 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Representation Model of SAR Saturated Interference: Mechanism and Verification
Jul 09, 2025Synthetic Aperture Radar (SAR) is highly susceptible to Radio Frequency Interference (RFI). Due to the performance limitations of components such as gain controllers and analog-to-digital converters in SAR receivers, high-power interference can easily cause saturation of the SAR receiver, resulting in nonlinear distortion of the interfered echoes, which are distorted in both the time domain and frequency domain. Some scholars have analyzed the impact of SAR receiver saturation on target echoes through simulations. However, the saturation function has non-smooth characteristics, making it difficult to conduct accurate analysis using traditional analytical methods. Current related studies have approximated and analyzed the saturation function based on the hyperbolic tangent function, but there are approximation errors. Therefore, this paper proposes a saturation interference analysis model based on Bessel functions, and verifies the accuracy of the proposed saturation interference analysis model by simulating and comparing it with the traditional saturation model based on smooth function approximation. This model can provide certain guidance for further work such as saturation interference suppression.
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
May 05, 2025Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o's new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey will be available on GitHub soon.
UNIC-Adapter: Unified Image-instruction Adapter with Multi-modal Transformer for Image Generation
Dec 25, 2024



Recently, text-to-image generation models have achieved remarkable advancements, particularly with diffusion models facilitating high-quality image synthesis from textual descriptions. However, these models often struggle with achieving precise control over pixel-level layouts, object appearances, and global styles when using text prompts alone. To mitigate this issue, previous works introduce conditional images as auxiliary inputs for image generation, enhancing control but typically necessitating specialized models tailored to different types of reference inputs. In this paper, we explore a new approach to unify controllable generation within a single framework. Specifically, we propose the unified image-instruction adapter (UNIC-Adapter) built on the Multi-Modal-Diffusion Transformer architecture, to enable flexible and controllable generation across diverse conditions without the need for multiple specialized models. Our UNIC-Adapter effectively extracts multi-modal instruction information by incorporating both conditional images and task instructions, injecting this information into the image generation process through a cross-attention mechanism enhanced by Rotary Position Embedding. Experimental results across a variety of tasks, including pixel-level spatial control, subject-driven image generation, and style-image-based image synthesis, demonstrate the effectiveness of our UNIC-Adapter in unified controllable image generation.
Local-consistent Transformation Learning for Rotation-invariant Point Cloud Analysis
Mar 17, 2024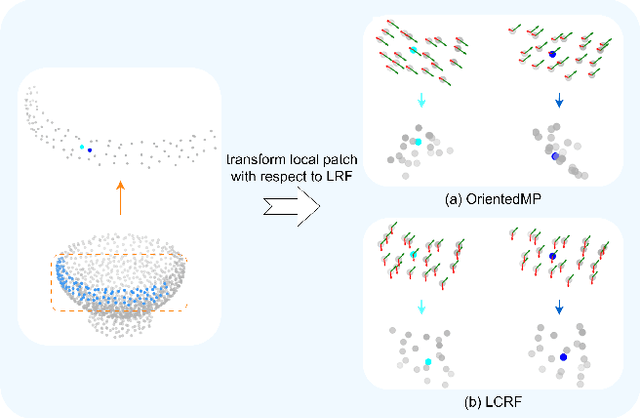
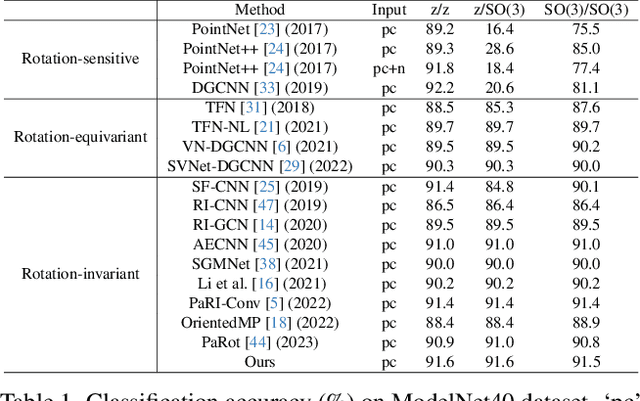
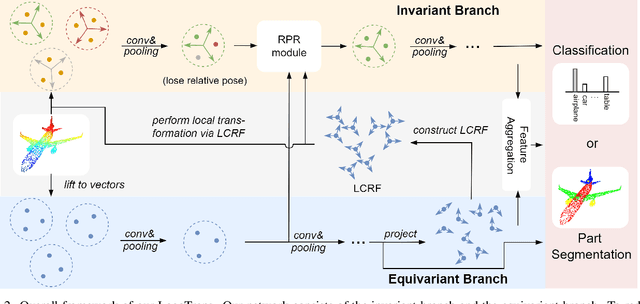
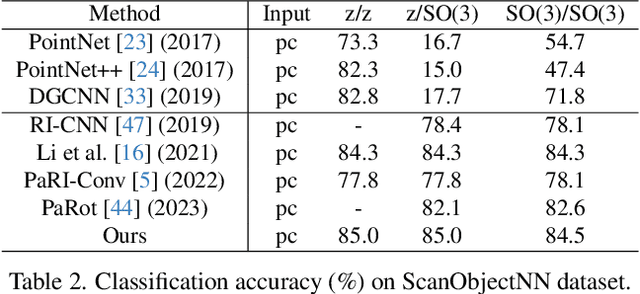
Rotation invariance is an important requirement for point shape analysis. To achieve this, current state-of-the-art methods attempt to construct the local rotation-invariant representation through learning or defining the local reference frame (LRF). Although efficient, these LRF-based methods suffer from perturbation of local geometric relations, resulting in suboptimal local rotation invariance. To alleviate this issue, we propose a Local-consistent Transformation (LocoTrans) learning strategy. Specifically, we first construct the local-consistent reference frame (LCRF) by considering the symmetry of the two axes in LRF. In comparison with previous LRFs, our LCRF is able to preserve local geometric relationships better through performing local-consistent transformation. However, as the consistency only exists in local regions, the relative pose information is still lost in the intermediate layers of the network. We mitigate such a relative pose issue by developing a relative pose recovery (RPR) module. RPR aims to restore the relative pose between adjacent transformed patches. Equipped with LCRF and RPR, our LocoTrans is capable of learning local-consistent transformation and preserving local geometry, which benefits rotation invariance learning. Competitive performance under arbitrary rotations on both shape classification and part segmentation tasks and ablations can demonstrate the effectiveness of our method. Code will be available publicly at https://github.com/wdttt/LocoTrans.
ConDaFormer: Disassembled Transformer with Local Structure Enhancement for 3D Point Cloud Understanding
Dec 18, 2023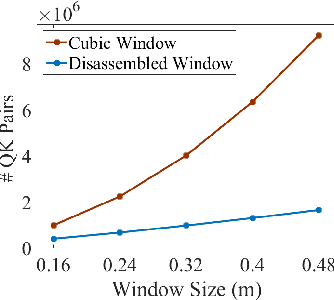
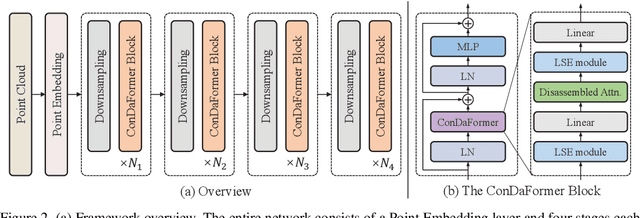
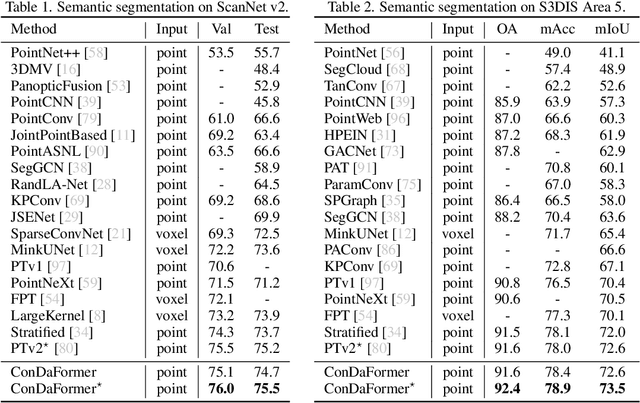
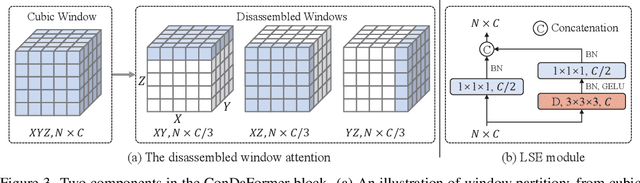
Transformers have been recently explored for 3D point cloud understanding with impressive progress achieved. A large number of points, over 0.1 million, make the global self-attention infeasible for point cloud data. Thus, most methods propose to apply the transformer in a local region, e.g., spherical or cubic window. However, it still contains a large number of Query-Key pairs, which requires high computational costs. In addition, previous methods usually learn the query, key, and value using a linear projection without modeling the local 3D geometric structure. In this paper, we attempt to reduce the costs and model the local geometry prior by developing a new transformer block, named ConDaFormer. Technically, ConDaFormer disassembles the cubic window into three orthogonal 2D planes, leading to fewer points when modeling the attention in a similar range. The disassembling operation is beneficial to enlarging the range of attention without increasing the computational complexity, but ignores some contexts. To provide a remedy, we develop a local structure enhancement strategy that introduces a depth-wise convolution before and after the attention. This scheme can also capture the local geometric information. Taking advantage of these designs, ConDaFormer captures both long-range contextual information and local priors. The effectiveness is demonstrated by experimental results on several 3D point cloud understanding benchmarks. Code is available at https://github.com/LHDuan/ConDaFormer .