 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIC-Adapter: Unified Image-instruction Adapter with Multi-modal Transformer for Image Generation
Dec 25, 2024



Recently, text-to-image generation models have achieved remarkable advancements, particularly with diffusion models facilitating high-quality image synthesis from textual descriptions. However, these models often struggle with achieving precise control over pixel-level layouts, object appearances, and global styles when using text prompts alone. To mitigate this issue, previous works introduce conditional images as auxiliary inputs for image generation, enhancing control but typically necessitating specialized models tailored to different types of reference inputs. In this paper, we explore a new approach to unify controllable generation within a single framework. Specifically, we propose the unified image-instruction adapter (UNIC-Adapter) built on the Multi-Modal-Diffusion Transformer architecture, to enable flexible and controllable generation across diverse conditions without the need for multiple specialized models. Our UNIC-Adapter effectively extracts multi-modal instruction information by incorporating both conditional images and task instructions, injecting this information into the image generation process through a cross-attention mechanism enhanced by Rotary Position Embedding. Experimental results across a variety of tasks, including pixel-level spatial control, subject-driven image generation, and style-image-based image synthesis, demonstrate the effectiveness of our UNIC-Adapter in unified controllable image generation.
The Domain Shift Problem of Medical Image Segmentation and Vendor-Adaptation by Unet-GAN
Oct 30, 2019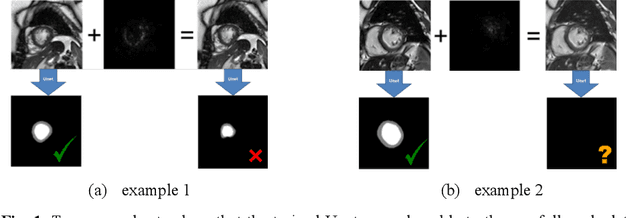
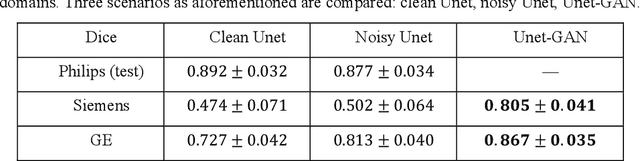

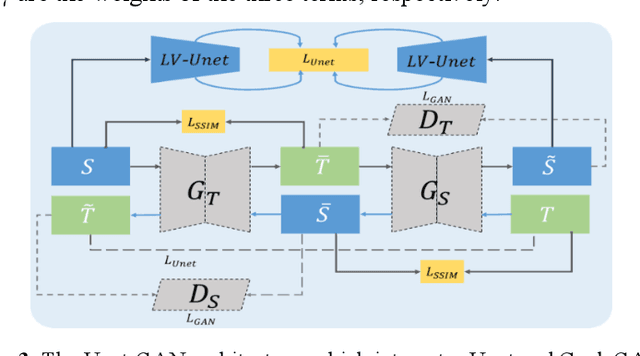
Convolutional neural network (CNN), in particular the Unet, is a powerful method for medical image segmentation. To date Unet has demonstrated state-of-art performance in many complex medical image segmentation tasks, especially under the condition when the training and testing data share the same distribution (i.e. come from the same source domain). However, in clinical practice, medical images are acquired from different vendors and centers. The performance of a U-Net trained from a particular source domain, when transferred to a different target domain (e.g. different vendor, acquisition parameter), can drop unexpectedly. Collecting a large amount of annotation from each new domain to retrain the U-Net is expensive, tedious, and practically impossible. In this work, we proposed a generic framework to address this problem, consisting of (1) an unpaired generative adversarial network (GAN) for vendor-adaptation, and (2) a Unet for object segmentation. In the proposed Unet-GAN architecture, GAN learns from Unet at the feature level that is segmentation-specific. We used cardiac cine MRI as the example, with three major vendors (Philips, Siemens, and GE) as three domains, while the methodology can be extended to medical images segmentation in general. The proposed method showed significant improvement of the segmentation results across vendors. The proposed Unet-GAN provides an annotation-free solution to the cross-vendor medical image segmentation problem, potentially extending a trained deep learning model to multi-center and multi-vendor use in real clinical scenario.
Convolutional Neural Networks for Space-Time Block Coding Recognition
Oct 19, 2019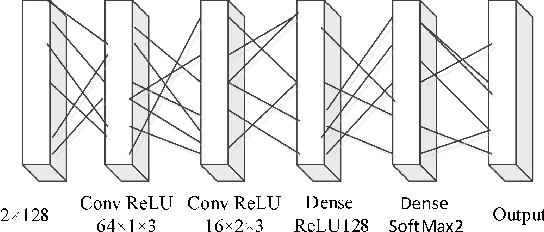
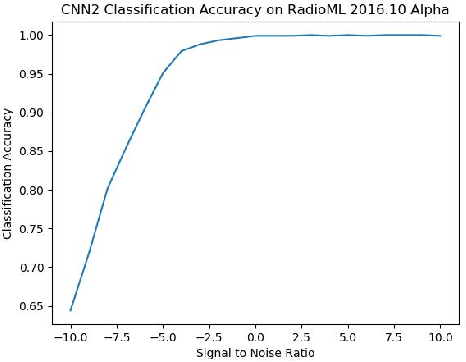
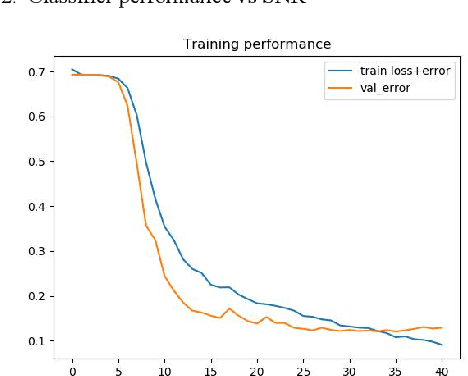
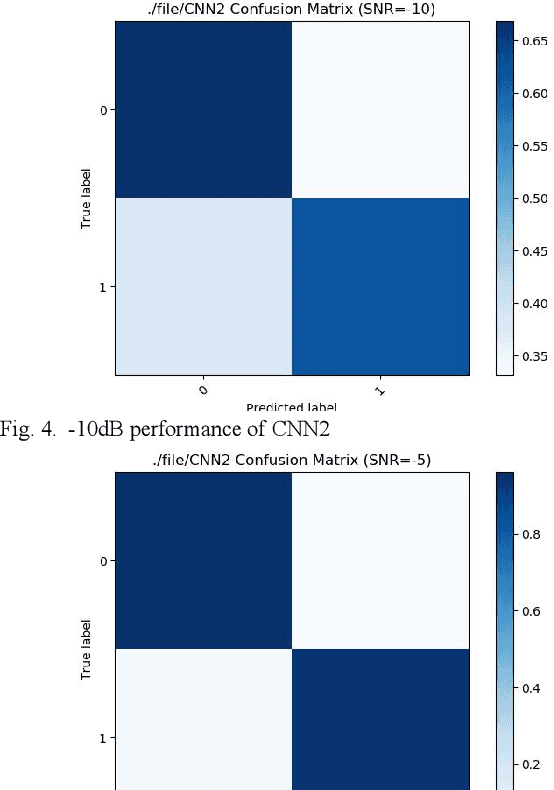
We find that the latest advances in machine learning with deep neural network by applying them to the task of radio modulation recognition, channel coding recognition, and spectrum monitor. This paper first proposes a novel identification algorithm for Space-Time Block coding(STBC) signal. The feature between Spatial Multiplexing (SM) and Alamouti (AL) signals is extracted via adapting convolutional neural networks after preprocessing the received sequence. Unlike other algorithms, this method does not require any prior information of channel coefficient, and noise power and, consequently, is well-suited for non-cooperative context. Results show that the proposed algorithm performs well even at a low signal to noise ratio (SNR).
Left Ventricle Segmentation via Optical-Flow-Net from Short-axis Cine MRI: Preserving the Temporal Coherence of Cardiac Motion
Oct 20, 2018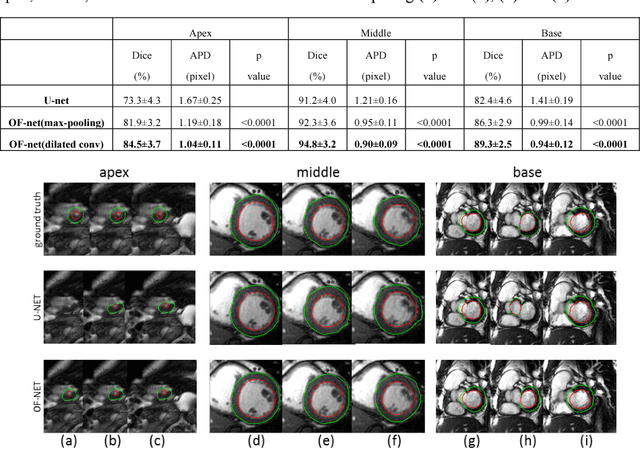
Quantitative assessment of left ventricle (LV) function from cine MRI has significant diagnostic and prognostic value for cardiovascular disease patients. The temporal movement of LV provides essential information on the contracting/relaxing pattern of heart, which is keenly evaluated by clinical experts in clinical practice. Inspired by the expert way of viewing Cine MRI, we propose a new CNN module that is able to incorporate the temporal information into LV segmentation from cine MRI. In the proposed CNN, the optical flow (OF) between neighboring frames is integrated and aggregated at feature level, such that temporal coherence in cardiac motion can be taken into account during segmentation. The proposed module is integrated into the U-net architecture without need of additional training. Furthermore, dilated convolution is introduced to improve the spatial accuracy of segmentation. Trained and tested on the Cardiac Atlas database, the proposed network resulted in a Dice index of 95% and an average perpendicular distance of 0.9 pixels for the middle LV contour, significantly outperforming the original U-net that processes each frame individually. Notably, the proposed method improved the temporal coherence of LV segmentation results, especially at the LV apex and base where the cardiac motion is difficult to follow.