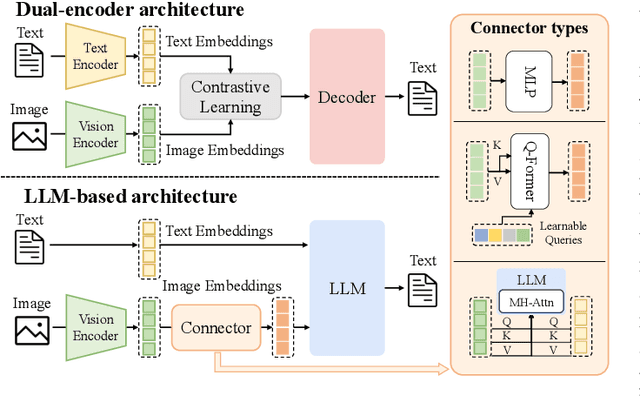

Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o's new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey will be available on GitHub soon.
Infant Cry Detection Using Causal Temporal Representation
Mar 08, 2025This paper addresses a major challenge in acoustic event detection, in particular infant cry detection in the presence of other sounds and background noises: the lack of precise annotated data. We present two contributions for supervised and unsupervised infant cry detection. The first is an annotated dataset for cry segmentation, which enables supervised models to achieve state-of-the-art performance. Additionally, we propose a novel unsupervised method, Causal Representation Spare Transition Clustering (CRSTC), based on causal temporal representation, which helps address the issue of data scarcity more generally. By integrating the detected cry segments, we significantly improve the performance of downstream infant cry classification, highlighting the potential of this approach for infant care applications.
CHATS: Combining Human-Aligned Optimization and Test-Time Sampling for Text-to-Image Generation
Feb 18, 2025



Diffusion models have emerged as a dominant approach for text-to-image generation. Key components such as the human preference alignment and classifier-free guidance play a crucial role in ensuring generation quality. However, their independent application in current text-to-image models continues to face significant challenges in achieving strong text-image alignment, high generation quality, and consistency with human aesthetic standards. In this work, we for the first time, explore facilitating the collaboration of human performance alignment and test-time sampling to unlock the potential of text-to-image models. Consequently, we introduce CHATS (Combining Human-Aligned optimization and Test-time Sampling), a novel generative framework that separately models the preferred and dispreferred distributions and employs a proxy-prompt-based sampling strategy to utilize the useful information contained in both distributions. We observe that CHATS exhibits exceptional data efficiency, achieving strong performance with only a small, high-quality funetuning dataset. Extensive experiments demonstrate that CHATS surpasses traditional preference alignment methods, setting new state-of-the-art across various standard benchmarks.
Quantization without Tears
Nov 22, 2024



Deep neural networks, while achieving remarkable success across diverse tasks, demand significant resources, including computation, GPU memory, bandwidth, storage, and energy. Network quantization, as a standard compression and acceleration technique, reduces storage costs and enables potential inference acceleration by discretizing network weights and activations into a finite set of integer values. However, current quantization methods are often complex and sensitive, requiring extensive task-specific hyperparameters, where even a single misconfiguration can impair model performance, limiting generality across different models and tasks. In this paper, we propose Quantization without Tears (QwT), a method that simultaneously achieves quantization speed, accuracy, simplicity, and generality. The key insight of QwT is to incorporate a lightweight additional structure into the quantized network to mitigate information loss during quantization. This structure consists solely of a small set of linear layers, keeping the method simple and efficient. More importantly, it provides a closed-form solution, allowing us to improve accuracy effortlessly under 2 minutes. Extensive experiments across various vision, language, and multimodal tasks demonstrate that QwT is both highly effective and versatile. In fact, our approach offers a robust solution for network quantization that combines simplicity, accuracy, and adaptability, which provides new insights for the design of novel quantization paradigms.
Benchmarking Sub-Genre Classification For Mainstage Dance Music
Sep 10, 2024



Music classification, with a wide range of applications, is one of the most prominent tasks in music information retrieval. To address the absence of comprehensive datasets and high-performing methods in the classification of mainstage dance music, this work introduces a novel benchmark comprising a new dataset and a baseline. Our dataset extends the number of sub-genres to cover most recent mainstage live sets by top DJs worldwide in music festivals. A continuous soft labeling approach is employed to account for tracks that span multiple sub-genres, preserving the inherent sophistication. For the baseline, we developed deep learning models that outperform current state-of-the-art multimodel language models, which struggle to identify house music sub-genres, emphasizing the need for specialized models trained on fine-grained datasets. Our benchmark is applicable to serve for application scenarios such as music recommendation, DJ set curation, and interactive multimedia, where we also provide video demos. Our code is on \url{https://anonymous.4open.science/r/Mainstage-EDM-Benchmark/}.
Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation
Jun 26, 2024The rapid scaling of large vision pretrained models makes fine-tuning tasks more and more difficult on edge devices with low computational resources. We explore a new visual adaptation paradigm called edge tuning, which treats large pretrained models as standalone feature extractors that run on powerful cloud servers. The fine-tuning carries out on edge devices with small networks which require low computational resources. Existing methods that are potentially suitable for our edge tuning paradigm are discussed. But, three major drawbacks hinder their application in edge tuning: low adaptation capability, large adapter network, and high information transfer overhead. To address these issues, we propose Minimal Interaction Edge Tuning, or MIET, which reveals that the sum of intermediate features from pretrained models not only has minimal information transfer but also has high adaptation capability. With a lightweight attention-based adaptor network, MIET achieves information transfer efficiency, parameter efficiency, computational and memory efficiency, and at the same time demonstrates competitive results on various visual adaptation benchmarks.
Unified Low-rank Compression Framework for Click-through Rate Prediction
May 28, 2024



Deep Click-Through Rate (CTR) prediction models play an important role in modern industrial recommendation scenarios. However, high memory overhead and computational costs limit their deployment in resource-constrained environments. Low-rank approximation is an effective method for computer vision and natural language processing models, but its application in compressing CTR prediction models has been less explored. Due to the limited memory and computing resources, compression of CTR prediction models often confronts three fundamental challenges, i.e., (1). How to reduce the model sizes to adapt to edge devices? (2). How to speed up CTR prediction model inference? (3). How to retain the capabilities of original models after compression? Previous low-rank compression research mostly uses tensor decomposition, which can achieve a high parameter compression ratio, but brings in AUC degradation and additional computing overhead. To address these challenges, we propose a unified low-rank decomposition framework for compressing CTR prediction models. We find that even with the most classic matrix decomposition SVD method, our framework can achieve better performance than the original model. To further improve the effectiveness of our framework, we locally compress the output features instead of compressing the model weights. Our unified low-rank compression framework can be applied to embedding tables and MLP layers in various CTR prediction models. Extensive experiments on two academic datasets and one real industrial benchmark demonstrate that, with 3-5x model size reduction, our compressed models can achieve both faster inference and higher AUC than the uncompressed original models. Our code is at https://github.com/yuhao318/Atomic_Feature_Mimicking.
Low-rank Attention Side-Tuning for Parameter-Efficient Fine-Tuning
Feb 06, 2024In finetuning a large pretrained model to downstream tasks, parameter-efficient fine-tuning (PEFT) methods can effectively finetune pretrained models with few trainable parameters, but suffer from high GPU memory consumption and slow training speed. Because learnable parameters from these methods are entangled with the pretrained model, gradients related to the frozen pretrained model's parameters have to be computed and stored during finetuning. We propose Low-rank Attention Side-Tuning (LAST), which disentangles the trainable module from the pretrained model by freezing not only parameters but also outputs of the pretrained network. LAST trains a side-network composed of only low-rank self-attention modules. By viewing the pretrained model as a frozen feature extractor, the side-network takes intermediate output from the pretrained model and focus on learning task-specific knowledge. We also show that LAST can be highly parallel across multiple optimization objectives, making it very efficient in downstream task adaptation, for example, in finding optimal hyperparameters. LAST outperforms previous state-of-the-art methods on VTAB-1K and other visual adaptation tasks with roughly only 30\% of GPU memory footprint and 60\% of training time compared to existing PEFT methods, but achieves significantly higher accuracy.
Rectify the Regression Bias in Long-Tailed Object Detection
Jan 31, 2024



Long-tailed object detection faces great challenges because of its extremely imbalanced class distribution. Recent methods mainly focus on the classification bias and its loss function design, while ignoring the subtle influence of the regression branch. This paper shows that the regression bias exists and does adversely and seriously impact the detection accuracy. While existing methods fail to handle the regression bias, the class-specific regression head for rare classes is hypothesized to be the main cause of it in this paper. As a result, three kinds of viable solutions to cater for the rare categories are proposed, including adding a class-agnostic branch, clustering heads and merging heads. The proposed methods brings in consistent and significant improvements over existing long-tailed detection methods, especially in rare and common classes. The proposed method achieves state-of-the-art performance in the large vocabulary LVIS dataset with different backbones and architectures. It generalizes well to more difficult evaluation metrics, relatively balanced datasets, and the mask branch. This is the first attempt to reveal and explore rectifying of the regression bias in long-tailed object detection.