 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Rankings are Unforgeable Language Model Signatures
Jun 03, 2026Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
Side-by-side Comparison Amplifies Dialect Bias in Language Models
May 23, 2026Language models (LMs) can exhibit systematic biases against speakers based on variations in their dialects, even in the absence of a dialect label, a behavior known as covert dialect bias. In this work, we quantify covert dialect bias in online discourse by evaluating how LMs associate stereotypical traits (derived from social psychology research on racial bias) with intent-equivalent tweets in Standard American English (SAE) and African-American Vernacular English (AAVE). While prior work shows that LMs associate more negative stereotypes with AAVE when evaluating tweets in isolation, we are surprised to find that this bias is significantly exacerbated when SAE / AAVE tweet pairs are compared side by side, a setting that more closely reflects high-impact decision making contexts in which models are used to rank candidates. The bias only worsens when dialect labels are explicitly specified. This is striking, given the extensive efforts from commercial developers to mitigate bias in their LMs. Encouragingly, we show that counterfactual fairness finetuning can mitigate covert dialect bias for some stereotypical traits, reducing average disparities when evaluating tweets in isolation, however, these improvements do not consistently hold across traits when evaluating SAE / AAVE tweets side by side. Our findings show that existing evaluation settings for covert dialect bias may underestimate its severity, specifically in contrastive settings. Additionally, overt dialect bias remains pronounced even after safety aligned finetuning, indicating that it remains an unresolved problem, and motivates the need for more robust evaluation and mitigation frameworks.
Disentangling Geometry, Performance, and Training in Language Models
Feb 24, 2026Geometric properties of Transformer weights, particularly the unembedding matrix, have been widely useful in language model interpretability research. Yet, their utility for estimating downstream performance remains unclear. In this work, we systematically investigate the relationship between model performance and the unembedding matrix geometry, particularly its effective rank. Our experiments, involving a suite of 108 OLMo-style language models trained under controlled variation, reveal several key findings. While the best-performing models often exhibit a high effective rank, this trend is not universal across tasks and training setups. Contrary to prior work, we find that low effective rank does not cause late-stage performance degradation in small models, but instead co-occurs with it; we find adversarial cases where low-rank models do not exhibit saturation. Moreover, we show that effective rank is strongly influenced by pre-training hyperparameters, such as batch size and weight decay, which in-turn affect the model's performance. Lastly, extending our analysis to other geometric metrics and final-layer representation, we find that these metrics are largely aligned, but none can reliably predict downstream performance. Overall, our findings suggest that the model's geometry, as captured by existing metrics, primarily reflects training choices rather than performance.
ChEmREF: Evaluating Language Model Readiness for Chemical Emergency Response
Nov 14, 2025Emergency responders managing hazardous material HAZMAT incidents face critical, time-sensitive decisions, manually navigating extensive chemical guidelines. We investigate whether today's language models can assist responders by rapidly and reliably understanding critical information, identifying hazards, and providing recommendations. We introduce the Chemical Emergency Response Evaluation Framework (ChEmREF), a new benchmark comprising questions on 1,035 HAZMAT chemicals from the Emergency Response Guidebook and the PubChem Database. ChEmREF is organized into three tasks: (1) translation of chemical representation between structured and unstructured forms (e.g., converting C2H6O to ethanol), (2) emergency response generation (e.g., recommending appropriate evacuation distances) and (3) domain knowledge question answering from chemical safety and certification exams. Our best evaluated models received an exact match of 68.0% on unstructured HAZMAT chemical representation translation, a LLM Judge score of 52.7% on incident response recommendations, and a multiple-choice accuracy of 63.9% on HAMZAT examinations. These findings suggest that while language models show potential to assist emergency responders in various tasks, they require careful human oversight due to their current limitations.
Every Language Model Has a Forgery-Resistant Signature
Oct 15, 2025



The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying models by their outputs. One successful approach to these goals has been to exploit the geometric constraints imposed by the language model architecture and parameters. In this work, we show that a lesser-known geometric constraint--namely, that language model outputs lie on the surface of a high-dimensional ellipse--functions as a signature for the model and can be used to identify the source model of a given output. This ellipse signature has unique properties that distinguish it from existing model-output association methods like language model fingerprints. In particular, the signature is hard to forge: without direct access to model parameters, it is practically infeasible to produce log-probabilities (logprobs) on the ellipse. Secondly, the signature is naturally occurring, since all language models have these elliptical constraints. Thirdly, the signature is self-contained, in that it is detectable without access to the model inputs or the full weights. Finally, the signature is compact and redundant, as it is independently detectable in each logprob output from the model. We evaluate a novel technique for extracting the ellipse from small models and discuss the practical hurdles that make it infeasible for production-scale models. Finally, we use ellipse signatures to propose a protocol for language model output verification, analogous to cryptographic symmetric-key message authentication systems.
ELI-Why: Evaluating the Pedagogical Utility of Language Model Explanations
Jun 17, 2025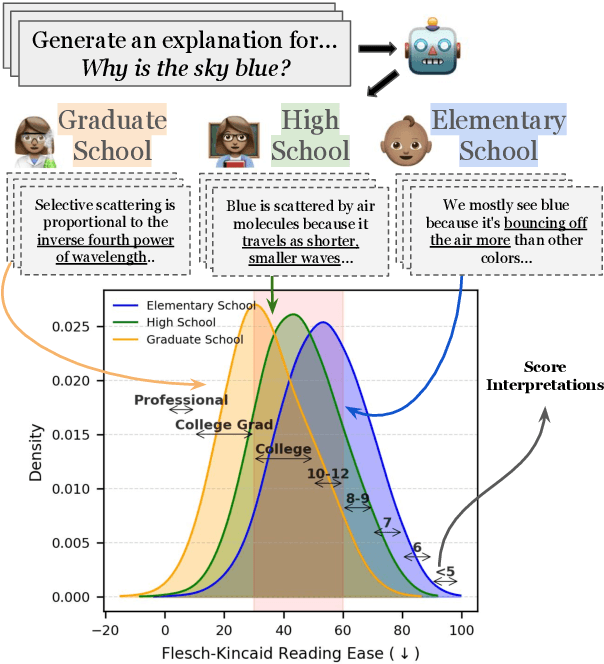
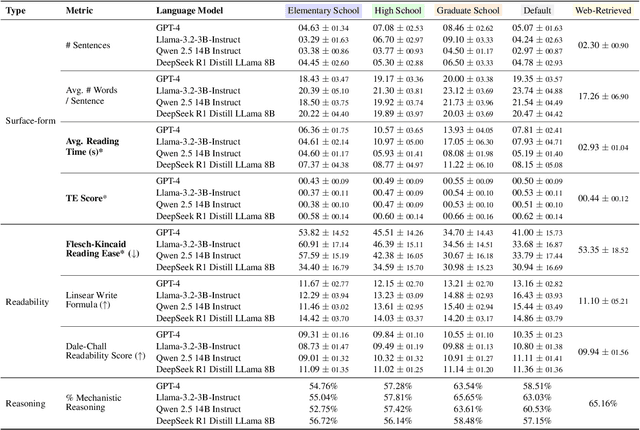
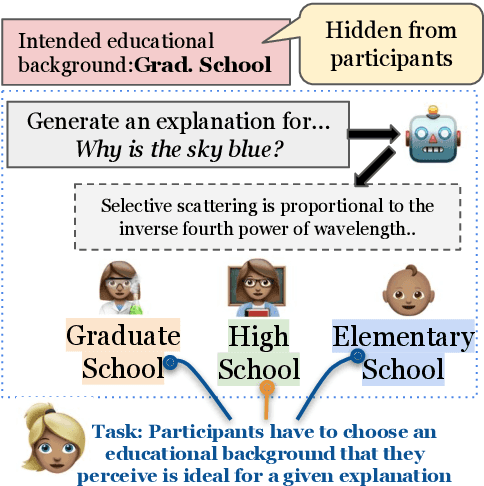

Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations' fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
Teaching Models to Understand (but not Generate) High-risk Data
May 05, 2025Language model developers typically filter out high-risk content -- such as toxic or copyrighted text -- from their pre-training data to prevent models from generating similar outputs. However, removing such data altogether limits models' ability to recognize and appropriately respond to harmful or sensitive content. In this paper, we introduce Selective Loss to Understand but Not Generate (SLUNG), a pre-training paradigm through which models learn to understand high-risk data without learning to generate it. Instead of uniformly applying the next-token prediction loss, SLUNG selectively avoids incentivizing the generation of high-risk tokens while ensuring they remain within the model's context window. As the model learns to predict low-risk tokens that follow high-risk ones, it is forced to understand the high-risk content. Through our experiments, we show that SLUNG consistently improves models' understanding of high-risk data (e.g., ability to recognize toxic content) without increasing its generation (e.g., toxicity of model responses). Overall, our SLUNG paradigm enables models to benefit from high-risk text that would otherwise be filtered out.
Improving LLM Personas via Rationalization with Psychological Scaffolds
Apr 25, 2025Language models prompted with a user description or persona can predict a user's preferences and opinions, but existing approaches to building personas -- based solely on a user's demographic attributes and/or prior judgments -- fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user's behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds -- structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs -- that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user's demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
Evaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
Evaluation Under Imperfect Benchmarks and Ratings: A Case Study in Text Simplification
Apr 15, 2025
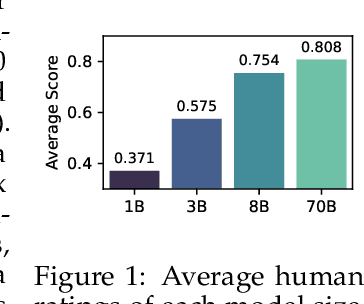


Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.