 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Independence Assumption in LEO Satellite-to-Ground Optical Links: A State-Coupled Joint Fading Model
May 11, 2026Performance analysis of low Earth orbit (LEO) satellite-to-ground optical links relies on composite fading models that typically evaluate scintillation and angular loss under the assumption of statistical independence. While ensuring analytical tractability, this assumption decouples fading mechanisms driven by the same atmospheric turbulence and fails to capture the distinct effects of free atmosphere (FA) and boundary layer (BL) perturbations. To model this coupling while preserving tractability, this paper develops a state-coupled joint fading model. In the proposed framework, aperture-averaged scintillation and effective angular loss are jointly characterized by a discrete slow atmospheric state, parameterized by separate FA and BL scaling factors. By replacing unconditional independence with state-conditioned independence, the model enables a closed-form derivation of the outage probability, preserving the computational simplicity of the independent baseline. Numerical results show that the independent baseline can misestimate outage under non-nominal layered turbulence states. This outage prediction bias varies with elevation because the relative roles of scintillation and angular loss change with the link geometry, resulting in different residual angular correction requirements for a given outage target.
Generalizable Knowledge Distillation from Vision Foundation Models for Semantic Segmentation
Mar 03, 2026Knowledge distillation (KD) has been widely applied in semantic segmentation to compress large models, but conventional approaches primarily preserve in-domain accuracy while neglecting out-of-domain generalization, which is essential under distribution shifts. This limitation becomes more severe with the emergence of vision foundation models (VFMs): although VFMs exhibit strong robustness on unseen data, distilling them with conventional KD often compromises this ability. We propose Generalizable Knowledge Distillation (GKD), a multi-stage framework that explicitly enhances generalization. GKD decouples representation learning from task learning. In the first stage, the student acquires domain-agnostic representations through selective feature distillation, and in the second stage, these representations are frozen for task adaptation, thereby mitigating overfitting to visible domains. To further support transfer, we introduce a query-based soft distillation mechanism, where student features act as queries to teacher representations to selectively retrieve transferable spatial knowledge from VFMs. Extensive experiments on five domain generalization benchmarks demonstrate that GKD consistently outperforms existing KD methods, achieving average gains of +1.9% in foundation-to-foundation (F2F) and +10.6% in foundation-to-local (F2L) distillation. The code will be available at https://github.com/Younger-hua/GKD.
MG-HGNN: A Heterogeneous GNN Framework for Indoor Wi-Fi Fingerprint-Based Localization
Nov 10, 2025Received signal strength indicator (RSSI) is the primary representation of Wi-Fi fingerprints and serves as a crucial tool for indoor localization. However, existing RSSI-based positioning methods often suffer from reduced accuracy due to environmental complexity and challenges in processing multi-source information. To address these issues, we propose a novel multi-graph heterogeneous GNN framework (MG-HGNN) to enhance spatial awareness and improve positioning performance. In this framework, two graph construction branches perform node and edge embedding, respectively, to generate informative graphs. Subsequently, a heterogeneous graph neural network is employed for graph representation learning, enabling accurate positioning. The MG-HGNN framework introduces the following key innovations: 1) multi-type task-directed graph construction that combines label estimation and feature encoding for richer graph information; 2) a heterogeneous GNN structure that enhances the performance of conventional GNN models. Evaluations on the UJIIndoorLoc and UTSIndoorLoc public datasets demonstrate that MG-HGNN not only achieves superior performance compared to several state-of-the-art methods, but also provides a novel perspective for enhancing GNN-based localization methods. Ablation studies further confirm the rationality and effectiveness of the proposed framework.
Orthogonal Projection Subspace to Aggregate Online Prior-knowledge for Continual Test-time Adaptation
Jun 23, 2025



Continual Test Time Adaptation (CTTA) is a task that requires a source pre-trained model to continually adapt to new scenarios with changing target distributions. Existing CTTA methods primarily focus on mitigating the challenges of catastrophic forgetting and error accumulation. Though there have been emerging methods based on forgetting adaptation with parameter-efficient fine-tuning, they still struggle to balance competitive performance and efficient model adaptation, particularly in complex tasks like semantic segmentation. In this paper, to tackle the above issues, we propose a novel pipeline, Orthogonal Projection Subspace to aggregate online Prior-knowledge, dubbed OoPk. Specifically, we first project a tuning subspace orthogonally which allows the model to adapt to new domains while preserving the knowledge integrity of the pre-trained source model to alleviate catastrophic forgetting. Then, we elaborate an online prior-knowledge aggregation strategy that employs an aggressive yet efficient image masking strategy to mimic potential target dynamism, enhancing the student model's domain adaptability. This further gradually ameliorates the teacher model's knowledge, ensuring high-quality pseudo labels and reducing error accumulation. We demonstrate our method with extensive experiments that surpass previous CTTA methods and achieve competitive performances across various continual TTA benchmarks in semantic segmentation tasks.
Adaptive event-triggered robust tracking control of soft robots
Jun 11, 2025



Soft robots manufactured with flexible materials can be highly compliant and adaptive to their surroundings, which facilitates their application in areas such as dexterous manipulation and environmental exploration. This paper aims at investigating the tracking control problem for soft robots under uncertainty such as unmodeled dynamics and external disturbance. First, we establish a novel switching function and design the compensated tracking error dynamics by virtue of the command filter. Then, based on the backstepping methodology, the virtual controllers and the adaptive logic estimating the supremum of uncertainty impacts are developed for synthesizing an event-triggered control strategy. In addition, the uniformed finite-time stability certification is derived for different scenarios of the switching function. Finally, we perform a case study of a soft robot to illustrate the effectiveness of the proposed control algorithm.
Lightweight Adapter Learning for More Generalized Remote Sensing Change Detection
Apr 28, 2025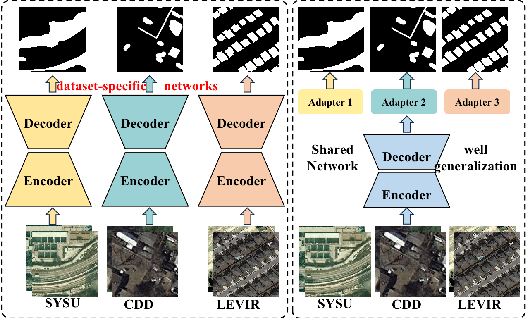

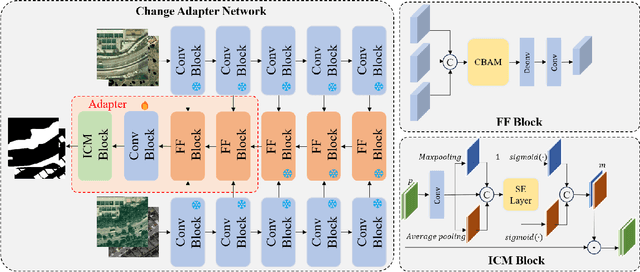
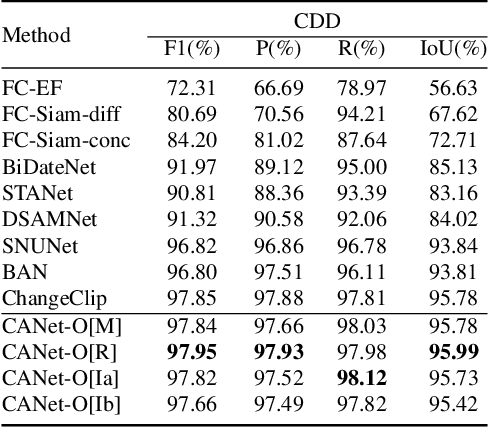
Deep learning methods have shown promising performances in remote sensing image change detection (CD). However, existing methods usually train a dataset-specific deep network for each dataset. Due to the significant differences in the data distribution and labeling between various datasets, the trained dataset-specific deep network has poor generalization performances on other datasets. To solve this problem, this paper proposes a change adapter network (CANet) for a more universal and generalized CD. CANet contains dataset-shared and dataset-specific learning modules. The former explores the discriminative features of images, and the latter designs a lightweight adapter model, to deal with the characteristics of different datasets in data distribution and labeling. The lightweight adapter can quickly generalize the deep network for new CD tasks with a small computation cost. Specifically, this paper proposes an interesting change region mask (ICM) in the adapter, which can adaptively focus on interested change objects and decrease the influence of labeling differences in various datasets. Moreover, CANet adopts a unique batch normalization layer for each dataset to deal with data distribution differences. Compared with existing deep learning methods, CANet can achieve satisfactory CD performances on various datasets simultaneously. Experimental results on several public datasets have verified the effectiveness and advantages of the proposed CANet on CD. CANet has a stronger generalization ability, smaller training costs (merely updating 4.1%-7.7% parameters), and better performances under limited training datasets than other deep learning methods, which also can be flexibly inserted with existing deep models.
Generalization-aware Remote Sensing Change Detection via Domain-agnostic Learning
Apr 01, 2025Change detection has essential significance for the region's development, in which pseudo-changes between bitemporal images induced by imaging environmental factors are key challenges. Existing transformation-based methods regard pseudo-changes as a kind of style shift and alleviate it by transforming bitemporal images into the same style using generative adversarial networks (GANs). However, their efforts are limited by two drawbacks: 1) Transformed images suffer from distortion that reduces feature discrimination. 2) Alignment hampers the model from learning domain-agnostic representations that degrades performance on scenes with domain shifts from the training data. Therefore, oriented from pseudo-changes caused by style differences, we present a generalizable domain-agnostic difference learning network (DonaNet). For the drawback 1), we argue for local-level statistics as style proxies to assist against domain shifts. For the drawback 2), DonaNet learns domain-agnostic representations by removing domain-specific style of encoded features and highlighting the class characteristics of objects. In the removal, we propose a domain difference removal module to reduce feature variance while preserving discriminative properties and propose its enhanced version to provide possibilities for eliminating more style by decorrelating the correlation between features. In the highlighting, we propose a cross-temporal generalization learning strategy to imitate latent domain shifts, thus enabling the model to extract feature representations more robust to shifts actively. Extensive experiments conducted on three public datasets demonstrate that DonaNet outperforms existing state-of-the-art methods with a smaller model size and is more robust to domain shift.
Towards Balanced Continual Multi-Modal Learning in Human Pose Estimation
Jan 09, 2025



3D human pose estimation (3D HPE) has emerged as a prominent research topic, particularly in the realm of RGB-based methods. However, RGB images are susceptible to limitations such as sensitivity to lighting conditions and potential user discomfort. Consequently, multi-modal sensing, which leverages non-intrusive sensors, is gaining increasing attention. Nevertheless, multi-modal 3D HPE still faces challenges, including modality imbalance and the imperative for continual learning. In this work, we introduce a novel balanced continual multi-modal learning method for 3D HPE, which harnesses the power of RGB, LiDAR, mmWave, and WiFi. Specifically, we propose a Shapley value-based contribution algorithm to quantify the contribution of each modality and identify modality imbalance. To address this imbalance, we employ a re-learning strategy. Furthermore, recognizing that raw data is prone to noise contamination, we develop a novel denoising continual learning approach. This approach incorporates a noise identification and separation module to mitigate the adverse effects of noise and collaborates with the balanced learning strategy to enhance optimization. Additionally, an adaptive EWC mechanism is employed to alleviate catastrophic forgetting. We conduct extensive experiments on the widely-adopted multi-modal dataset, MM-Fi, which demonstrate the superiority of our approach in boosting 3D pose estimation and mitigating catastrophic forgetting in complex scenarios. We will release our codes.
ChangeDiff: A Multi-Temporal Change Detection Data Generator with Flexible Text Prompts via Diffusion Model
Dec 20, 2024



Data-driven deep learning models have enabled tremendous progress in change detection (CD) with the support of pixel-level annotations. However, collecting diverse data and manually annotating them is costly, laborious, and knowledge-intensive. Existing generative methods for CD data synthesis show competitive potential in addressing this issue but still face the following limitations: 1) difficulty in flexibly controlling change events, 2) dependence on additional data to train the data generators, 3) focus on specific change detection tasks. To this end, this paper focuses on the semantic CD (SCD) task and develops a multi-temporal SCD data generator ChangeDiff by exploring powerful diffusion models. ChangeDiff innovatively generates change data in two steps: first, it uses text prompts and a text-to-layout (T2L) model to create continuous layouts, and then it employs layout-to-image (L2I) to convert these layouts into images. Specifically, we propose multi-class distribution-guided text prompts (MCDG-TP), allowing for layouts to be generated flexibly through controllable classes and their corresponding ratios. Subsequently, to generalize the T2L model to the proposed MCDG-TP, a class distribution refinement loss is further designed as training supervision. %For the former, a multi-classdistribution-guided text prompt (MCDG-TP) is proposed to complement via controllable classes and ratios. To generalize the text-to-image diffusion model to the proposed MCDG-TP, a class distribution refinement loss is designed as training supervision. For the latter, MCDG-TP in three modes is proposed to synthesize new layout masks from various texts. Our generated data shows significant progress in temporal continuity, spatial diversity, and quality realism, empowering change detectors with accuracy and transferability. The code is available at https://github.com/DZhaoXd/ChangeDiff
Stable Neighbor Denoising for Source-free Domain Adaptive Segmentation
Jun 10, 2024
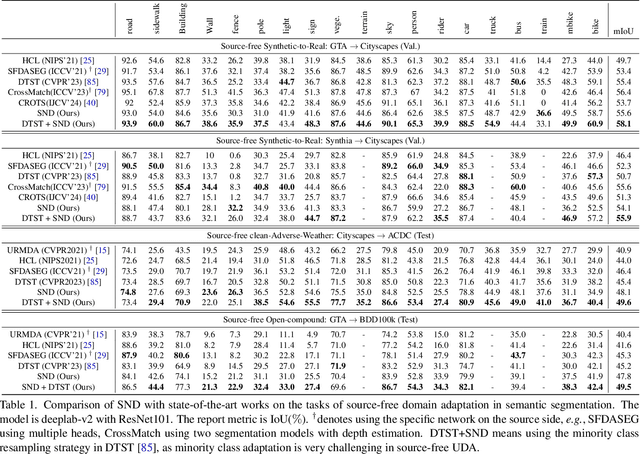
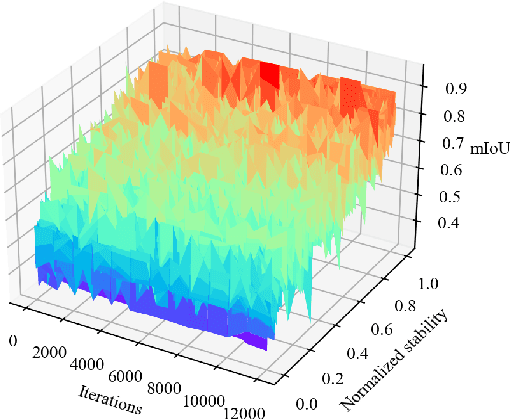
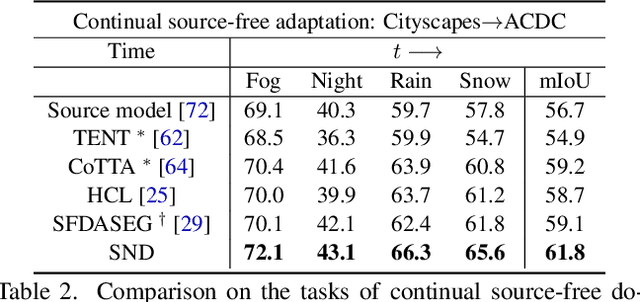
We study source-free unsupervised domain adaptation (SFUDA) for semantic segmentation, which aims to adapt a source-trained model to the target domain without accessing the source data. Many works have been proposed to address this challenging problem, among which uncertainty-based self-training is a predominant approach. However, without comprehensive denoising mechanisms, they still largely fall into biased estimates when dealing with different domains and confirmation bias. In this paper, we observe that pseudo-label noise is mainly contained in unstable samples in which the predictions of most pixels undergo significant variations during self-training. Inspired by this, we propose a novel mechanism to denoise unstable samples with stable ones. Specifically, we introduce the Stable Neighbor Denoising (SND) approach, which effectively discovers highly correlated stable and unstable samples by nearest neighbor retrieval and guides the reliable optimization of unstable samples by bi-level learning. Moreover, we compensate for the stable set by object-level object paste, which can further eliminate the bias caused by less learned classes. Our SND enjoys two advantages. First, SND does not require a specific segmentor structure, endowing its universality. Second, SND simultaneously addresses the issues of class, domain, and confirmation biases during adaptation, ensuring its effectiveness. Extensive experiments show that SND consistently outperforms state-of-the-art methods in various SFUDA semantic segmentation settings. In addition, SND can be easily integrated with other approaches, obtaining further improvements.
* 2024 Conference on Computer Vision and Pattern Recognition