 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precise Intent-Aligned VLA Aerial Navigation via Expert-Guided GRPO
Jun 01, 2026Vision-Language-Action (VLA) models offer a promising end-to-end paradigm for unmanned aerial vehicles (UAVs) to accomplish complex tasks specified by fine-grained instructions. However, standard supervised fine-tuning (SFT) suffers from data scarcity, limited generalization, and weak supervision for nuanced and complicated human intents. Reinforcement fine-tuning offers a natural way to mitigate these challenges and align policy behaviors with human intents through designable feedback, but applying it to aerial navigation remains challenging due to inefficient exploration in expansive continuous spaces. To address these challenges, we introduce an efficient reinforcement learning (RL) framework for VLA-based aerial navigation. At its core, we propose EG-GRPO (Expert-Guided Group Relative Policy Optimization) to augment online rollouts with few-shot expert data. Additionally, we design a heterogeneous pipeline enabling parallel simulation and inference, which reduces rollout time by 43.5%. Across multiple tasks specified by complex human intents, EG-GRPO improves the success rate to 2.13x that of the SFT baseline, while improving intent alignment performance by 60.9%. These results demonstrate that our framework can move aerial navigation toward precise intent-aligned flight.
HiSem: Hierarchical Semantic Disentangling for Remote Sensing Image Change Captioning
May 14, 2026Remote sensing image change captioning (RSICC) aims to achieve high-level semantic understanding of genuine changes occurring between bi-temporal images. Despite notable progress, existing methods are fundamentally limited by a shared modeling assumption: changed and unchanged image pairs, which have intrinsically different semantic granularities, are processed under a unified modeling strategy. This modeling inconsistency leads to semantic entanglement between coarse-grained change existence judgment and fine-grained semantic understanding.To address the above limitation, we propose a novel hierarchical semantic disentangling network (HiSem) that explicitly disentangles semantic representations of different granularities. Specifically, we first introduce the Bidirectional Differential Attention Modulation (BDAM) module that leverages discrepancy-aware attention to enhance cross-temporal interactions, thereby amplifying true change signals while suppressing irrelevant variations. Building upon this, we design a Hierarchical Adaptive Semantic Disentanglement (HASD) module that performs adaptive routing at two hierarchical levels: a coarse-grained image-level routing mechanism distinguishes changed and unchanged image pairs, while a fine-grained token-level Mixture-of-Experts (MoE) block models diverse and heterogeneous change semantics for changed samples. Extensive experiments on two benchmark datasets demonstrate that HiSem outperfoms previous methods, achieving a significant improvement of +7.52\% BLEU-4 on the WHU-CDC dataset. More importantly, our approach provides a structured perspective for RSICC by explicitly aligning model design with the intrinsic semantic heterogeneity of bi-temporal scenes. The code will be available at https://github.com/Man-Wang-star/HiSem
LeHome: A Simulation Environment for Deformable Object Manipulation in Household Scenarios
Apr 24, 2026Household environments present one of the most common, impactful yet challenging application domains for robotics. Within household scenarios, manipulating deformable objects is particularly difficult, both in simulation and real-world execution, due to varied categories and shapes, complex dynamics, and diverse material properties, as well as the lack of reliable deformable-object support in existing simulations. We introduce LeHome, a comprehensive simulation environment designed for deformable object manipulation in household scenarios. LeHome covers a wide spectrum of deformable objects, such as garments and food items, offering high-fidelity dynamics and realistic interactions that existing simulators struggle to simulate accurately. Moreover, LeHome supports multiple robotic embodiments and emphasizes low-cost robots as a core focus, enabling end-to-end evaluation of household tasks on resource-constrained hardware. By bridging the gap between realistic deformable object simulation and practical robotic platforms, LeHome provides a scalable testbed for advancing household robotics. Webpage: https://lehome-web.github.io/ .
HiMAP-Travel: Hierarchical Multi-Agent Planning for Long-Horizon Constrained Travel
Mar 05, 2026Sequential LLM agents fail on long-horizon planning with hard constraints like budgets and diversity requirements. As planning progresses and context grows, these agents drift from global constraints. We propose HiMAP-Travel, a hierarchical multi-agent framework that splits planning into strategic coordination and parallel day-level execution. A Coordinator allocates resources across days, while Day Executors plan independently in parallel. Three key mechanisms enable this: a transactional monitor enforcing budget and uniqueness constraints across parallel agents, a bargaining protocol allowing agents to reject infeasible sub-goals and trigger re-planning, and a single policy trained with GRPO that powers all agents through role conditioning. On TravelPlanner, HiMAP-Travel with Qwen3-8B achieves 52.78% validation and 52.65% test Final Pass Rate (FPR). In a controlled comparison with identical model, training, and tools, it outperforms the sequential DeepTravel baseline by +8.67~pp. It also surpasses ATLAS by +17.65~pp and MTP by +10.0~pp. On FlexTravelBench multi-turn scenarios, it achieves 44.34% (2-turn) and 37.42% (3-turn) FPR while reducing latency 2.5x through parallelization.
SRR-Judge: Step-Level Rating and Refinement for Enhancing Search-Integrated Reasoning in Search Agents
Feb 08, 2026Recent deep search agents built on large reasoning models (LRMs) excel at complex question answering by iteratively planning, acting, and gathering evidence, a capability known as search-integrated reasoning. However, mainstream approaches often train this ability using only outcome-based supervision, neglecting the quality of intermediate thoughts and actions. We introduce SRR-Judge, a framework for reliable step-level assessment of reasoning and search actions. Integrated into a modified ReAct-style rate-and-refine workflow, SRR-Judge provides fine-grained guidance for search-integrated reasoning and enables efficient post-training annotation. Using SRR-annotated data, we apply an iterative rejection sampling fine-tuning procedure to enhance the deep search capability of the base agent. Empirically, SRR-Judge delivers more reliable step-level evaluations than much larger models such as DeepSeek-V3.1, with its ratings showing strong correlation with final answer correctness. Moreover, aligning the policy with SRR-Judge annotated trajectories leads to substantial performance gains, yielding over a 10 percent average absolute pass@1 improvement across challenging deep search benchmarks.
VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
Dec 19, 2025



This paper proposes VLA-AN, an efficient and onboard Vision-Language-Action (VLA) framework dedicated to autonomous drone navigation in complex environments. VLA-AN addresses four major limitations of existing large aerial navigation models: the data domain gap, insufficient temporal navigation with reasoning, safety issues with generative action policies, and onboard deployment constraints. First, we construct a high-fidelity dataset utilizing 3D Gaussian Splatting (3D-GS) to effectively bridge the domain gap. Second, we introduce a progressive three-stage training framework that sequentially reinforces scene comprehension, core flight skills, and complex navigation capabilities. Third, we design a lightweight, real-time action module coupled with geometric safety correction. This module ensures fast, collision-free, and stable command generation, mitigating the safety risks inherent in stochastic generative policies. Finally, through deep optimization of the onboard deployment pipeline, VLA-AN achieves a robust real-time 8.3x improvement in inference throughput on resource-constrained UAVs. Extensive experiments demonstrate that VLA-AN significantly improves spatial grounding, scene reasoning, and long-horizon navigation, achieving a maximum single-task success rate of 98.1%, and providing an efficient, practical solution for realizing full-chain closed-loop autonomy in lightweight aerial robots.
Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Oct 24, 2025Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.
Understanding R1-Zero-Like Training: A Critical Perspective
Mar 26, 2025



DeepSeek-R1-Zero has shown that reinforcement learning (RL) at scale can directly enhance the reasoning capabilities of LLMs without supervised fine-tuning. In this work, we critically examine R1-Zero-like training by analyzing its two core components: base models and RL. We investigate a wide range of base models, including DeepSeek-V3-Base, to understand how pretraining characteristics influence RL performance. Our analysis reveals that DeepSeek-V3-Base already exhibit ''Aha moment'', while Qwen2.5 base models demonstrate strong reasoning capabilities even without prompt templates, suggesting potential pretraining biases. Additionally, we identify an optimization bias in Group Relative Policy Optimization (GRPO), which artificially increases response length (especially for incorrect outputs) during training. To address this, we introduce Dr. GRPO, an unbiased optimization method that improves token efficiency while maintaining reasoning performance. Leveraging these insights, we present a minimalist R1-Zero recipe that achieves 43.3% accuracy on AIME 2024 with a 7B base model, establishing a new state-of-the-art. Our code is available at https://github.com/sail-sg/understand-r1-zero.
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Mar 12, 2025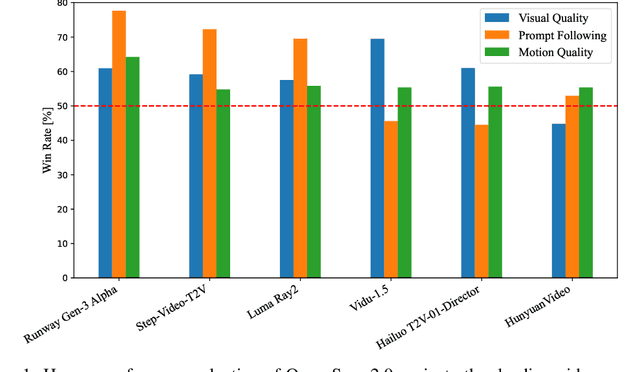

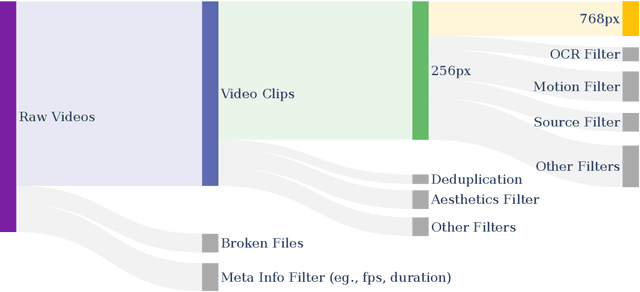

Video generation models have achieved remarkable progress in the past year. The quality of AI video continues to improve, but at the cost of larger model size, increased data quantity, and greater demand for training compute. In this report, we present Open-Sora 2.0, a commercial-level video generation model trained for only $200k. With this model, we demonstrate that the cost of training a top-performing video generation model is highly controllable. We detail all techniques that contribute to this efficiency breakthrough, including data curation, model architecture, training strategy, and system optimization. According to human evaluation results and VBench scores, Open-Sora 2.0 is comparable to global leading video generation models including the open-source HunyuanVideo and the closed-source Runway Gen-3 Alpha. By making Open-Sora 2.0 fully open-source, we aim to democratize access to advanced video generation technology, fostering broader innovation and creativity in content creation. All resources are publicly available at: https://github.com/hpcaitech/Open-Sora.
Adaptive Tool Use in Large Language Models with Meta-Cognition Trigger
Feb 18, 2025



Large language models (LLMs) have shown remarkable emergent capabilities, transforming the execution of functional tasks by leveraging external tools for complex problems that require specialized processing or real-time data. While existing research expands LLMs access to diverse tools (e.g., program interpreters, search engines, weather/map apps), the necessity of using these tools is often overlooked, leading to indiscriminate tool invocation. This naive approach raises two key issues:(1) increased delays due to unnecessary tool calls, and (2) potential errors resulting from faulty interactions with external tools. In this paper, we introduce meta-cognition as a proxy for LLMs self-assessment of their capabilities, representing the model's awareness of its own limitations. Based on this, we propose MeCo, an adaptive decision-making strategy for external tool use. MeCo quantifies metacognitive scores by capturing high-level cognitive signals in the representation space, guiding when to invoke tools. Notably, MeCo is fine-tuning-free and incurs minimal cost. Our experiments show that MeCo accurately detects LLMs' internal cognitive signals and significantly improves tool-use decision-making across multiple base models and benchmarks.