 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Training Modulates Harmful Misalignment Under On-Policy RL, But Direction Depends on Environment Design
Apr 14, 2026Specification gaming under Reinforcement Learning (RL) is known to cause LLMs to develop sycophantic, manipulative, or deceptive behavior, yet the conditions under which this occurs remain unclear. We train 11 instruction-tuned LLMs (0.5B--14B) with on-policy RL across 3 environments and find that model size acts as a safety buffer in some environments but enables greater harmful exploitation in others. Controlled ablations trace this reversal to environment-specific features such as role framing and implicit gameability cues. We further show that most safety benchmarks do not predict RL-induced misalignment, except in the case of Sycophancy scores when the exploit relies on inferring the user's preference. Finally, we find that on-policy RL preserves a safety buffer inherent in the model's own generation distribution, one that is bypassed during off-policy settings.
Not All Subjectivity Is the Same! Defining Desiderata for the Evaluation of Subjectivity in NLP
Mar 30, 2026Subjective judgments are part of several NLP datasets and recent work is increasingly prioritizing models whose outputs reflect this diversity of perspectives. Such responses allow us to shed light on minority voices, which are frequently marginalized or obscured by dominant perspectives. It remains a question whether our evaluation practices align with these models' objectives. This position paper proposes seven evaluation desiderata for subjectivity-sensitive models, rooted in how subjectivity is represented in NLP data and models. The desiderata are constructed in a top-down approach, keeping in mind the user-centric impact of such models. We scan the experimental setup of 60 papers and show that various aspects of subjectivity are still understudied: the distinction between ambiguous and polyphonic input, whether subjectivity is effectively expressed to the user, and a lack of interplay between different desiderata, amongst other gaps.
Improving Causal Interventions in Amnesic Probing with Mean Projection or LEACE
Jun 13, 2025Amnesic probing is a technique used to examine the influence of specific linguistic information on the behaviour of a model. This involves identifying and removing the relevant information and then assessing whether the model's performance on the main task changes. If the removed information is relevant, the model's performance should decline. The difficulty with this approach lies in removing only the target information while leaving other information unchanged. It has been shown that Iterative Nullspace Projection (INLP), a widely used removal technique, introduces random modifications to representations when eliminating target information. We demonstrate that Mean Projection (MP) and LEACE, two proposed alternatives, remove information in a more targeted manner, thereby enhancing the potential for obtaining behavioural explanations through Amnesic Probing.
Short-circuiting Shortcuts: Mechanistic Investigation of Shortcuts in Text Classification
May 09, 2025Reliance on spurious correlations (shortcuts) has been shown to underlie many of the successes of language models. Previous work focused on identifying the input elements that impact prediction. We investigate how shortcuts are actually processed within the model's decision-making mechanism. We use actor names in movie reviews as controllable shortcuts with known impact on the outcome. We use mechanistic interpretability methods and identify specific attention heads that focus on shortcuts. These heads gear the model towards a label before processing the complete input, effectively making premature decisions that bypass contextual analysis. Based on these findings, we introduce Head-based Token Attribution (HTA), which traces intermediate decisions back to input tokens. We show that HTA is effective in detecting shortcuts in LLMs and enables targeted mitigation by selectively deactivating shortcut-related attention heads.
DefVerify: Do Hate Speech Models Reflect Their Dataset's Definition?
Oct 21, 2024



When building a predictive model, it is often difficult to ensure that domain-specific requirements are encoded by the model that will eventually be deployed. Consider researchers working on hate speech detection. They will have an idea of what is considered hate speech, but building a model that reflects their view accurately requires preserving those ideals throughout the workflow of data set construction and model training. Complications such as sampling bias, annotation bias, and model misspecification almost always arise, possibly resulting in a gap between the domain specification and the model's actual behavior upon deployment. To address this issue for hate speech detection, we propose DefVerify: a 3-step procedure that (i) encodes a user-specified definition of hate speech, (ii) quantifies to what extent the model reflects the intended definition, and (iii) tries to identify the point of failure in the workflow. We use DefVerify to find gaps between definition and model behavior when applied to six popular hate speech benchmark datasets.
Crowd-Calibrator: Can Annotator Disagreement Inform Calibration in Subjective Tasks?
Aug 26, 2024



Subjective tasks in NLP have been mostly relegated to objective standards, where the gold label is decided by taking the majority vote. This obfuscates annotator disagreement and the inherent uncertainty of the label. We argue that subjectivity should factor into model decisions and play a direct role via calibration under a selective prediction setting. Specifically, instead of calibrating confidence purely from the model's perspective, we calibrate models for subjective tasks based on crowd worker agreement. Our method, Crowd-Calibrator, models the distance between the distribution of crowd worker labels and the model's own distribution over labels to inform whether the model should abstain from a decision. On two highly subjective tasks, hate speech detection and natural language inference, our experiments show Crowd-Calibrator either outperforms or achieves competitive performance with existing selective prediction baselines. Our findings highlight the value of bringing human decision-making into model predictions.
Balancing the Scales: Reinforcement Learning for Fair Classification
Jul 15, 2024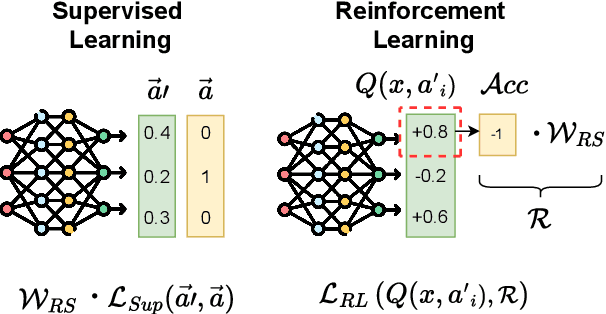
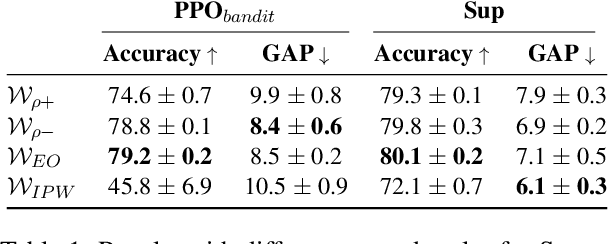
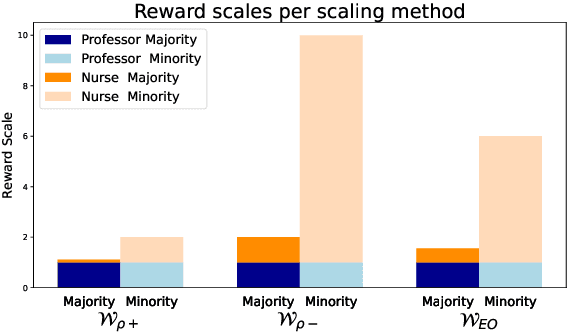
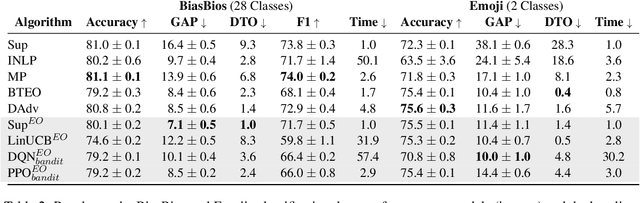
Fairness in classification tasks has traditionally focused on bias removal from neural representations, but recent trends favor algorithmic methods that embed fairness into the training process. These methods steer models towards fair performance, preventing potential elimination of valuable information that arises from representation manipulation. Reinforcement Learning (RL), with its capacity for learning through interaction and adjusting reward functions to encourage desired behaviors, emerges as a promising tool in this domain. In this paper, we explore the usage of RL to address bias in imbalanced classification by scaling the reward function to mitigate bias. We employ the contextual multi-armed bandit framework and adapt three popular RL algorithms to suit our objectives, demonstrating a novel approach to mitigating bias.
ARM: Efficient Guided Decoding with Autoregressive Reward Models
Jul 05, 2024



Language models trained on large amounts of data require careful tuning to be safely deployed in real world. We revisit the guided decoding paradigm, where the goal is to augment the logits of the base language model using the scores from a task-specific reward model. We propose a simple but efficient parameterization of the autoregressive reward model enabling fast and effective guided decoding. On detoxification and sentiment control tasks, we show that our efficient parameterization performs on par with RAD, a strong but less efficient guided decoding approach.
Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study
Apr 05, 2024For a viewpoint-diverse news recommender, identifying whether two news articles express the same viewpoint is essential. One way to determine "same or different" viewpoint is stance detection. In this paper, we investigate the robustness of operationalization choices for few-shot stance detection, with special attention to modelling stance across different topics. Our experiments test pre-registered hypotheses on stance detection. Specifically, we compare two stance task definitions (Pro/Con versus Same Side Stance), two LLM architectures (bi-encoding versus cross-encoding), and adding Natural Language Inference knowledge, with pre-trained RoBERTa models trained with shots of 100 examples from 7 different stance detection datasets. Some of our hypotheses and claims from earlier work can be confirmed, while others give more inconsistent results. The effect of the Same Side Stance definition on performance differs per dataset and is influenced by other modelling choices. We found no relationship between the number of training topics in the training shots and performance. In general, cross-encoding out-performs bi-encoding, and adding NLI training to our models gives considerable improvement, but these results are not consistent across all datasets. Our results indicate that it is essential to include multiple datasets and systematic modelling experiments when aiming to find robust modelling choices for the concept `stance'.
The Role of Syntactic Span Preferences in Post-Hoc Explanation Disagreement
Mar 28, 2024



Post-hoc explanation methods are an important tool for increasing model transparency for users. Unfortunately, the currently used methods for attributing token importance often yield diverging patterns. In this work, we study potential sources of disagreement across methods from a linguistic perspective. We find that different methods systematically select different classes of words and that methods that agree most with other methods and with humans display similar linguistic preferences. Token-level differences between methods are smoothed out if we compare them on the syntactic span level. We also find higher agreement across methods by estimating the most important spans dynamically instead of relying on a fixed subset of size $k$. We systematically investigate the interaction between $k$ and spans and propose an improved configuration for selecting important tokens.