 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJD-BP: A Joint-Decision Generative Framework for Auto-Bidding and Pricing
Apr 07, 2026Auto-bidding services optimize real-time bidding strategies for advertisers under key performance indicator (KPI) constraints such as target return on investment and budget. However, uncertainties such as model prediction errors and feedback latency can cause bidding strategies to deviate from ex-post optimality, leading to inefficient allocation. To address this issue, we propose JD-BP, a Joint generative Decision framework for Bidding and Pricing. Unlike prior methods, JD-BP jointly outputs a bid value and a pricing correction term that acts additively with the payment rule such as GSP. To mitigate adverse effects of historical constraint violations, we design a memory-less Return-to-Go that encourages future value maximizing of bidding actions while the cumulated bias is handled by the pricing correction. Moreover, a trajectory augmentation algorithm is proposed to generate joint bidding-pricing trajectories from a (possibly arbitrary) base bidding policy, enabling efficient plug-and-play deployment of our algorithm from existing RL/generative bidding models. Finally, we employ an Energy-Based Direct Preference Optimization method in conjunction with a cross-attention module to enhance the joint learning performance of bidding and pricing correction. Offline experiments on the AuctionNet dataset demonstrate that JD-BP achieves state-of-the-art performance. Online A/B tests at JD.com confirm its practical effectiveness, showing a 4.70% increase in ad revenue and a 6.48% improvement in target cost.
Boosting AI Reliability with an FSM-Driven Streaming Inference Pipeline: An Industrial Case
Mar 02, 2026The widespread adoption of AI in industry is often hampered by its limited robustness when faced with scenarios absent from training data, leading to prediction bias and vulnerabilities. To address this, we propose a novel streaming inference pipeline that enhances data-driven models by explicitly incorporating prior knowledge. This paper presents the work on an industrial AI application that automatically counts excavator workloads from surveillance videos. Our approach integrates an object detection model with a Finite State Machine (FSM), which encodes knowledge of operational scenarios to guide and correct the AI's predictions on streaming data. In experiments on a real-world dataset of over 7,000 images from 12 site videos, encompassing more than 300 excavator workloads, our method demonstrates superior performance and greater robustness compared to the original solution based on manual heuristic rules. We will release the code at https://github.com/thulab/video-streamling-inference-pipeline.
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
Apr 03, 2023The task of repository-level code completion is to continue writing the unfinished code based on a broader context of the repository. While for automated code completion tools, it is difficult to utilize the useful information scattered in different files. We propose RepoCoder, a simple, generic, and effective framework to address the challenge. It streamlines the repository-level code completion process by incorporating a similarity-based retriever and a pre-trained code language model, which allows for the effective utilization of repository-level information for code completion and grants the ability to generate code at various levels of granularity. Furthermore, RepoCoder utilizes a novel iterative retrieval-generation paradigm that bridges the gap between retrieval context and the intended completion target. We also propose a new benchmark RepoEval, which consists of the latest and high-quality real-world repositories covering line, API invocation, and function body completion scenarios. We test the performance of RepoCoder by using various combinations of code retrievers and generators. Experimental results indicate that RepoCoder significantly improves the zero-shot code completion baseline by over 10% in all settings and consistently outperforms the vanilla retrieval-augmented code completion approach. Furthermore, we validate the effectiveness of RepoCoder through comprehensive analysis, providing valuable insights for future research.
Exploring Distributional Shifts in Large Language Models for Code Analysis
Mar 16, 2023We systematically study the capacity of two large language models for code - CodeT5 and Codex - to generalize to out-of-domain data. In this study, we consider two fundamental applications - code summarization, and code generation. We split data into domains following its natural boundaries - by an organization, by a project, and by a module within the software project. This makes recognition of in-domain vs out-of-domain data at the time of deployment trivial. We establish that samples from each new domain present both models with a significant challenge of distribution shift. We study how well different established methods can adapt models to better generalize to new domains. Our experiments show that while multitask learning alone is a reasonable baseline, combining it with few-shot finetuning on examples retrieved from training data can achieve very strong performance. In fact, according to our experiments, this solution can outperform direct finetuning for very low-data scenarios. Finally, we consider variations of this approach to create a more broadly applicable method to adapt to multiple domains at once. We find that in the case of code generation, a model adapted to multiple domains simultaneously performs on par with those adapted to each domain individually.
Generation-Augmented Query Expansion For Code Retrieval
Dec 20, 2022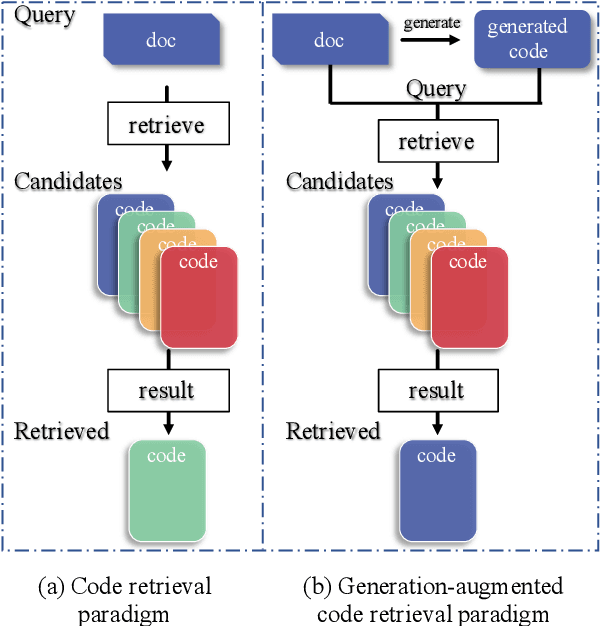
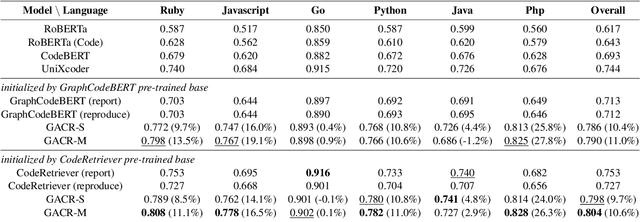

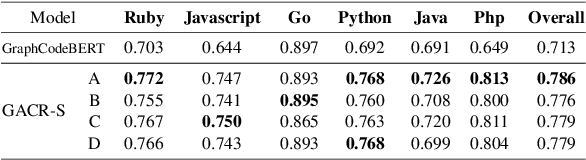
Pre-trained language models have achieved promising success in code retrieval tasks, where a natural language documentation query is given to find the most relevant existing code snippet. However, existing models focus only on optimizing the documentation code pairs by embedding them into latent space, without the association of external knowledge. In this paper, we propose a generation-augmented query expansion framework. Inspired by the human retrieval process - sketching an answer before searching, in this work, we utilize the powerful code generation model to benefit the code retrieval task. Specifically, we demonstrate that rather than merely retrieving the target code snippet according to the documentation query, it would be helpful to augment the documentation query with its generation counterpart - generated code snippets from the code generation model. To the best of our knowledge, this is the first attempt that leverages the code generation model to enhance the code retrieval task. We achieve new state-of-the-art results on the CodeSearchNet benchmark and surpass the baselines significantly.
HyperTuning: Toward Adapting Large Language Models without Back-propagation
Nov 22, 2022Fine-tuning large language models for different tasks can be costly and inefficient, and even methods that reduce the number of tuned parameters still require full gradient-based optimization. We propose HyperTuning, a novel approach to model adaptation that uses a hypermodel to generate task-specific parameters for a fixed downstream model. We demonstrate a simple setup for hypertuning with HyperT5, a T5-based hypermodel that produces soft prefixes or LoRA parameters for a frozen T5 model from few-shot examples. We train HyperT5 in two stages: first, hyperpretraining with a modified conditional language modeling objective that trains a hypermodel to generate parameters; second, multi-task fine-tuning (MTF) on a large number of diverse language tasks. We evaluate HyperT5 on P3, MetaICL and Super-NaturalInstructions datasets, and show that it can effectively generate parameters for unseen tasks. Moreover, we show that using hypermodel-generated parameters as initializations for further parameter-efficient fine-tuning improves performance. HyperTuning can thus be a flexible and efficient way to leverage large language models for diverse downstream applications.
AMD-DBSCAN: An Adaptive Multi-density DBSCAN for datasets of extremely variable density
Oct 15, 2022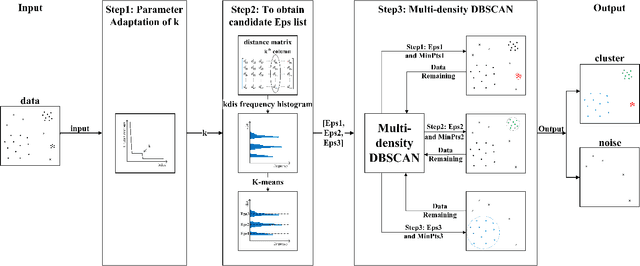
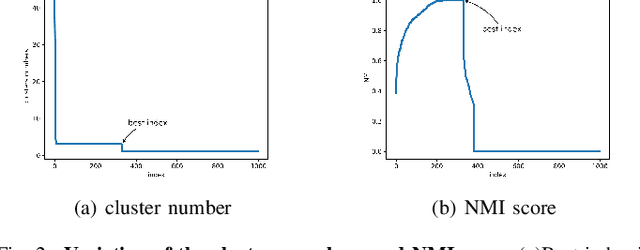
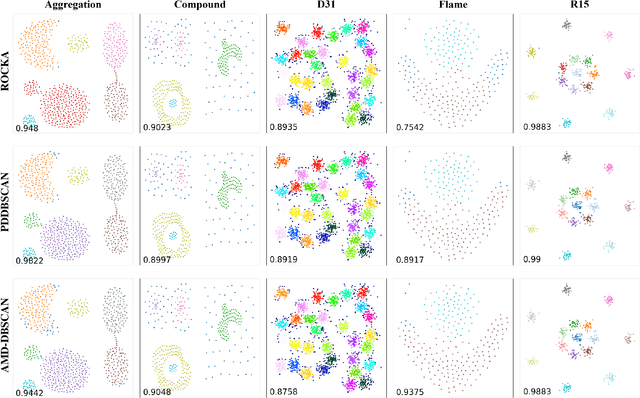
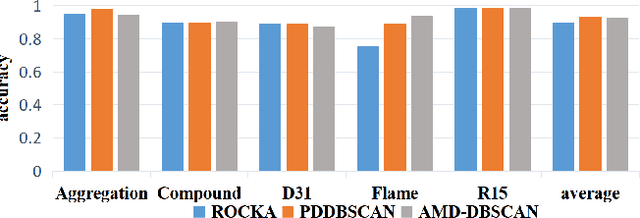
DBSCAN has been widely used in density-based clustering algorithms. However, with the increasing demand for Multi-density clustering, previous traditional DSBCAN can not have good clustering results on Multi-density datasets. In order to address this problem, an adaptive Multi-density DBSCAN algorithm (AMD-DBSCAN) is proposed in this paper. An improved parameter adaptation method is proposed in AMD-DBSCAN to search for multiple parameter pairs (i.e., Eps and MinPts), which are the key parameters to determine the clustering results and performance, therefore allowing the model to be applied to Multi-density datasets. Moreover, only one hyperparameter is required for AMD-DBSCAN to avoid the complicated repetitive initialization operations. Furthermore, the variance of the number of neighbors (VNN) is proposed to measure the difference in density between each cluster. The experimental results show that our AMD-DBSCAN reduces execution time by an average of 75% due to lower algorithm complexity compared with the traditional adaptive algorithm. In addition, AMD-DBSCAN improves accuracy by 24.7% on average over the state-of-the-art design on Multi-density datasets of extremely variable density, while having no performance loss in Single-density scenarios.
Explanations from Large Language Models Make Small Reasoners Better
Oct 13, 2022
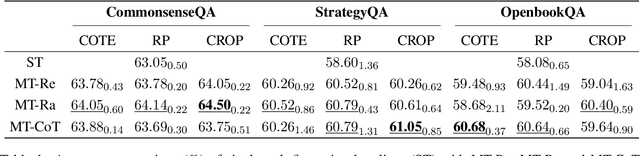
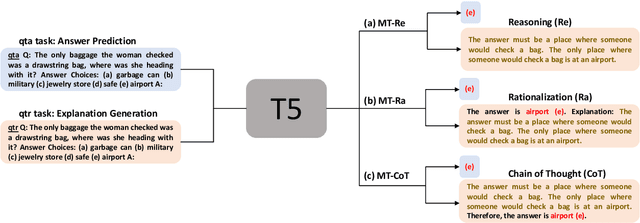
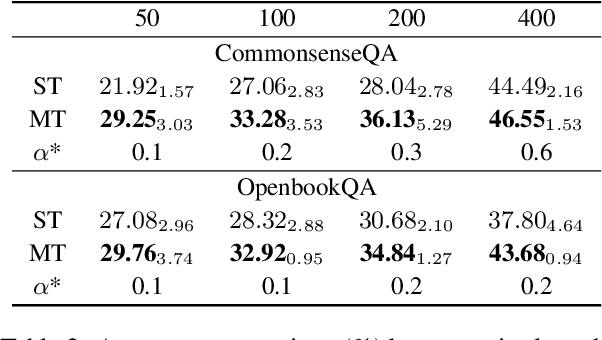
Integrating free-text explanations to in-context learning of large language models (LLM) is shown to elicit strong reasoning capabilities along with reasonable explanations. In this paper, we consider the problem of leveraging the explanations generated by LLM to improve the training of small reasoners, which are more favorable in real-production deployment due to their low cost. We systematically explore three explanation generation approaches from LLM and utilize a multi-task learning framework to facilitate small models to acquire strong reasoning power together with explanation generation capabilities. Experiments on multiple reasoning tasks show that our method can consistently and significantly outperform finetuning baselines across different settings, and even perform better than finetuning/prompting a 60x larger GPT-3 (175B) model by up to 9.5% in accuracy. As a side benefit, human evaluation further shows that our method can generate high-quality explanations to justify its predictions, moving towards the goal of explainable AI.
OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering
Jul 08, 2022
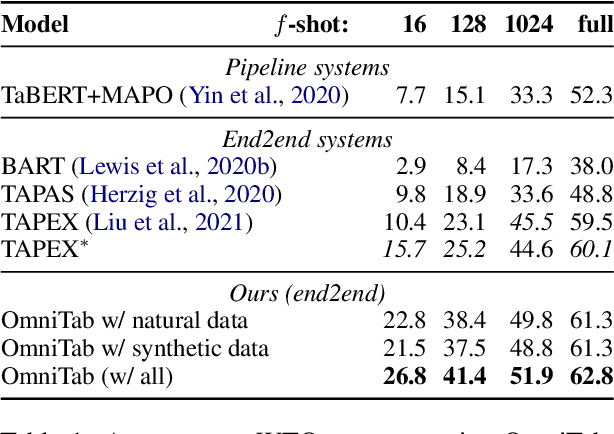
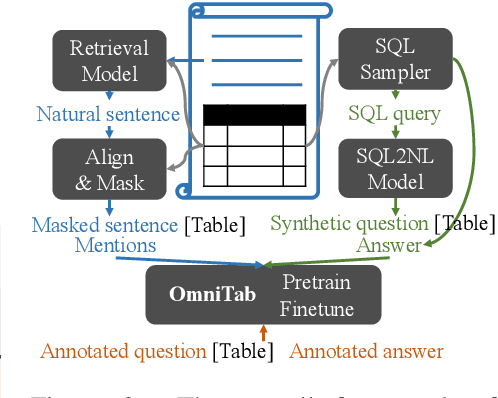

The information in tables can be an important complement to text, making table-based question answering (QA) systems of great value. The intrinsic complexity of handling tables often adds an extra burden to both model design and data annotation. In this paper, we aim to develop a simple table-based QA model with minimal annotation effort. Motivated by the fact that table-based QA requires both alignment between questions and tables and the ability to perform complicated reasoning over multiple table elements, we propose an omnivorous pretraining approach that consumes both natural and synthetic data to endow models with these respective abilities. Specifically, given freely available tables, we leverage retrieval to pair them with relevant natural sentences for mask-based pretraining, and synthesize NL questions by converting SQL sampled from tables for pretraining with a QA loss. We perform extensive experiments in both few-shot and full settings, and the results clearly demonstrate the superiority of our model OmniTab, with the best multitasking approach achieving an absolute gain of 16.2% and 2.7% in 128-shot and full settings respectively, also establishing a new state-of-the-art on WikiTableQuestions. Detailed ablations and analyses reveal different characteristics of natural and synthetic data, shedding light on future directions in omnivorous pretraining. Code, pretraining data, and pretrained models are available at https://github.com/jzbjyb/OmniTab.
An End-to-End Dialogue Summarization System for Sales Calls
Apr 28, 2022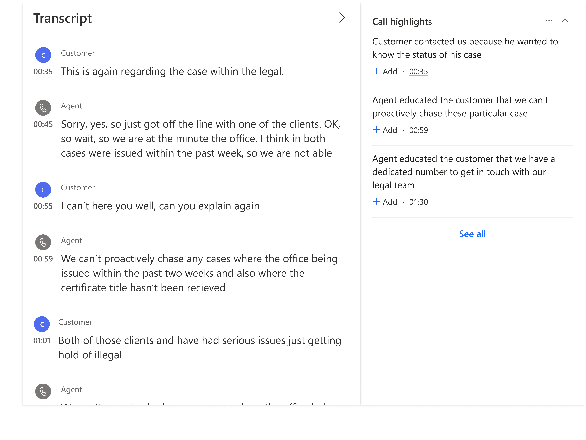
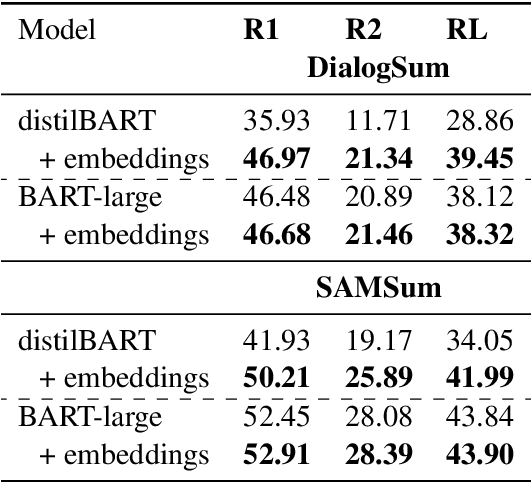
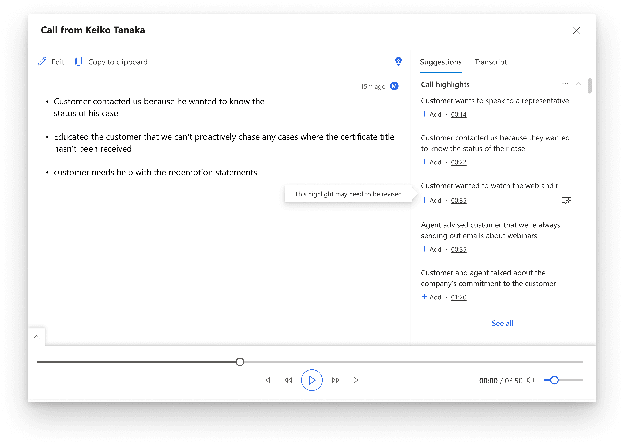
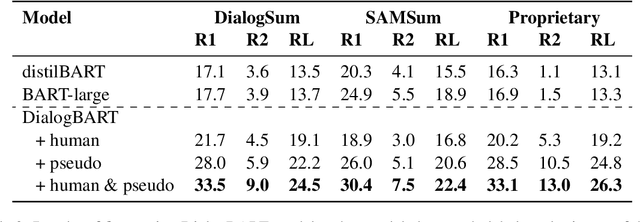
Summarizing sales calls is a routine task performed manually by salespeople. We present a production system which combines generative models fine-tuned for customer-agent setting, with a human-in-the-loop user experience for an interactive summary curation process. We address challenging aspects of dialogue summarization task in a real-world setting including long input dialogues, content validation, lack of labeled data and quality evaluation. We show how GPT-3 can be leveraged as an offline data labeler to handle training data scarcity and accommodate privacy constraints in an industrial setting. Experiments show significant improvements by our models in tackling the summarization and content validation tasks on public datasets.