 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Jun 26, 2024
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
Leveraging Few-Shot Data Augmentation and Waterfall Prompting for Response Generation
Aug 02, 2023



This paper discusses our approaches for task-oriented conversational modelling using subjective knowledge, with a particular emphasis on response generation. Our methodology was shaped by an extensive data analysis that evaluated key factors such as response length, sentiment, and dialogue acts present in the provided dataset. We used few-shot learning to augment the data with newly generated subjective knowledge items and present three approaches for DSTC11: (1) task-specific model exploration, (2) incorporation of the most frequent question into all generated responses, and (3) a waterfall prompting technique using a combination of both GPT-3 and ChatGPT.
Will It Blend? Mixing Training Paradigms & Prompting for Argument Quality Prediction
Oct 05, 2022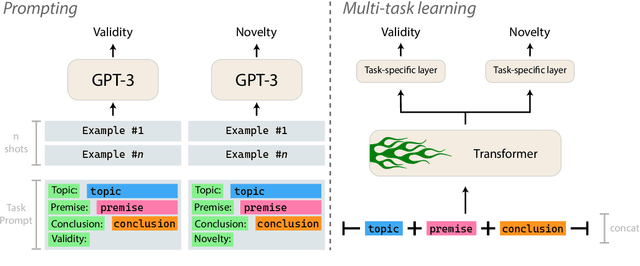

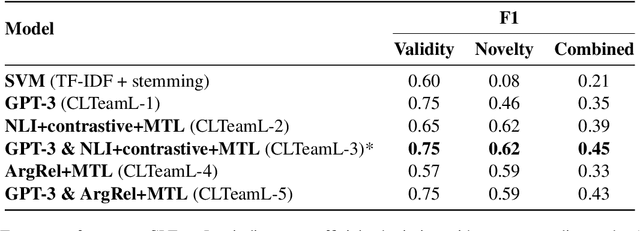
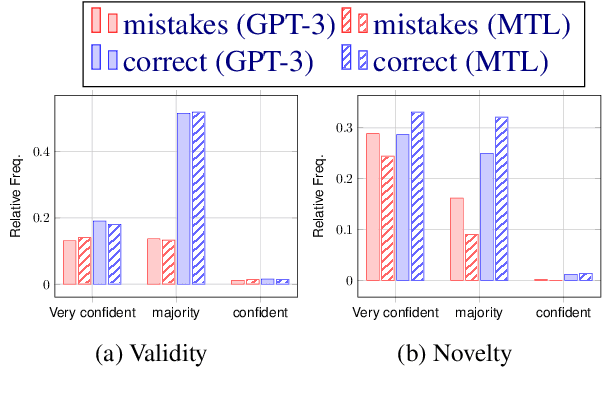
This paper describes our contributions to the Shared Task of the 9th Workshop on Argument Mining (2022). Our approach uses Large Language Models for the task of Argument Quality Prediction. We perform prompt engineering using GPT-3, and also investigate the training paradigms multi-task learning, contrastive learning, and intermediate-task training. We find that a mixed prediction setup outperforms single models. Prompting GPT-3 works best for predicting argument validity, and argument novelty is best estimated by a model trained using all three training paradigms.