 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Graph-based Framework with Disentangled Representations Learning for Multi-target Cross Domain Recommendation
Jul 01, 2024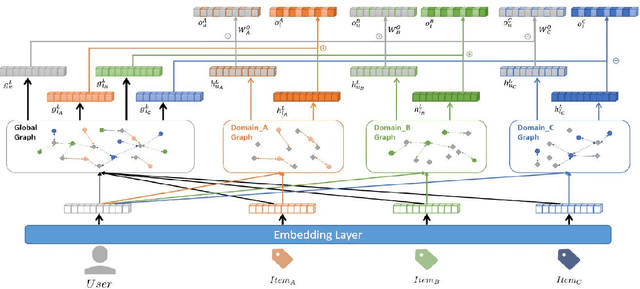



CDR (Cross-Domain Recommendation), i.e., leveraging information from multiple domains, is a critical solution to data sparsity problem in recommendation system. The majority of previous research either focused on single-target CDR (STCDR) by utilizing data from the source domains to improve the model's performance on the target domain, or applied dual-target CDR (DTCDR) by integrating data from the source and target domains. In addition, multi-target CDR (MTCDR) is a generalization of DTCDR, which is able to capture the link among different domains. In this paper we present HGDR (Heterogeneous Graph-based Framework with Disentangled Representations Learning), an end-to-end heterogeneous network architecture where graph convolutional layers are applied to model relations among different domains, meanwhile utilizes the idea of disentangling representation for domain-shared and domain-specifc information. First, a shared heterogeneous graph is generated by gathering users and items from several domains without any further side information. Second, we use HGDR to compute disentangled representations for users and items in all domains.Experiments on real-world datasets and online A/B tests prove that our proposed model can transmit information among domains effectively and reach the SOTA performance.
Controllable Talking Face Generation by Implicit Facial Keypoints Editing
Jun 05, 2024Audio-driven talking face generation has garnered significant interest within the domain of digital human research. Existing methods are encumbered by intricate model architectures that are intricately dependent on each other, complicating the process of re-editing image or video inputs. In this work, we present ControlTalk, a talking face generation method to control face expression deformation based on driven audio, which can construct the head pose and facial expression including lip motion for both single image or sequential video inputs in a unified manner. By utilizing a pre-trained video synthesis renderer and proposing the lightweight adaptation, ControlTalk achieves precise and naturalistic lip synchronization while enabling quantitative control over mouth opening shape. Our experiments show that our method is superior to state-of-the-art performance on widely used benchmarks, including HDTF and MEAD. The parameterized adaptation demonstrates remarkable generalization capabilities, effectively handling expression deformation across same-ID and cross-ID scenarios, and extending its utility to out-of-domain portraits, regardless of languages.
Cross-Scale Context Extracted Hashing for Fine-Grained Image Binary Encoding
Oct 14, 2022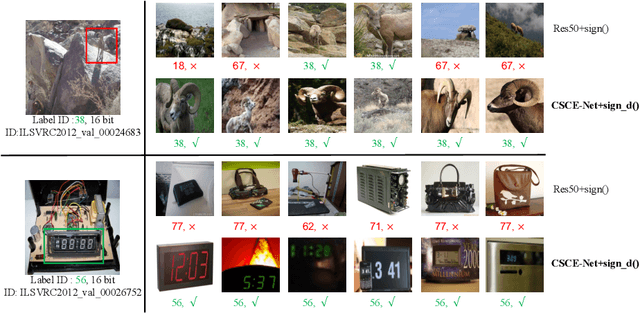
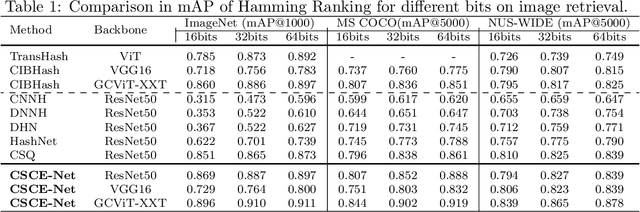
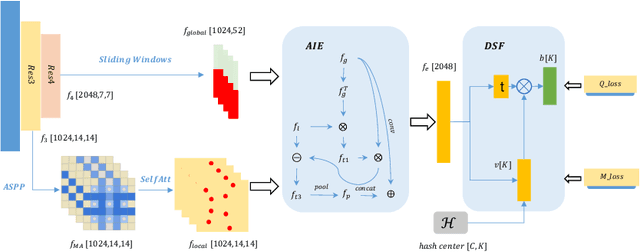
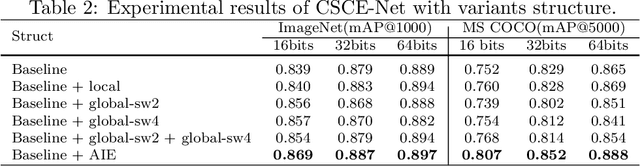
Deep hashing has been widely applied to large-scale image retrieval tasks owing to efficient computation and low storage cost by encoding high-dimensional image data into binary codes. Since binary codes do not contain as much information as float features, the essence of binary encoding is preserving the main context to guarantee retrieval quality. However, the existing hashing methods have great limitations on suppressing redundant background information and accurately encoding from Euclidean space to Hamming space by a simple sign function. In order to solve these problems, a Cross-Scale Context Extracted Hashing Network (CSCE-Net) is proposed in this paper. Firstly, we design a two-branch framework to capture fine-grained local information while maintaining high-level global semantic information. Besides, Attention guided Information Extraction module (AIE) is introduced between two branches, which suppresses areas of low context information cooperated with global sliding windows. Unlike previous methods, our CSCE-Net learns a content-related Dynamic Sign Function (DSF) to replace the original simple sign function. Therefore, the proposed CSCE-Net is context-sensitive and able to perform well on accurate image binary encoding. We further demonstrate that our CSCE-Net is superior to the existing hashing methods, which improves retrieval performance on standard benchmarks.
Hierarchy-Aware T5 with Path-Adaptive Mask Mechanism for Hierarchical Text Classification
Sep 17, 2021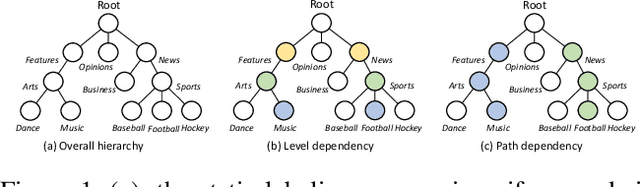
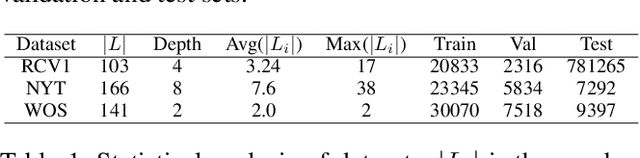
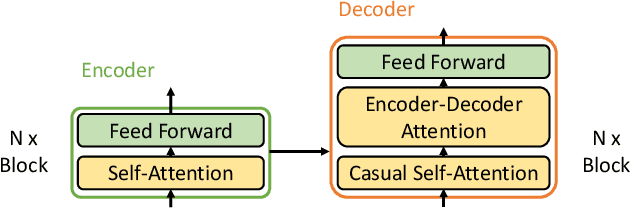

Hierarchical Text Classification (HTC), which aims to predict text labels organized in hierarchical space, is a significant task lacking in investigation in natural language processing. Existing methods usually encode the entire hierarchical structure and fail to construct a robust label-dependent model, making it hard to make accurate predictions on sparse lower-level labels and achieving low Macro-F1. In this paper, we propose a novel PAMM-HiA-T5 model for HTC: a hierarchy-aware T5 model with path-adaptive mask mechanism that not only builds the knowledge of upper-level labels into low-level ones but also introduces path dependency information in label prediction. Specifically, we generate a multi-level sequential label structure to exploit hierarchical dependency across different levels with Breadth-First Search (BFS) and T5 model. To further improve label dependency prediction within each path, we then propose an original path-adaptive mask mechanism (PAMM) to identify the label's path information, eliminating sources of noises from other paths. Comprehensive experiments on three benchmark datasets show that our novel PAMM-HiA-T5 model greatly outperforms all state-of-the-art HTC approaches especially in Macro-F1. The ablation studies show that the improvements mainly come from our innovative approach instead of T5.