 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025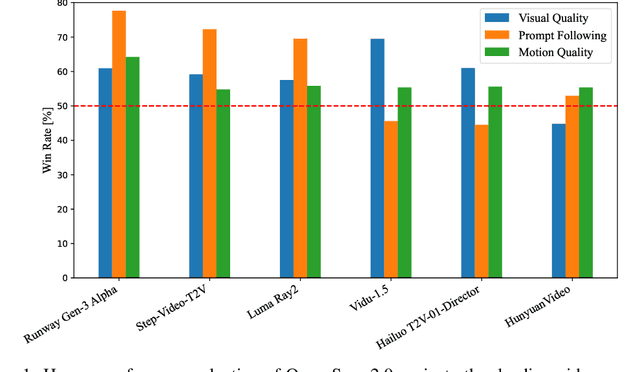

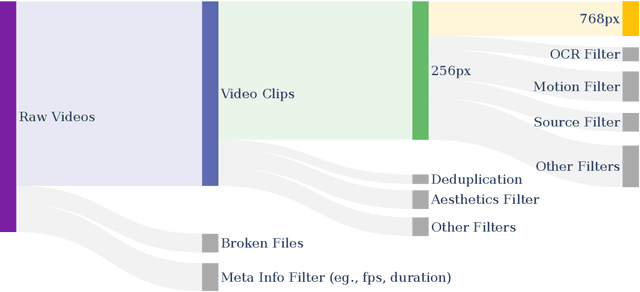

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
New Approaches for NLU based on Information Architecture
Nov 03, 2020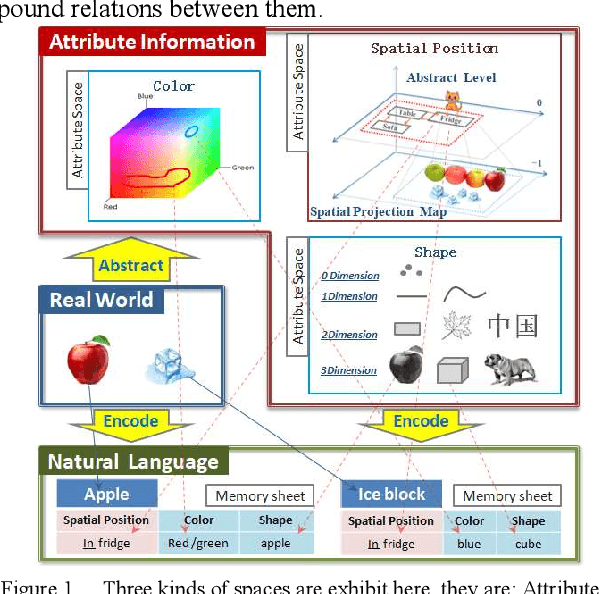

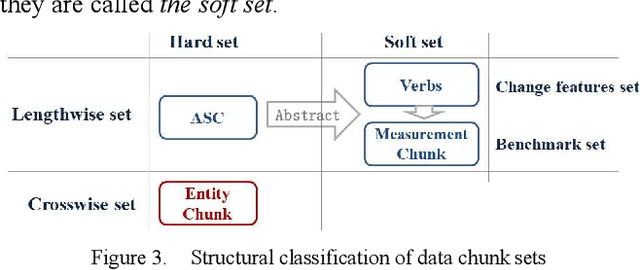
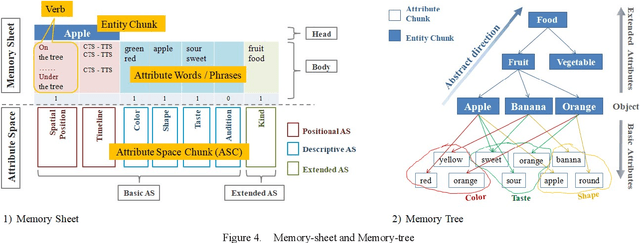
First of all, please forget all you knew about the lexical classification, then let's jump to the conclusion. This paper reclassified lexical chunks into data chunks, structure chunks, and pointer chunks. Almost all data chunks are information sets. According to the difference of the set structures, data chunks can be further divided into attribute chunks and entity chunks. According to the different abstraction level and method, attribute chunks can be further divided into basic attribute chunks, extended attribute chunks, and advanced attribute chunks. All of the above classification principles are structural and functionalbased discrimination, instead of artificially divide lexical chunks into a noun, adjective, pronouns, and so on. Now, let's back to the normal study process. The author believes natural language is one of the ways information is encoded and it has highly abstracted and conceptualized the information. Therefore the study begins with disassembling the information represented by natural language and then discovered the classification coding system of attribute information, and the abstraction relations between attribute information and entities in the real world. To have a clear and better discussion, the author constructed corresponding data storage models, and extract three kinds of data reading modes on those data storage models, they are the defining reading mode which is driven by the structural word: be, the set reading mode which is driven by the structural word: have, and the process reading mode which is driven by verbs. Sentences output by the above data reading modes can be further divided into the data description task, the data verification task, and the data search task, according to task types represented by these sentences ...
Convolutional Neural Networks for Space-Time Block Coding Recognition
Oct 19, 2019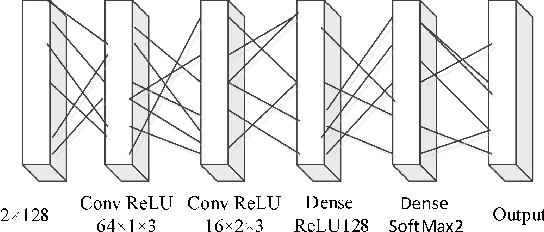
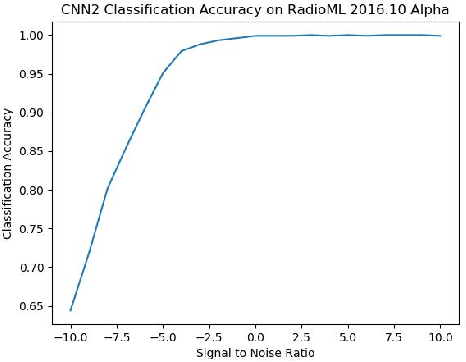
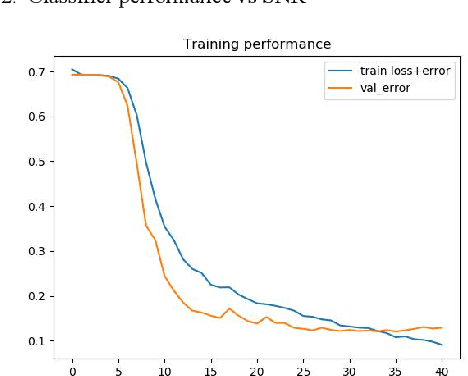
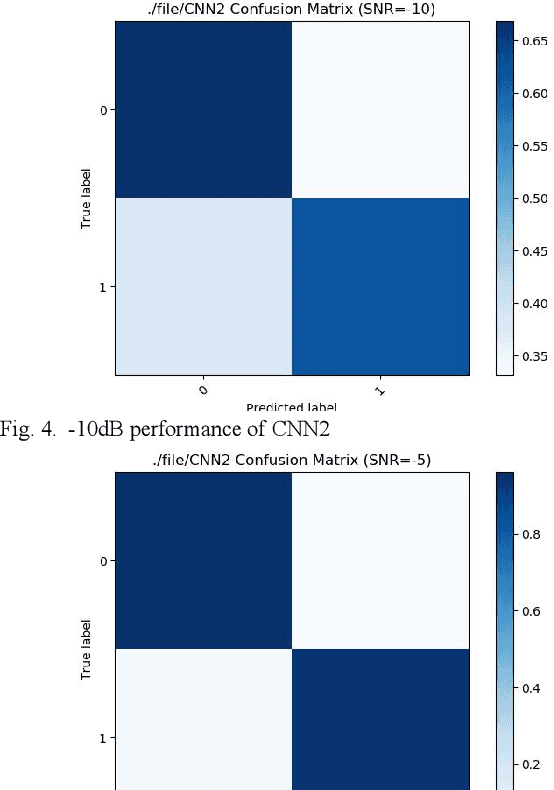
We find that the latest advances in machine learning with deep neural network by applying them to the task of radio modulation recognition, channel coding recognition, and spectrum monitor. This paper first proposes a novel identification algorithm for Space-Time Block coding(STBC) signal. The feature between Spatial Multiplexing (SM) and Alamouti (AL) signals is extracted via adapting convolutional neural networks after preprocessing the received sequence. Unlike other algorithms, this method does not require any prior information of channel coefficient, and noise power and, consequently, is well-suited for non-cooperative context. Results show that the proposed algorithm performs well even at a low signal to noise ratio (SNR).