 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehave Your Motion: Habit-preserved Cross-category Animal Motion Transfer
Jul 10, 2025Animal motion embodies species-specific behavioral habits, making the transfer of motion across categories a critical yet complex task for applications in animation and virtual reality. Existing motion transfer methods, primarily focused on human motion, emphasize skeletal alignment (motion retargeting) or stylistic consistency (motion style transfer), often neglecting the preservation of distinct habitual behaviors in animals. To bridge this gap, we propose a novel habit-preserved motion transfer framework for cross-category animal motion. Built upon a generative framework, our model introduces a habit-preservation module with category-specific habit encoder, allowing it to learn motion priors that capture distinctive habitual characteristics. Furthermore, we integrate a large language model (LLM) to facilitate the motion transfer to previously unobserved species. To evaluate the effectiveness of our approach, we introduce the DeformingThings4D-skl dataset, a quadruped dataset with skeletal bindings, and conduct extensive experiments and quantitative analyses, which validate the superiority of our proposed model.
Heterogeneous Graph-based Framework with Disentangled Representations Learning for Multi-target Cross Domain Recommendation
Jul 01, 2024CDR (Cross-Domain Recommendation), i.e., leveraging information from multiple domains, is a critical solution to data sparsity problem in recommendation system. The majority of previous research either focused on single-target CDR (STCDR) by utilizing data from the source domains to improve the model's performance on the target domain, or applied dual-target CDR (DTCDR) by integrating data from the source and target domains. In addition, multi-target CDR (MTCDR) is a generalization of DTCDR, which is able to capture the link among different domains. In this paper we present HGDR (Heterogeneous Graph-based Framework with Disentangled Representations Learning), an end-to-end heterogeneous network architecture where graph convolutional layers are applied to model relations among different domains, meanwhile utilizes the idea of disentangling representation for domain-shared and domain-specifc information. First, a shared heterogeneous graph is generated by gathering users and items from several domains without any further side information. Second, we use HGDR to compute disentangled representations for users and items in all domains.Experiments on real-world datasets and online A/B tests prove that our proposed model can transmit information among domains effectively and reach the SOTA performance.
RangeLDM: Fast Realistic LiDAR Point Cloud Generation
Mar 15, 2024Autonomous driving demands high-quality LiDAR data, yet the cost of physical LiDAR sensors presents a significant scaling-up challenge. While recent efforts have explored deep generative models to address this issue, they often consume substantial computational resources with slow generation speeds while suffering from a lack of realism. To address these limitations, we introduce RangeLDM, a novel approach for rapidly generating high-quality range-view LiDAR point clouds via latent diffusion models. We achieve this by correcting range-view data distribution for accurate projection from point clouds to range images via Hough voting, which has a critical impact on generative learning. We then compress the range images into a latent space with a variational autoencoder, and leverage a diffusion model to enhance expressivity. Additionally, we instruct the model to preserve 3D structural fidelity by devising a range-guided discriminator. Experimental results on KITTI-360 and nuScenes datasets demonstrate both the robust expressiveness and fast speed of our LiDAR point cloud generation.
InvariantOODG: Learning Invariant Features of Point Clouds for Out-of-Distribution Generalization
Jan 08, 2024


The convenience of 3D sensors has led to an increase in the use of 3D point clouds in various applications. However, the differences in acquisition devices or scenarios lead to divergence in the data distribution of point clouds, which requires good generalization of point cloud representation learning methods. While most previous methods rely on domain adaptation, which involves fine-tuning pre-trained models on target domain data, this may not always be feasible in real-world scenarios where target domain data may be unavailable. To address this issue, we propose InvariantOODG, which learns invariability between point clouds with different distributions using a two-branch network to extract local-to-global features from original and augmented point clouds. Specifically, to enhance local feature learning of point clouds, we define a set of learnable anchor points that locate the most useful local regions and two types of transformations to augment the input point clouds. The experimental results demonstrate the effectiveness of the proposed model on 3D domain generalization benchmarks.
A unified consensus-based parallel ADMM algorithm for high-dimensional regression with combined regularizations
Nov 21, 2023The parallel alternating direction method of multipliers (ADMM) algorithm is widely recognized for its effectiveness in handling large-scale datasets stored in a distributed manner, making it a popular choice for solving statistical learning models. However, there is currently limited research on parallel algorithms specifically designed for high-dimensional regression with combined (composite) regularization terms. These terms, such as elastic-net, sparse group lasso, sparse fused lasso, and their nonconvex variants, have gained significant attention in various fields due to their ability to incorporate prior information and promote sparsity within specific groups or fused variables. The scarcity of parallel algorithms for combined regularizations can be attributed to the inherent nonsmoothness and complexity of these terms, as well as the absence of closed-form solutions for certain proximal operators associated with them. In this paper, we propose a unified constrained optimization formulation based on the consensus problem for these types of convex and nonconvex regression problems and derive the corresponding parallel ADMM algorithms. Furthermore, we prove that the proposed algorithm not only has global convergence but also exhibits linear convergence rate. Extensive simulation experiments, along with a financial example, serve to demonstrate the reliability, stability, and scalability of our algorithm. The R package for implementing the proposed algorithms can be obtained at https://github.com/xfwu1016/CPADMM.
Unsupervised Manga Character Re-identification via Face-body and Spatial-temporal Associated Clustering
Apr 10, 2022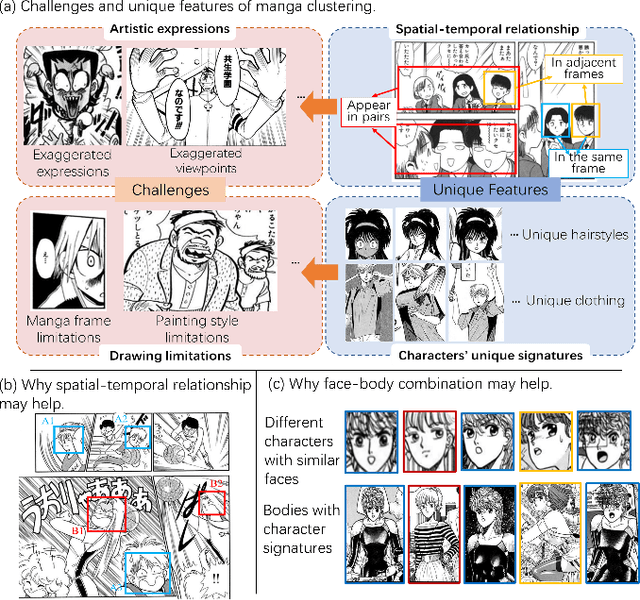



In the past few years, there has been a dramatic growth in e-manga (electronic Japanese-style comics). Faced with the booming demand for manga research and the large amount of unlabeled manga data, we raised a new task, called unsupervised manga character re-identification. However, the artistic expression and stylistic limitations of manga pose many challenges to the re-identification problem. Inspired by the idea that some content-related features may help clustering, we propose a Face-body and Spatial-temporal Associated Clustering method (FSAC). In the face-body combination module, a face-body graph is constructed to solve problems such as exaggeration and deformation in artistic creation by using the integrity of the image. In the spatial-temporal relationship correction module, we analyze the appearance features of characters and design a temporal-spatial-related triplet loss to fine-tune the clustering. Extensive experiments on a manga book dataset with 109 volumes validate the superiority of our method in unsupervised manga character re-identification.
Improving Stack Overflow question title generation with copying enhanced CodeBERT model and bi-modal information
Sep 27, 2021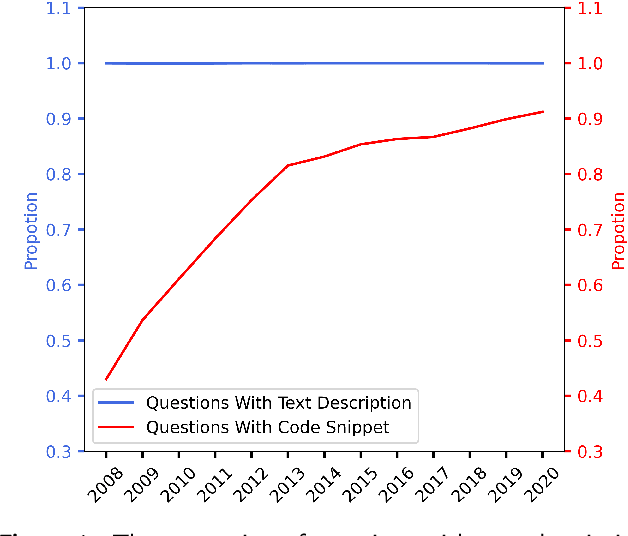
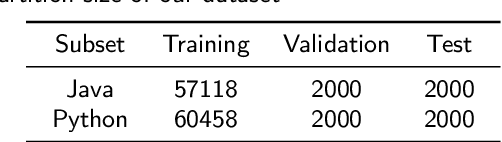
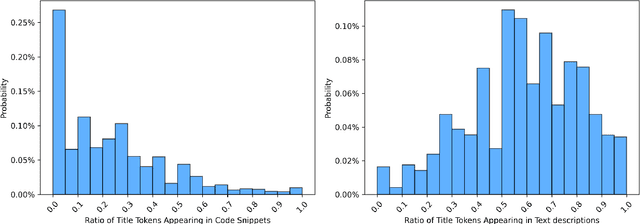
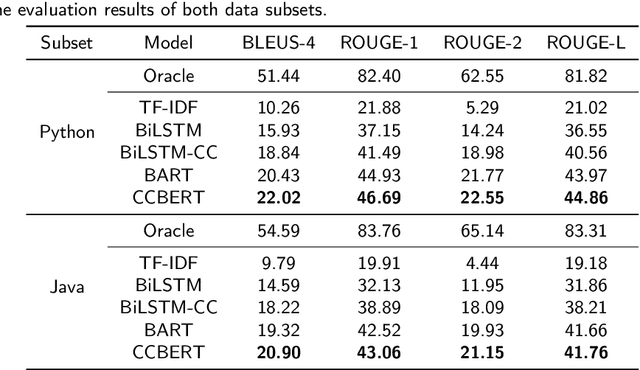
Context: Stack Overflow is very helpful for software developers who are seeking answers to programming problems. Previous studies have shown that a growing number of questions are of low-quality and thus obtain less attention from potential answerers. Gao et al. proposed a LSTM-based model (i.e., BiLSTM-CC) to automatically generate question titles from the code snippets to improve the question quality. However, only using the code snippets in question body cannot provide sufficient information for title generation, and LSTMs cannot capture the long-range dependencies between tokens. Objective: We propose CCBERT, a deep learning based novel model to enhance the performance of question title generation by making full use of the bi-modal information of the entire question body. Methods: CCBERT follows the encoder-decoder paradigm, and uses CodeBERT to encode the question body into hidden representations, a stacked Transformer decoder to generate predicted tokens, and an additional copy attention layer to refine the output distribution. Both the encoder and decoder perform the multi-head self-attention operation to better capture the long-range dependencies. We build a dataset containing more than 120,000 high-quality questions filtered from the data officially published by Stack Overflow to verify the effectiveness of the CCBERT model. Results: CCBERT achieves a better performance on the dataset, and especially outperforms BiLSTM-CC and a multi-purpose pre-trained model (BART) by 14% and 4% on average, respectively. Experiments on both code-only and low-resource datasets also show the superiority of CCBERT with less performance degradation, which are 40% and 13.5% for BiLSTM-CC, while 24% and 5% for CCBERT, respectively.
Hierarchy-Aware T5 with Path-Adaptive Mask Mechanism for Hierarchical Text Classification
Sep 17, 2021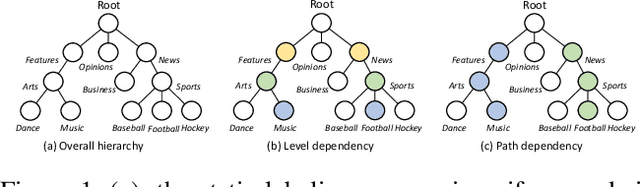

Hierarchical Text Classification (HTC), which aims to predict text labels organized in hierarchical space, is a significant task lacking in investigation in natural language processing. Existing methods usually encode the entire hierarchical structure and fail to construct a robust label-dependent model, making it hard to make accurate predictions on sparse lower-level labels and achieving low Macro-F1. In this paper, we propose a novel PAMM-HiA-T5 model for HTC: a hierarchy-aware T5 model with path-adaptive mask mechanism that not only builds the knowledge of upper-level labels into low-level ones but also introduces path dependency information in label prediction. Specifically, we generate a multi-level sequential label structure to exploit hierarchical dependency across different levels with Breadth-First Search (BFS) and T5 model. To further improve label dependency prediction within each path, we then propose an original path-adaptive mask mechanism (PAMM) to identify the label's path information, eliminating sources of noises from other paths. Comprehensive experiments on three benchmark datasets show that our novel PAMM-HiA-T5 model greatly outperforms all state-of-the-art HTC approaches especially in Macro-F1. The ablation studies show that the improvements mainly come from our innovative approach instead of T5.
Unsupervised monocular stereo matching
Dec 31, 2018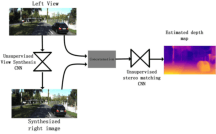
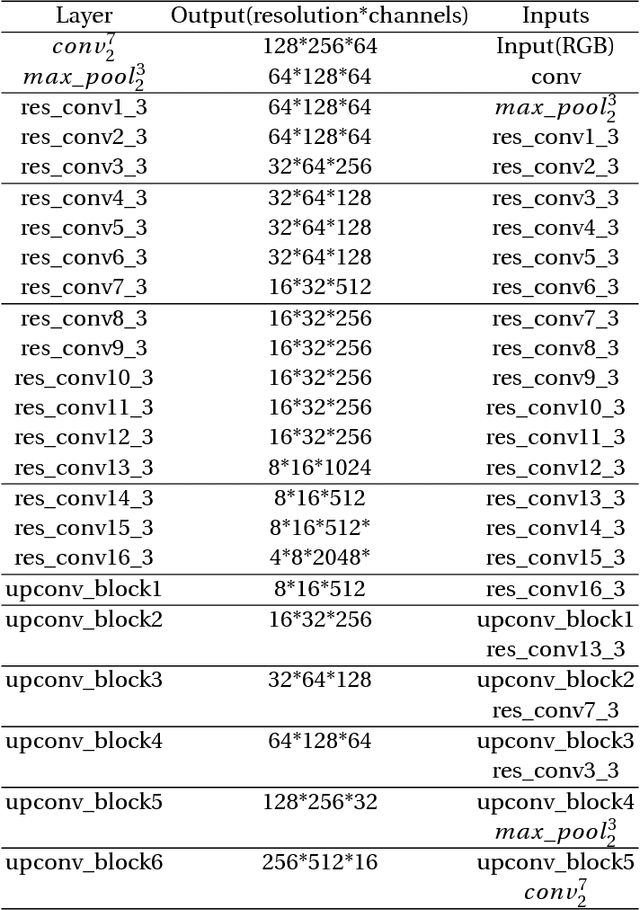

At present, deep learning has been applied more and more in monocular image depth estimation and has shown promising results. The current more ideal method for monocular depth estimation is the supervised learning based on ground truth depth, but this method requires an abundance of expensive ground truth depth as the supervised labels. Therefore, researchers began to work on unsupervised depth estimation methods. Although the accuracy of unsupervised depth estimation method is still lower than that of supervised method, it is a promising research direction. In this paper, Based on the experimental results that the stereo matching models outperforms monocular depth estimation models under the same unsupervised depth estimation model, we proposed an unsupervised monocular vision stereo matching method. In order to achieve the monocular stereo matching, we constructed two unsupervised deep convolution network models, one was to reconstruct the right view from the left view, and the other was to estimate the depth map using the reconstructed right view and the original left view. The two network models are piped together during the test phase. The output results of this method outperforms the current mainstream unsupervised depth estimation method in the challenging KITTI dataset.