 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Distributional Shifts in Large Language Models for Code Analysis
Mar 16, 2023We systematically study the capacity of two large language models for code - CodeT5 and Codex - to generalize to out-of-domain data. In this study, we consider two fundamental applications - code summarization, and code generation. We split data into domains following its natural boundaries - by an organization, by a project, and by a module within the software project. This makes recognition of in-domain vs out-of-domain data at the time of deployment trivial. We establish that samples from each new domain present both models with a significant challenge of distribution shift. We study how well different established methods can adapt models to better generalize to new domains. Our experiments show that while multitask learning alone is a reasonable baseline, combining it with few-shot finetuning on examples retrieved from training data can achieve very strong performance. In fact, according to our experiments, this solution can outperform direct finetuning for very low-data scenarios. Finally, we consider variations of this approach to create a more broadly applicable method to adapt to multiple domains at once. We find that in the case of code generation, a model adapted to multiple domains simultaneously performs on par with those adapted to each domain individually.
NS3: Neuro-Symbolic Semantic Code Search
May 21, 2022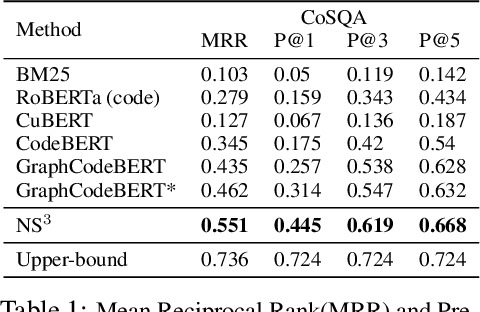
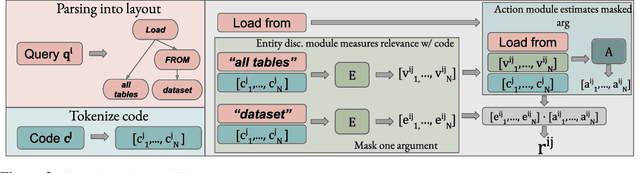
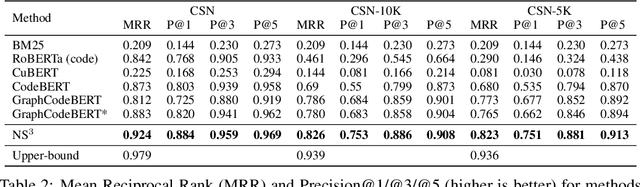
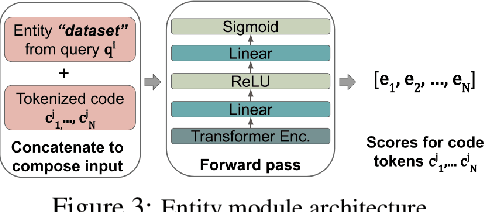
Semantic code search is the task of retrieving a code snippet given a textual description of its functionality. Recent work has been focused on using similarity metrics between neural embeddings of text and code. However, current language models are known to struggle with longer, compositional text, and multi-step reasoning. To overcome this limitation, we propose supplementing the query sentence with a layout of its semantic structure. The semantic layout is used to break down the final reasoning decision into a series of lower-level decisions. We use a Neural Module Network architecture to implement this idea. We compare our model - NS3 (Neuro-Symbolic Semantic Search) - to a number of baselines, including state-of-the-art semantic code retrieval methods, and evaluate on two datasets - CodeSearchNet and Code Search and Question Answering. We demonstrate that our approach results in more precise code retrieval, and we study the effectiveness of our modular design when handling compositional queries.
Towards Learning Representations of Binary Executable Files for Security Tasks
Feb 09, 2020


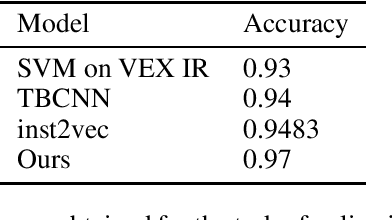
Tackling binary analysis problems has traditionally implied manually defining rules and heuristics. As an alternative, we are suggesting using machine learning models for learning distributed representations of binaries that can be applicable for a number of downstream tasks. We construct a computational graph from the binary executable and use it with a graph convolutional neural network to learn a high dimensional representation of the program. We show the versatility of this approach by using our representations to solve two semantically different binary analysis tasks -- algorithm classification and vulnerability discovery. We compare the proposed approach to our own strong baseline as well as published results and demonstrate improvement on the state of the art methods for both tasks.