 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInnovator: Triggering the Innovative Capabilities of LLMs
Feb 21, 2026The application of Large Language Models (LLMs) in accelerating scientific discovery has garnered increasing attention, with a key focus on constructing research agents endowed with innovative capability, i.e., the ability to autonomously generate novel and significant research ideas. Existing approaches predominantly rely on sophisticated prompt engineering and lack a systematic training paradigm. To address this, we propose DeepInnovator, a training framework designed to trigger the innovative capability of LLMs. Our approach comprises two core components. (1) ``Standing on the shoulders of giants''. We construct an automated data extraction pipeline to extract and organize structured research knowledge from a vast corpus of unlabeled scientific literature. (2) ``Conjectures and refutations''. We introduce a ``Next Idea Prediction'' training paradigm, which models the generation of research ideas as an iterative process of continuously predicting, evaluating, and refining plausible and novel next idea. Both automatic and expert evaluations demonstrate that our DeepInnovator-14B significantly outperforms untrained baselines, achieving win rates of 80.53\%-93.81\%, and attains performance comparable to that of current leading LLMs. This work provides a scalable training pathway toward building research agents with genuine, originative innovative capability, and will open-source the dataset to foster community advancement. Source code and data are available at: https://github.com/HKUDS/DeepInnovator.
LaViT: Aligning Latent Visual Thoughts for Multi-modal Reasoning
Jan 15, 2026Current multimodal latent reasoning often relies on external supervision (e.g., auxiliary images), ignoring intrinsic visual attention dynamics. In this work, we identify a critical Perception Gap in distillation: student models frequently mimic a teacher's textual output while attending to fundamentally divergent visual regions, effectively relying on language priors rather than grounded perception. To bridge this, we propose LaViT, a framework that aligns latent visual thoughts rather than static embeddings. LaViT compels the student to autoregressively reconstruct the teacher's visual semantics and attention trajectories prior to text generation, employing a curriculum sensory gating mechanism to prevent shortcut learning. Extensive experiments show that LaViT significantly enhances visual grounding, achieving up to +16.9% gains on complex reasoning tasks and enabling a compact 3B model to outperform larger open-source variants and proprietary models like GPT-4o.
A$^2$Search: Ambiguity-Aware Question Answering with Reinforcement Learning
Oct 09, 2025



Recent advances in Large Language Models (LLMs) and Reinforcement Learning (RL) have led to strong performance in open-domain question answering (QA). However, existing models still struggle with questions that admit multiple valid answers. Standard QA benchmarks, which typically assume a single gold answer, overlook this reality and thus produce inappropriate training signals. Existing attempts to handle ambiguity often rely on costly manual annotation, which is difficult to scale to multi-hop datasets such as HotpotQA and MuSiQue. In this paper, we present A$^2$Search, an annotation-free, end-to-end training framework to recognize and handle ambiguity. At its core is an automated pipeline that detects ambiguous questions and gathers alternative answers via trajectory sampling and evidence verification. The model is then optimized with RL using a carefully designed $\mathrm{AnsF1}$ reward, which naturally accommodates multiple answers. Experiments on eight open-domain QA benchmarks demonstrate that A$^2$Search achieves new state-of-the-art performance. With only a single rollout, A$^2$Search-7B yields an average $\mathrm{AnsF1}@1$ score of $48.4\%$ across four multi-hop benchmarks, outperforming all strong baselines, including the substantially larger ReSearch-32B ($46.2\%$). Extensive analyses further show that A$^2$Search resolves ambiguity and generalizes across benchmarks, highlighting that embracing ambiguity is essential for building more reliable QA systems. Our code, data, and model weights can be found at https://github.com/zfj1998/A2Search
Understanding DeepResearch via Reports
Oct 09, 2025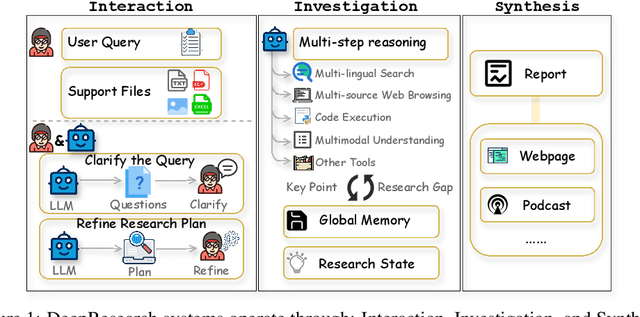

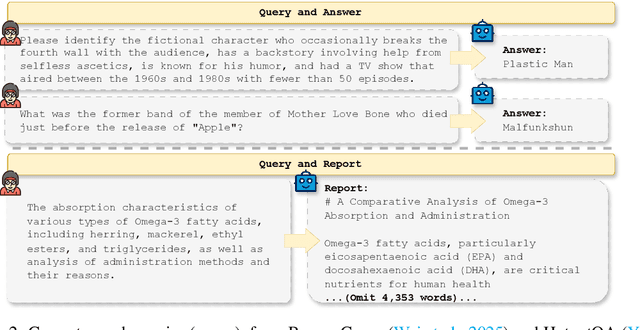

DeepResearch agents represent a transformative AI paradigm, conducting expert-level research through sophisticated reasoning and multi-tool integration. However, evaluating these systems remains critically challenging due to open-ended research scenarios and existing benchmarks that focus on isolated capabilities rather than holistic performance. Unlike traditional LLM tasks, DeepResearch systems must synthesize diverse sources, generate insights, and present coherent findings, which are capabilities that resist simple verification. To address this gap, we introduce DeepResearch-ReportEval, a comprehensive framework designed to assess DeepResearch systems through their most representative outputs: research reports. Our approach systematically measures three dimensions: quality, redundancy, and factuality, using an innovative LLM-as-a-Judge methodology achieving strong expert concordance. We contribute a standardized benchmark of 100 curated queries spanning 12 real-world categories, enabling systematic capability comparison. Our evaluation of four leading commercial systems reveals distinct design philosophies and performance trade-offs, establishing foundational insights as DeepResearch evolves from information assistants toward intelligent research partners. Source code and data are available at: https://github.com/HKUDS/DeepResearch-Eval.
Towards an Understanding of Context Utilization in Code Intelligence
Apr 11, 2025Code intelligence is an emerging domain in software engineering, aiming to improve the effectiveness and efficiency of various code-related tasks. Recent research suggests that incorporating contextual information beyond the basic original task inputs (i.e., source code) can substantially enhance model performance. Such contextual signals may be obtained directly or indirectly from sources such as API documentation or intermediate representations like abstract syntax trees can significantly improve the effectiveness of code intelligence. Despite growing academic interest, there is a lack of systematic analysis of context in code intelligence. To address this gap, we conduct an extensive literature review of 146 relevant studies published between September 2007 and August 2024. Our investigation yields four main contributions. (1) A quantitative analysis of the research landscape, including publication trends, venues, and the explored domains; (2) A novel taxonomy of context types used in code intelligence; (3) A task-oriented analysis investigating context integration strategies across diverse code intelligence tasks; (4) A critical evaluation of evaluation methodologies for context-aware methods. Based on these findings, we identify fundamental challenges in context utilization in current code intelligence systems and propose a research roadmap that outlines key opportunities for future research.
HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks
Oct 16, 2024
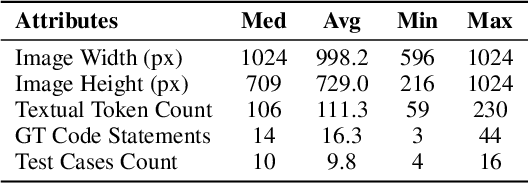

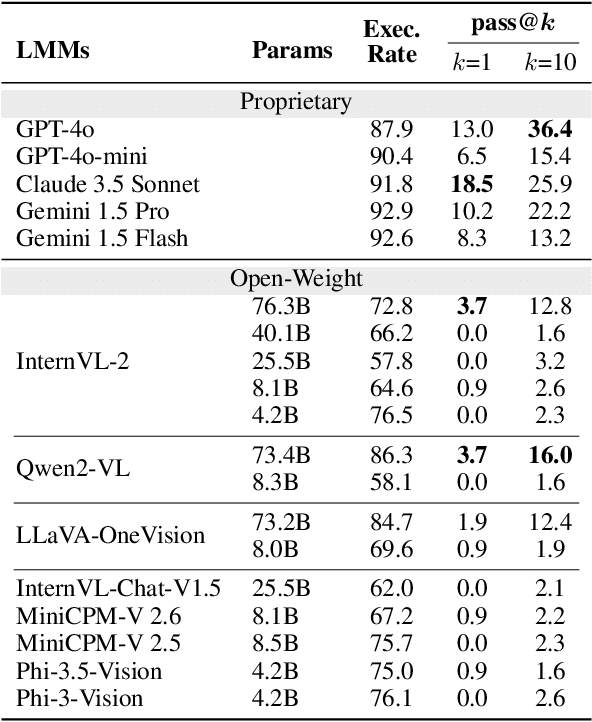
Coding tasks have been valuable for evaluating Large Language Models (LLMs), as they demand the comprehension of high-level instructions, complex reasoning, and the implementation of functional programs -- core capabilities for advancing Artificial General Intelligence. Despite the progress in Large Multimodal Models (LMMs), which extend LLMs with visual perception and understanding capabilities, there remains a notable lack of coding benchmarks that rigorously assess these models, particularly in tasks that emphasize visual reasoning. To address this gap, we introduce HumanEval-V, a novel and lightweight benchmark specifically designed to evaluate LMMs' visual understanding and reasoning capabilities through code generation. HumanEval-V includes 108 carefully crafted, entry-level Python coding tasks derived from platforms like CodeForces and Stack Overflow. Each task is adapted by modifying the context and algorithmic patterns of the original problems, with visual elements redrawn to ensure distinction from the source, preventing potential data leakage. LMMs are required to complete the code solution based on the provided visual context and a predefined Python function signature outlining the task requirements. Every task is equipped with meticulously handcrafted test cases to ensure a thorough and reliable evaluation of model-generated solutions. We evaluate 19 state-of-the-art LMMs using HumanEval-V, uncovering significant challenges. Proprietary models like GPT-4o achieve only 13% pass@1 and 36.4% pass@10, while open-weight models with 70B parameters score below 4% pass@1. Ablation studies further reveal the limitations of current LMMs in vision reasoning and coding capabilities. These results underscore key areas for future research to enhance LMMs' capabilities. We have open-sourced our code and benchmark at https://github.com/HumanEval-V/HumanEval-V-Benchmark.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.
SoTaNa: The Open-Source Software Development Assistant
Aug 25, 2023



Software development plays a crucial role in driving innovation and efficiency across modern societies. To meet the demands of this dynamic field, there is a growing need for an effective software development assistant. However, existing large language models represented by ChatGPT suffer from limited accessibility, including training data and model weights. Although other large open-source models like LLaMA have shown promise, they still struggle with understanding human intent. In this paper, we present SoTaNa, an open-source software development assistant. SoTaNa utilizes ChatGPT to generate high-quality instruction-based data for the domain of software engineering and employs a parameter-efficient fine-tuning approach to enhance the open-source foundation model, LLaMA. We evaluate the effectiveness of \our{} in answering Stack Overflow questions and demonstrate its capabilities. Additionally, we discuss its capabilities in code summarization and generation, as well as the impact of varying the volume of generated data on model performance. Notably, SoTaNa can run on a single GPU, making it accessible to a broader range of researchers. Our code, model weights, and data are public at \url{https://github.com/DeepSoftwareAnalytics/SoTaNa}.
Uncovering and Quantifying Social Biases in Code Generation
May 24, 2023



With the popularity of automatic code generation tools, such as Copilot, the study of the potential hazards of these tools is gaining importance. In this work, we explore the social bias problem in pre-trained code generation models. We propose a new paradigm to construct code prompts and successfully uncover social biases in code generation models. To quantify the severity of social biases in generated code, we develop a dataset along with three metrics to evaluate the overall social bias and fine-grained unfairness across different demographics. Experimental results on three pre-trained code generation models (Codex, InCoder, and CodeGen) with varying sizes, reveal severe social biases. Moreover, we conduct analysis to provide useful insights for further choice of code generation models with low social bias. (This work contains examples that potentially implicate stereotypes, associations, and other harms that could be offensive to individuals in certain social groups.)
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
Apr 03, 2023The task of repository-level code completion is to continue writing the unfinished code based on a broader context of the repository. While for automated code completion tools, it is difficult to utilize the useful information scattered in different files. We propose RepoCoder, a simple, generic, and effective framework to address the challenge. It streamlines the repository-level code completion process by incorporating a similarity-based retriever and a pre-trained code language model, which allows for the effective utilization of repository-level information for code completion and grants the ability to generate code at various levels of granularity. Furthermore, RepoCoder utilizes a novel iterative retrieval-generation paradigm that bridges the gap between retrieval context and the intended completion target. We also propose a new benchmark RepoEval, which consists of the latest and high-quality real-world repositories covering line, API invocation, and function body completion scenarios. We test the performance of RepoCoder by using various combinations of code retrievers and generators. Experimental results indicate that RepoCoder significantly improves the zero-shot code completion baseline by over 10% in all settings and consistently outperforms the vanilla retrieval-augmented code completion approach. Furthermore, we validate the effectiveness of RepoCoder through comprehensive analysis, providing valuable insights for future research.