 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025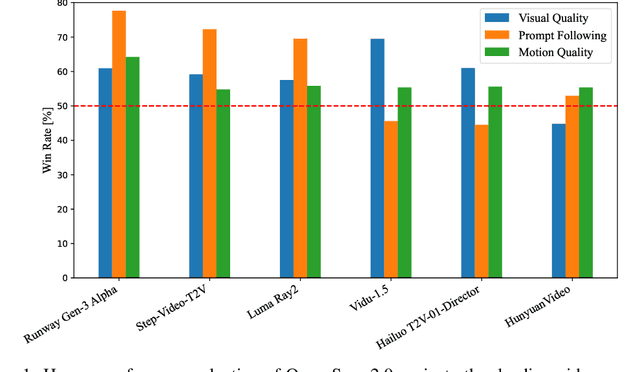


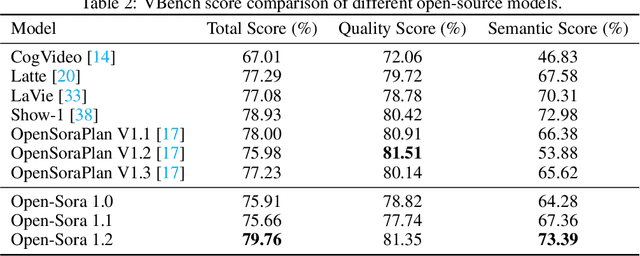
Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Open-Sora: Democratizing Efficient Video Production for All
Dec 29, 2024
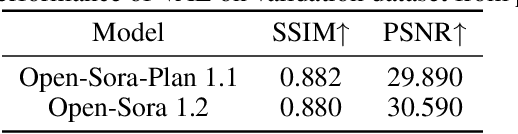
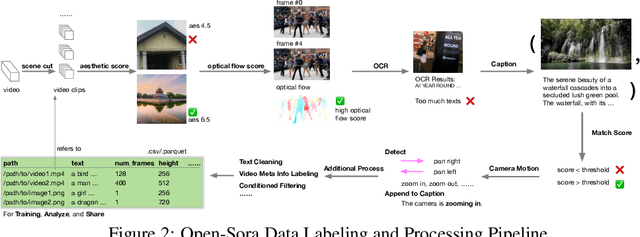
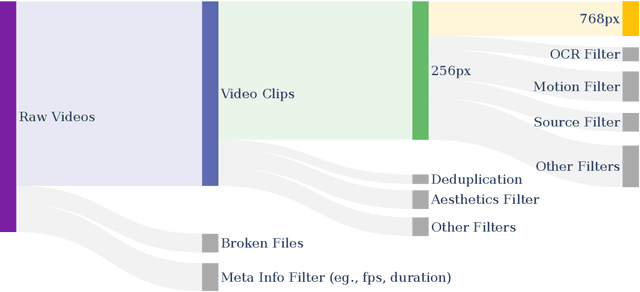
Vision and language are the two foundational senses for humans, and they build up our cognitive ability and intelligence. While significant breakthroughs have been made in AI language ability, artificial visual intelligence, especially the ability to generate and simulate the world we see, is far lagging behind. To facilitate the development and accessibility of artificial visual intelligence, we created Open-Sora, an open-source video generation model designed to produce high-fidelity video content. Open-Sora supports a wide spectrum of visual generation tasks, including text-to-image generation, text-to-video generation, and image-to-video generation. The model leverages advanced deep learning architectures and training/inference techniques to enable flexible video synthesis, which could generate video content of up to 15 seconds, up to 720p resolution, and arbitrary aspect ratios. Specifically, we introduce Spatial-Temporal Diffusion Transformer (STDiT), an efficient diffusion framework for videos that decouples spatial and temporal attention. We also introduce a highly compressive 3D autoencoder to make representations compact and further accelerate training with an ad hoc training strategy. Through this initiative, we aim to foster innovation, creativity, and inclusivity within the community of AI content creation. By embracing the open-source principle, Open-Sora democratizes full access to all the training/inference/data preparation codes as well as model weights. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Dataset Growth
May 28, 2024



Deep learning benefits from the growing abundance of available data. Meanwhile, efficiently dealing with the growing data scale has become a challenge. Data publicly available are from different sources with various qualities, and it is impractical to do manual cleaning against noise and redundancy given today's data scale. There are existing techniques for cleaning/selecting the collected data. However, these methods are mainly proposed for offline settings that target one of the cleanness and redundancy problems. In practice, data are growing exponentially with both problems. This leads to repeated data curation with sub-optimal efficiency. To tackle this challenge, we propose InfoGrowth, an efficient online algorithm for data cleaning and selection, resulting in a growing dataset that keeps up to date with awareness of cleanliness and diversity. InfoGrowth can improve data quality/efficiency on both single-modal and multi-modal tasks, with an efficient and scalable design. Its framework makes it practical for real-world data engines.
How Does the Textual Information Affect the Retrieval of Multimodal In-Context Learning?
Apr 19, 2024



The increase in parameter size of multimodal large language models (MLLMs) introduces significant capabilities, particularly in-context learning, where MLLMs enhance task performance without updating pre-trained parameters. This effectiveness, however, hinges on the appropriate selection of in-context examples, a process that is currently biased towards visual data, overlooking textual information. Furthermore, the area of supervised retrievers for MLLMs, crucial for optimal in-context example selection, continues to be uninvestigated. Our study offers an in-depth evaluation of the impact of textual information on the unsupervised selection of in-context examples in multimodal contexts, uncovering a notable sensitivity of retriever performance to the employed modalities. Responding to this, we introduce a novel supervised MLLM-retriever MSIER that employs a neural network to select examples that enhance multimodal in-context learning efficiency. This approach is validated through extensive testing across three distinct tasks, demonstrating the method's effectiveness. Additionally, we investigate the influence of modalities on our supervised retrieval method's training and pinpoint factors contributing to our model's success. This exploration paves the way for future advancements, highlighting the potential for refined in-context learning in MLLMs through the strategic use of multimodal data.
DSP: Dynamic Sequence Parallelism for Multi-Dimensional Transformers
Mar 15, 2024



Scaling large models with long sequences across applications like language generation, video generation and multimodal tasks requires efficient sequence parallelism. However, existing sequence parallelism methods all assume a single sequence dimension and fail to adapt to multi-dimensional transformer architectures that perform attention calculations across different dimensions. This paper introduces Dynamic Sequence Parallelism (DSP), a novel approach to enable efficient sequence parallelism for multi-dimensional transformer models. The key idea is to dynamically switch the parallelism dimension according to the current computation stage, leveraging the potential characteristics of multi-dimensional attention. This dynamic dimension switching allows sequence parallelism with minimal communication overhead compared to applying traditional single-dimension parallelism to multi-dimensional models. Experiments show DSP improves end-to-end throughput by 42.0% to 216.8% over prior sequence parallelism methods.
Helen: Optimizing CTR Prediction Models with Frequency-wise Hessian Eigenvalue Regularization
Feb 23, 2024



Click-Through Rate (CTR) prediction holds paramount significance in online advertising and recommendation scenarios. Despite the proliferation of recent CTR prediction models, the improvements in performance have remained limited, as evidenced by open-source benchmark assessments. Current researchers tend to focus on developing new models for various datasets and settings, often neglecting a crucial question: What is the key challenge that truly makes CTR prediction so demanding? In this paper, we approach the problem of CTR prediction from an optimization perspective. We explore the typical data characteristics and optimization statistics of CTR prediction, revealing a strong positive correlation between the top hessian eigenvalue and feature frequency. This correlation implies that frequently occurring features tend to converge towards sharp local minima, ultimately leading to suboptimal performance. Motivated by the recent advancements in sharpness-aware minimization (SAM), which considers the geometric aspects of the loss landscape during optimization, we present a dedicated optimizer crafted for CTR prediction, named Helen. Helen incorporates frequency-wise Hessian eigenvalue regularization, achieved through adaptive perturbations based on normalized feature frequencies. Empirical results under the open-source benchmark framework underscore Helen's effectiveness. It successfully constrains the top eigenvalue of the Hessian matrix and demonstrates a clear advantage over widely used optimization algorithms when applied to seven popular models across three public benchmark datasets on BARS. Our code locates at github.com/NUS-HPC-AI-Lab/Helen.
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models
Jan 29, 2024



To help the open-source community have a better understanding of Mixture-of-Experts (MoE) based large language models (LLMs), we train and release OpenMoE, a series of fully open-sourced and reproducible decoder-only MoE LLMs, ranging from 650M to 34B parameters and trained on up to over 1T tokens. Our investigation confirms that MoE-based LLMs can offer a more favorable cost-effectiveness trade-off than dense LLMs, highlighting the potential effectiveness for future LLM development. One more important contribution of this study is an in-depth analysis of the routing mechanisms within our OpenMoE models, leading to three significant findings: Context-Independent Specialization, Early Routing Learning, and Drop-towards-the-End. We discovered that routing decisions in MoE models are predominantly based on token IDs, with minimal context relevance. The token-to-expert assignments are determined early in the pre-training phase and remain largely unchanged. This imperfect routing can result in performance degradation, particularly in sequential tasks like multi-turn conversations, where tokens appearing later in a sequence are more likely to be dropped. Finally, we rethink our design based on the above-mentioned observations and analysis. To facilitate future MoE LLM development, we propose potential strategies for mitigating the issues we found and further improving off-the-shelf MoE LLM designs.
CAME: Confidence-guided Adaptive Memory Efficient Optimization
Jul 05, 2023



Adaptive gradient methods, such as Adam and LAMB, have demonstrated excellent performance in the training of large language models. Nevertheless, the need for adaptivity requires maintaining second-moment estimates of the per-parameter gradients, which entails a high cost of extra memory overheads. To solve this problem, several memory-efficient optimizers (e.g., Adafactor) have been proposed to obtain a drastic reduction in auxiliary memory usage, but with a performance penalty. In this paper, we first study a confidence-guided strategy to reduce the instability of existing memory efficient optimizers. Based on this strategy, we propose CAME to simultaneously achieve two goals: fast convergence as in traditional adaptive methods, and low memory usage as in memory-efficient methods. Extensive experiments demonstrate the training stability and superior performance of CAME across various NLP tasks such as BERT and GPT-2 training. Notably, for BERT pre-training on the large batch size of 32,768, our proposed optimizer attains faster convergence and higher accuracy compared with the Adam optimizer. The implementation of CAME is publicly available.
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
May 22, 2023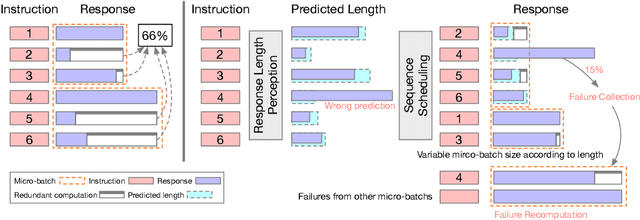



Large language models (LLMs) have revolutionized the field of AI, demonstrating unprecedented capacity across various tasks. However, the inference process for LLMs comes with significant computational costs. In this paper, we propose an efficient LLM inference pipeline that harnesses the power of LLMs. Our approach begins by tapping into the potential of LLMs to accurately perceive and predict the response length with minimal overhead. By leveraging this information, we introduce an efficient sequence scheduling technique that groups queries with similar response lengths into micro-batches. We evaluate our approach on real-world instruction datasets using the LLaMA-based model, and our results demonstrate an impressive 86% improvement in inference throughput without compromising effectiveness. Notably, our method is orthogonal to other inference acceleration techniques, making it a valuable addition to many existing toolkits (e.g., FlashAttention, Quantization) for LLM inference.
To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis
May 22, 2023Recent research has highlighted the importance of dataset size in scaling language models. However, large language models (LLMs) are notoriously token-hungry during pre-training, and high-quality text data on the web is approaching its scaling limit for LLMs. To further enhance LLMs, a straightforward approach is to repeat the pre-training data for additional epochs. In this study, we empirically investigate three key aspects under this approach. First, we explore the consequences of repeating pre-training data, revealing that the model is susceptible to overfitting, leading to multi-epoch degradation. Second, we examine the key factors contributing to multi-epoch degradation, finding that significant factors include dataset size, model parameters, and training objectives, while less influential factors consist of dataset quality and model FLOPs. Finally, we explore whether widely used regularization can alleviate multi-epoch degradation. Most regularization techniques do not yield significant improvements, except for dropout, which demonstrates remarkable effectiveness but requires careful tuning when scaling up the model size. Additionally, we discover that leveraging mixture-of-experts (MoE) enables cost-effective and efficient hyper-parameter tuning for computationally intensive dense LLMs with comparable trainable parameters, potentially impacting efficient LLM development on a broader scale.