 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Subjectivity Is the Same! Defining Desiderata for the Evaluation of Subjectivity in NLP
Mar 30, 2026Subjective judgments are part of several NLP datasets and recent work is increasingly prioritizing models whose outputs reflect this diversity of perspectives. Such responses allow us to shed light on minority voices, which are frequently marginalized or obscured by dominant perspectives. It remains a question whether our evaluation practices align with these models' objectives. This position paper proposes seven evaluation desiderata for subjectivity-sensitive models, rooted in how subjectivity is represented in NLP data and models. The desiderata are constructed in a top-down approach, keeping in mind the user-centric impact of such models. We scan the experimental setup of 60 papers and show that various aspects of subjectivity are still understudied: the distinction between ambiguous and polyphonic input, whether subjectivity is effectively expressed to the user, and a lack of interplay between different desiderata, amongst other gaps.
DefVerify: Do Hate Speech Models Reflect Their Dataset's Definition?
Oct 21, 2024



When building a predictive model, it is often difficult to ensure that domain-specific requirements are encoded by the model that will eventually be deployed. Consider researchers working on hate speech detection. They will have an idea of what is considered hate speech, but building a model that reflects their view accurately requires preserving those ideals throughout the workflow of data set construction and model training. Complications such as sampling bias, annotation bias, and model misspecification almost always arise, possibly resulting in a gap between the domain specification and the model's actual behavior upon deployment. To address this issue for hate speech detection, we propose DefVerify: a 3-step procedure that (i) encodes a user-specified definition of hate speech, (ii) quantifies to what extent the model reflects the intended definition, and (iii) tries to identify the point of failure in the workflow. We use DefVerify to find gaps between definition and model behavior when applied to six popular hate speech benchmark datasets.
Crowd-Calibrator: Can Annotator Disagreement Inform Calibration in Subjective Tasks?
Aug 26, 2024



Subjective tasks in NLP have been mostly relegated to objective standards, where the gold label is decided by taking the majority vote. This obfuscates annotator disagreement and the inherent uncertainty of the label. We argue that subjectivity should factor into model decisions and play a direct role via calibration under a selective prediction setting. Specifically, instead of calibrating confidence purely from the model's perspective, we calibrate models for subjective tasks based on crowd worker agreement. Our method, Crowd-Calibrator, models the distance between the distribution of crowd worker labels and the model's own distribution over labels to inform whether the model should abstain from a decision. On two highly subjective tasks, hate speech detection and natural language inference, our experiments show Crowd-Calibrator either outperforms or achieves competitive performance with existing selective prediction baselines. Our findings highlight the value of bringing human decision-making into model predictions.
Leveraging Few-Shot Data Augmentation and Waterfall Prompting for Response Generation
Aug 02, 2023



This paper discusses our approaches for task-oriented conversational modelling using subjective knowledge, with a particular emphasis on response generation. Our methodology was shaped by an extensive data analysis that evaluated key factors such as response length, sentiment, and dialogue acts present in the provided dataset. We used few-shot learning to augment the data with newly generated subjective knowledge items and present three approaches for DSTC11: (1) task-specific model exploration, (2) incorporation of the most frequent question into all generated responses, and (3) a waterfall prompting technique using a combination of both GPT-3 and ChatGPT.
Will It Blend? Mixing Training Paradigms & Prompting for Argument Quality Prediction
Oct 05, 2022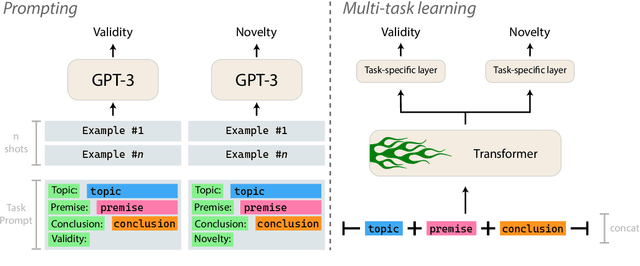

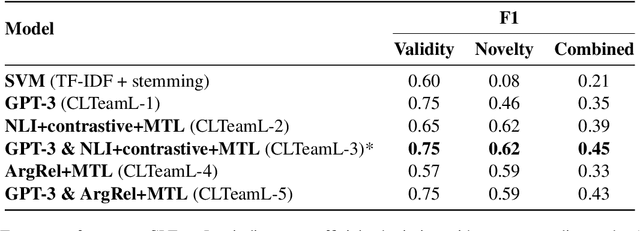
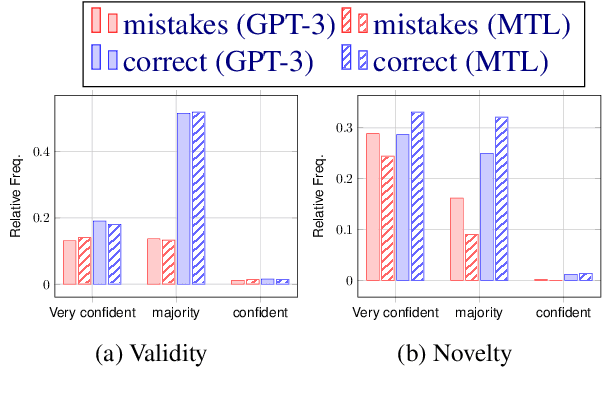
This paper describes our contributions to the Shared Task of the 9th Workshop on Argument Mining (2022). Our approach uses Large Language Models for the task of Argument Quality Prediction. We perform prompt engineering using GPT-3, and also investigate the training paradigms multi-task learning, contrastive learning, and intermediate-task training. We find that a mixed prediction setup outperforms single models. Prompting GPT-3 works best for predicting argument validity, and argument novelty is best estimated by a model trained using all three training paradigms.
Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions
Jun 30, 2022
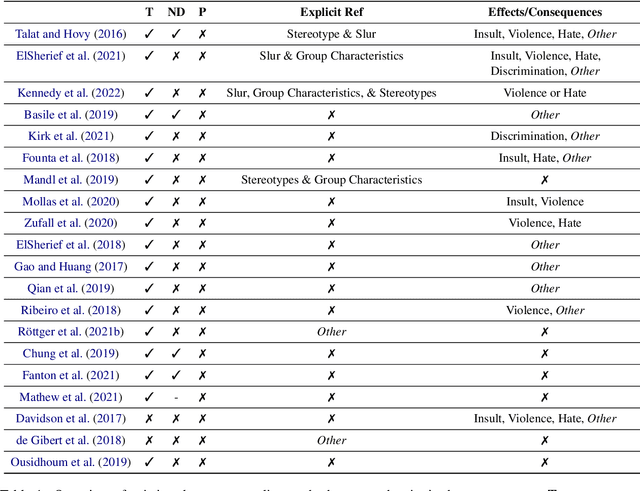
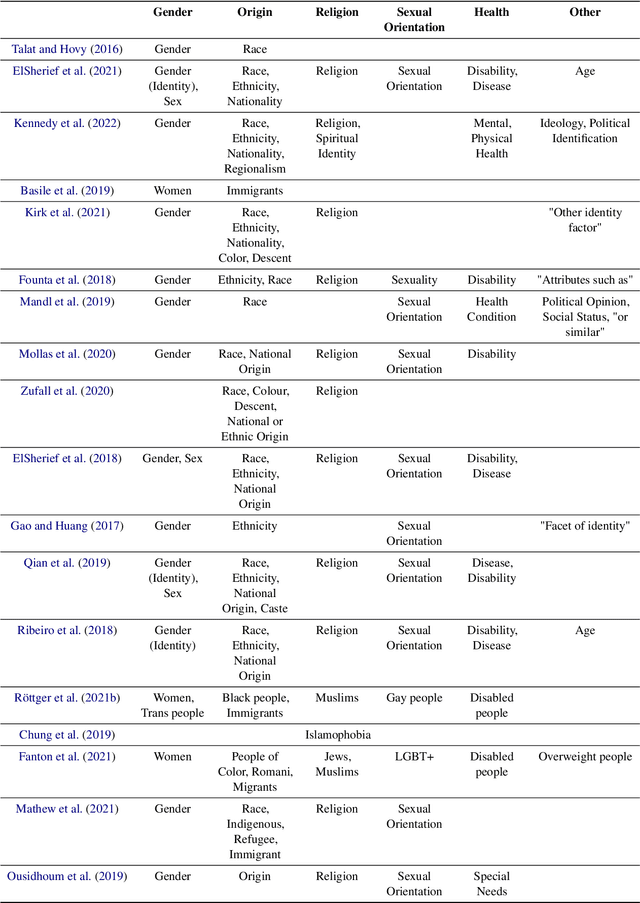
\textbf{Offensive Content Warning}: This paper contains offensive language only for providing examples that clarify this research and do not reflect the authors' opinions. Please be aware that these examples are offensive and may cause you distress. The subjectivity of recognizing \textit{hate speech} makes it a complex task. This is also reflected by different and incomplete definitions in NLP. We present \textit{hate speech} criteria, developed with perspectives from law and social science, with the aim of helping researchers create more precise definitions and annotation guidelines on five aspects: (1) target groups, (2) dominance, (3) perpetrator characteristics, (4) type of negative group reference, and the (5) type of potential consequences/effects. Definitions can be structured so that they cover a more broad or more narrow phenomenon. As such, conscious choices can be made on specifying criteria or leaving them open. We argue that the goal and exact task developers have in mind should determine how the scope of \textit{hate speech} is defined. We provide an overview of the properties of English datasets from \url{hatespeechdata.com} that may help select the most suitable dataset for a specific scenario.
How Emotionally Stable is ALBERT? Testing Robustness with Stochastic Weight Averaging on a Sentiment Analysis Task
Nov 18, 2021
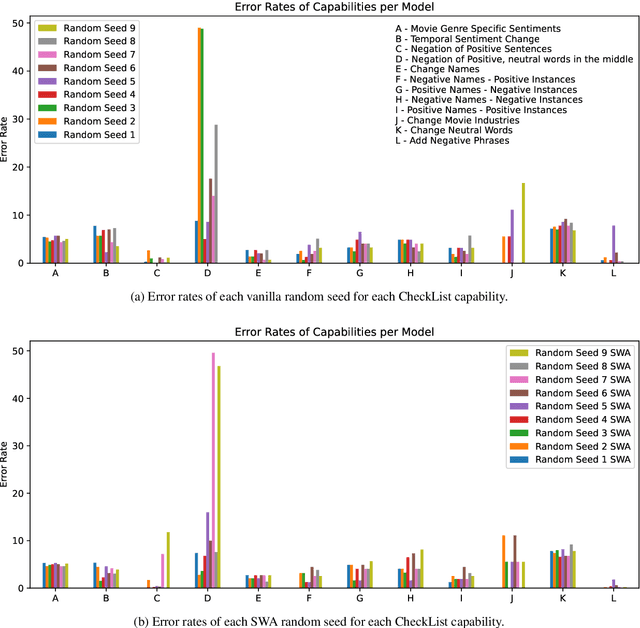
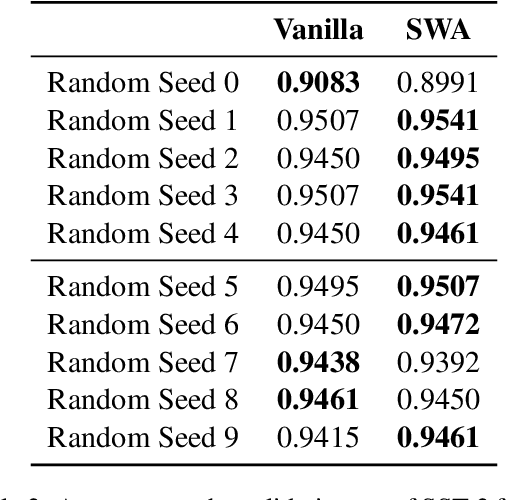
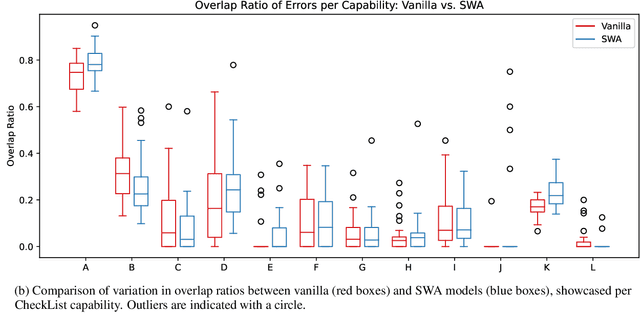
Despite their success, modern language models are fragile. Even small changes in their training pipeline can lead to unexpected results. We study this phenomenon by examining the robustness of ALBERT (arXiv:1909.11942) in combination with Stochastic Weight Averaging (SWA) (arXiv:1803.05407) -- a cheap way of ensembling -- on a sentiment analysis task (SST-2). In particular, we analyze SWA's stability via CheckList criteria (arXiv:2005.04118), examining the agreement on errors made by models differing only in their random seed. We hypothesize that SWA is more stable because it ensembles model snapshots taken along the gradient descent trajectory. We quantify stability by comparing the models' mistakes with Fleiss' Kappa (Fleiss, 1971) and overlap ratio scores. We find that SWA reduces error rates in general; yet the models still suffer from their own distinct biases (according to CheckList).