 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Approaches for NLU based on Information Architecture
Paper and Code
Nov 03, 2020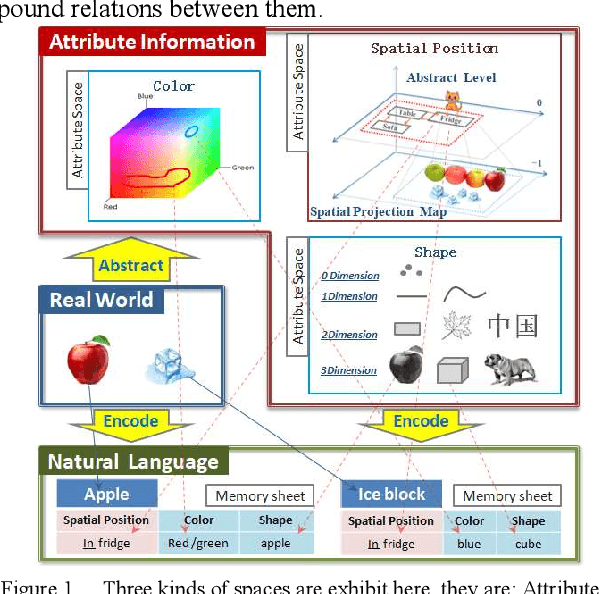

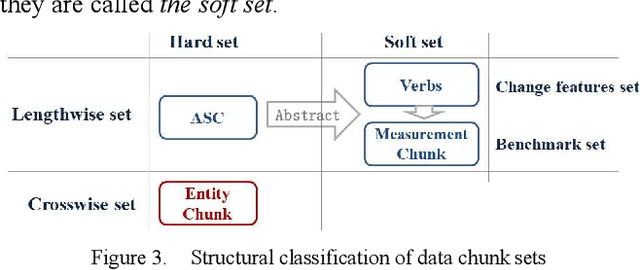
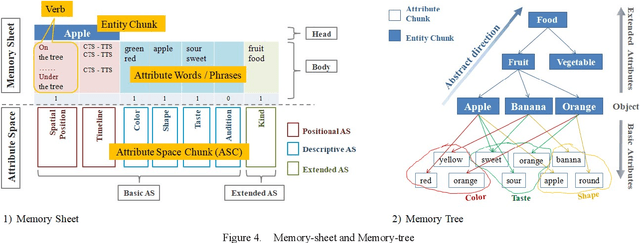
First of all, please forget all you knew about the lexical classification, then let's jump to the conclusion. This paper reclassified lexical chunks into data chunks, structure chunks, and pointer chunks. Almost all data chunks are information sets. According to the difference of the set structures, data chunks can be further divided into attribute chunks and entity chunks. According to the different abstraction level and method, attribute chunks can be further divided into basic attribute chunks, extended attribute chunks, and advanced attribute chunks. All of the above classification principles are structural and functionalbased discrimination, instead of artificially divide lexical chunks into a noun, adjective, pronouns, and so on. Now, let's back to the normal study process. The author believes natural language is one of the ways information is encoded and it has highly abstracted and conceptualized the information. Therefore the study begins with disassembling the information represented by natural language and then discovered the classification coding system of attribute information, and the abstraction relations between attribute information and entities in the real world. To have a clear and better discussion, the author constructed corresponding data storage models, and extract three kinds of data reading modes on those data storage models, they are the defining reading mode which is driven by the structural word: be, the set reading mode which is driven by the structural word: have, and the process reading mode which is driven by verbs. Sentences output by the above data reading modes can be further divided into the data description task, the data verification task, and the data search task, according to task types represented by these sentences ...