 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Rankings are Unforgeable Language Model Signatures
Jun 03, 2026Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
DRInQ: Evaluating Conversational Implicature with Controlled Context Variation
May 22, 2026Human conversation relies heavily on conversational implicature, in which speakers convey meanings that are suggested rather than explicitly stated. Although recent large language models exhibit strong conversational fluency, they remain unreliable when interpretation depends on reasoning that integrates social and contextual cues, a process rarely articulated in text. We introduce DRinQ, a benchmark for evaluating pragmatic reasoning about conversational implicature in question utterances, designed to isolate pragmatic variation while holding each question's surface form fixed. To support scalable evaluation, we propose a semi-automated pipeline that produces question-context-interpretation instances with systematic variation. Across evaluations, we find a consistent generation-inference asymmetry: while state-of-the-art models can generate plausible pragmatic scenarios when guided, they often fail to recover the intended implication at inference time. For smaller models, structured prompting improves alignment with human judgments. A comparative writing study further reveals complementary strengths: human authors tend to produce safer, predictable contexts, whereas models generate varied scenarios with interpretations that sometimes exceed contextual support. These findings highlight persistent challenges in modeling conversational implicature and motivate more context-sensitive evaluation frameworks.
OpaqueToolsBench: Learning Nuances of Tool Behavior Through Interaction
Feb 16, 2026Tool-calling is essential for Large Language Model (LLM) agents to complete real-world tasks. While most existing benchmarks assume simple, perfectly documented tools, real-world tools (e.g., general "search" APIs) are often opaque, lacking clear best practices or failure modes. Can LLM agents improve their performance in environments with opaque tools by interacting and subsequently improving documentation? To study this, we create OpaqueToolsBench, a benchmark consisting of three distinct task-oriented environments: general function calling, interactive chess playing, and long-trajectory agentic search. Each environment provides underspecified tools that models must learn to use effectively to complete the task. Results on OpaqueToolsBench suggest existing methods for automatically documenting tools are expensive and unreliable when tools are opaque. To address this, we propose a simple framework, ToolObserver, that iteratively refines tool documentation by observing execution feedback from tool-calling trajectories. Our approach outperforms existing methods on OpaqueToolsBench across datasets, even in relatively hard settings. Furthermore, for test-time tool exploration settings, our method is also efficient, consuming 3.5-7.5x fewer total tokens than the best baseline.
DIAL-SUMMER: A Structured Evaluation Framework of Hierarchical Errors in Dialogue Summaries
Feb 08, 2026Dialogues are a predominant mode of communication for humans, and it is immensely helpful to have automatically generated summaries of them (e.g., to revise key points discussed in a meeting, to review conversations between customer agents and product users). Prior works on dialogue summary evaluation largely ignore the complexities specific to this task: (i) shift in structure, from multiple speakers discussing information in a scattered fashion across several turns, to a summary's sentences, and (ii) shift in narration viewpoint, from speakers' first/second-person narration, standardized third-person narration in the summary. In this work, we introduce our framework DIALSUMMER to address the above. We propose DIAL-SUMMER's taxonomy of errors to comprehensively evaluate dialogue summaries at two hierarchical levels: DIALOGUE-LEVEL that focuses on the broader speakers/turns, and WITHIN-TURN-LEVEL that focuses on the information talked about inside a turn. We then present DIAL-SUMMER's dataset composed of dialogue summaries manually annotated with our taxonomy's fine-grained errors. We conduct empirical analyses of these annotated errors, and observe interesting trends (e.g., turns occurring in middle of the dialogue are the most frequently missed in the summary, extrinsic hallucinations largely occur at the end of the summary). We also conduct experiments on LLM-Judges' capability at detecting these errors, through which we demonstrate the challenging nature of our dataset, the robustness of our taxonomy, and the need for future work in this field to enhance LLMs' performance in the same. Code and inference dataset coming soon.
Segment-Level Attribution for Selective Learning of Long Reasoning Traces
Jan 31, 2026Large Reasoning Models (LRMs) achieve strong reasoning performance by generating long chains of thought (CoTs), yet only a small fraction of these traces meaningfully contributes to answer prediction, while the majority contains repetitive or truncated content. Such output redundancy is further propagated after supervised finetuning (SFT), as models learn to imitate verbose but uninformative patterns, which can degrade performance. To this end, we incorporate integrated gradient attribution to quantify each token's influence on final answers and aggregate them into two segment-level metrics: (1) \textit{attribution strength} measures the overall attribution magnitude; and (2) \textit{direction consistency} captures whether tokens' attributions within a segment are uniformly positive or negative (high consistency), or a mixture of both (moderate consistency). Based on these two metrics, we propose a segment-level selective learning framework to identify important segments with high attribution strength but moderate consistency that indicate reflective rather than shallow reasoning. The framework then applies selective SFT on these important segments while masking loss for unimportant ones. Experiments across multiple models and datasets show that our approach improves accuracy and output efficiency, enabling more effective learning from long reasoning traces~\footnote{Code and data are available at https://github.com/SiyuanWangw/SegmentSelectiveSFT}.
Every Language Model Has a Forgery-Resistant Signature
Oct 15, 2025



The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying models by their outputs. One successful approach to these goals has been to exploit the geometric constraints imposed by the language model architecture and parameters. In this work, we show that a lesser-known geometric constraint--namely, that language model outputs lie on the surface of a high-dimensional ellipse--functions as a signature for the model and can be used to identify the source model of a given output. This ellipse signature has unique properties that distinguish it from existing model-output association methods like language model fingerprints. In particular, the signature is hard to forge: without direct access to model parameters, it is practically infeasible to produce log-probabilities (logprobs) on the ellipse. Secondly, the signature is naturally occurring, since all language models have these elliptical constraints. Thirdly, the signature is self-contained, in that it is detectable without access to the model inputs or the full weights. Finally, the signature is compact and redundant, as it is independently detectable in each logprob output from the model. We evaluate a novel technique for extracting the ellipse from small models and discuss the practical hurdles that make it infeasible for production-scale models. Finally, we use ellipse signatures to propose a protocol for language model output verification, analogous to cryptographic symmetric-key message authentication systems.
ELI-Why: Evaluating the Pedagogical Utility of Language Model Explanations
Jun 17, 2025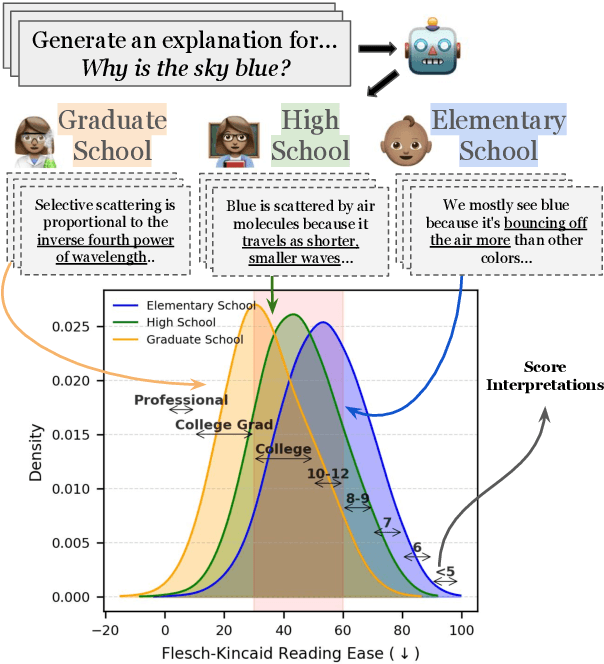
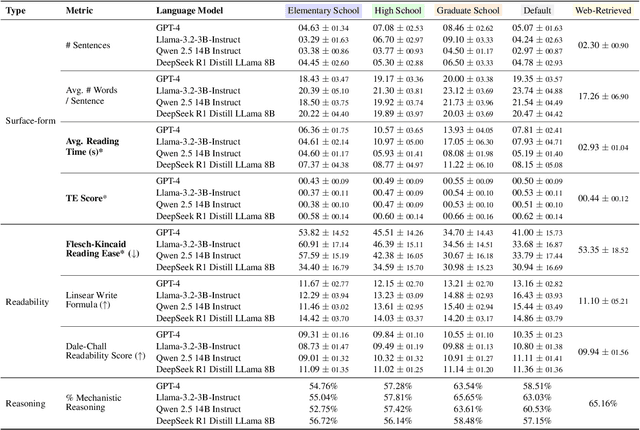
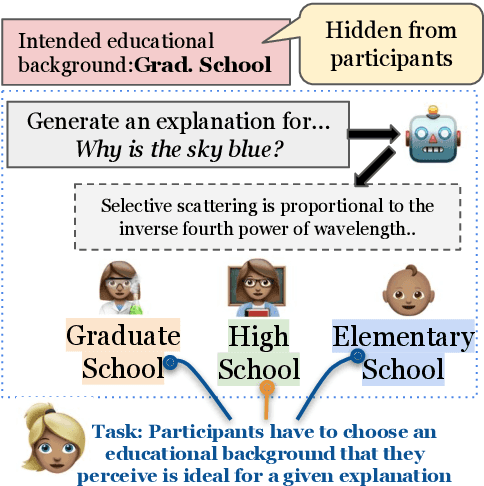

Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations' fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
Amulet: Putting Complex Multi-Turn Conversations on the Stand with LLM Juries
May 26, 2025


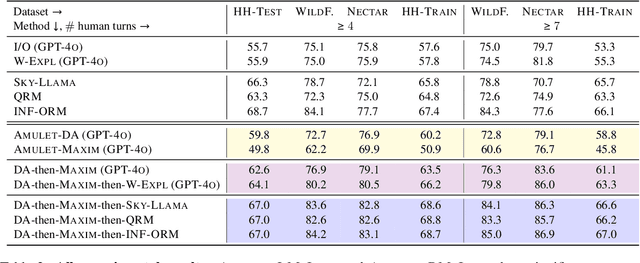
Today, large language models are widely used as judges to evaluate responses from other language models. Hence, it is imperative to benchmark and improve these LLM-judges on real-world language model usage: a typical human-assistant conversation is lengthy, and shows significant diversity in topics, intents, and requirements across turns, e.g. social interactions, task requests, feedback. We present Amulet, a framework that leverages pertinent linguistic concepts of dialog-acts and maxims to improve the accuracy of LLM-judges on preference data with complex, multi-turn conversational context. Amulet presents valuable insights about (a) the communicative structures and intents present in the conversation (dialog acts), and (b) the satisfaction of conversational principles (maxims) by the preference responses, and uses them to make judgments. On four challenging datasets, Amulet shows that (a) humans frequently (60 to 70 percent of the time) change their intents from one turn of the conversation to the next, and (b) in 75 percent of instances, the preference responses can be differentiated via dialog acts and/or maxims, reiterating the latter's significance in judging such data. Amulet can be used either as a judge by applying the framework to a single LLM, or integrated into a jury with different LLM judges; our judges and juries show strong improvements on relevant baselines for all four datasets.
Improving LLM Personas via Rationalization with Psychological Scaffolds
Apr 25, 2025Language models prompted with a user description or persona can predict a user's preferences and opinions, but existing approaches to building personas -- based solely on a user's demographic attributes and/or prior judgments -- fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user's behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds -- structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs -- that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user's demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
Stepwise Informativeness Search for Improving LLM Reasoning
Feb 21, 2025Advances in Large Language Models (LLMs) have significantly improved multi-step reasoning through generating free-text rationales. However, recent studies show that LLMs tend to lose focus over the middle of long contexts. This raises concerns that as reasoning progresses, LLMs may overlook information in earlier steps when decoding subsequent steps, leading to generate unreliable and redundant rationales. To address this, we propose guiding LLMs to generate more accurate and concise step-by-step rationales by (1) proactively referencing information from underutilized prior steps, and (2) minimizing redundant information between new and existing steps. We introduce stepwise informativeness search, an inference-time tree search framework incorporating two selection heuristics: grounding-guided selection which prioritizes steps paying higher attention over underutilized steps; and novelty-guided selection which encourages steps with novel conclusions. During rationale generation, we use a self-grounding strategy that prompts LLMs to explicitly reference relevant prior steps to provide premises before deduction at each step. Experimental results on four reasoning datasets demonstrate that our approach improves reasoning accuracy by generating higher-quality rationales with reduced errors and redundancy.