 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Subjectivity Is the Same! Defining Desiderata for the Evaluation of Subjectivity in NLP
Mar 30, 2026Subjective judgments are part of several NLP datasets and recent work is increasingly prioritizing models whose outputs reflect this diversity of perspectives. Such responses allow us to shed light on minority voices, which are frequently marginalized or obscured by dominant perspectives. It remains a question whether our evaluation practices align with these models' objectives. This position paper proposes seven evaluation desiderata for subjectivity-sensitive models, rooted in how subjectivity is represented in NLP data and models. The desiderata are constructed in a top-down approach, keeping in mind the user-centric impact of such models. We scan the experimental setup of 60 papers and show that various aspects of subjectivity are still understudied: the distinction between ambiguous and polyphonic input, whether subjectivity is effectively expressed to the user, and a lack of interplay between different desiderata, amongst other gaps.
Traces of Social Competence in Large Language Models
Mar 04, 2026The False Belief Test (FBT) has been the main method for assessing Theory of Mind (ToM) and related socio-cognitive competencies. For Large Language Models (LLMs), the reliability and explanatory potential of this test have remained limited due to issues like data contamination, insufficient model details, and inconsistent controls. We address these issues by testing 17 open-weight models on a balanced set of 192 FBT variants (Trott et al. 2023) using Bayesian Logistic regression to identify how model size and post-training affect socio-cognitive competence. We find that scaling model size benefits performance, but not strictly. A cross-over effect reveals that explicating propositional attitudes (X thinks) fundamentally alters response patterns. Instruction tuning partially mitigates this effect, but further reasoning-oriented finetuning amplifies it. In a case study analysing social reasoning ability throughout OLMo 2 training, we show that this cross-over effect emerges during pre-training, suggesting that models acquire stereotypical response patterns tied to mental-state vocabulary that can outweigh other scenario semantics. Finally, vector steering allows us to isolate a think vector as the causal driver of observed FBT behaviour.
HintsOfTruth: A Multimodal Checkworthiness Detection Dataset with Real and Synthetic Claims
Feb 17, 2025
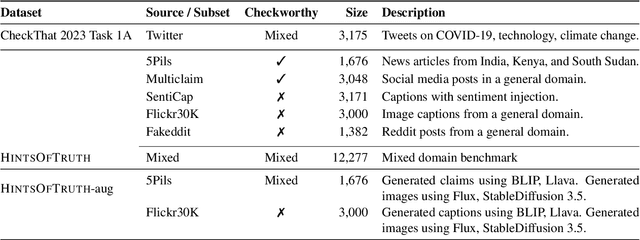
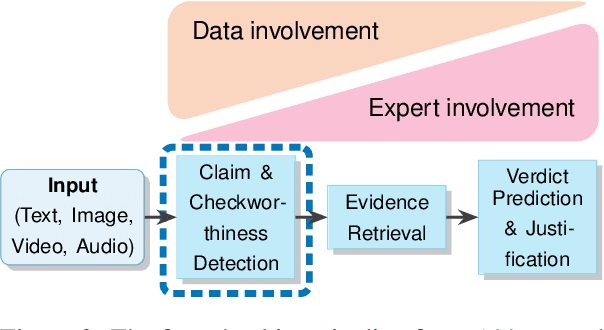
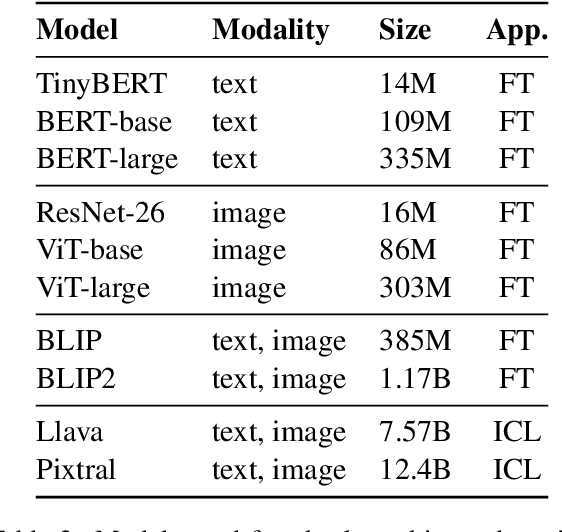
Misinformation can be countered with fact-checking, but the process is costly and slow. Identifying checkworthy claims is the first step, where automation can help scale fact-checkers' efforts. However, detection methods struggle with content that is 1) multimodal, 2) from diverse domains, and 3) synthetic. We introduce HintsOfTruth, a public dataset for multimodal checkworthiness detection with $27$K real-world and synthetic image/claim pairs. The mix of real and synthetic data makes this dataset unique and ideal for benchmarking detection methods. We compare fine-tuned and prompted Large Language Models (LLMs). We find that well-configured lightweight text-based encoders perform comparably to multimodal models but the first only focus on identifying non-claim-like content. Multimodal LLMs can be more accurate but come at a significant computational cost, making them impractical for large-scale applications. When faced with synthetic data, multimodal models perform more robustly
Facilitating Opinion Diversity through Hybrid NLP Approaches
May 15, 2024

Modern democracies face a critical issue of declining citizen participation in decision-making. Online discussion forums are an important avenue for enhancing citizen participation. This thesis proposal 1) identifies the challenges involved in facilitating large-scale online discussions with Natural Language Processing (NLP), 2) suggests solutions to these challenges by incorporating hybrid human-AI technologies, and 3) investigates what these technologies can reveal about individual perspectives in online discussions. We propose a three-layered hierarchy for representing perspectives that can be obtained by a mixture of human intelligence and large language models. We illustrate how these representations can draw insights into the diversity of perspectives and allow us to investigate interactions in online discussions.
Annotator-Centric Active Learning for Subjective NLP Tasks
Apr 24, 2024



To accurately capture the variability in human judgments for subjective NLP tasks, incorporating a wide range of perspectives in the annotation process is crucial. Active Learning (AL) addresses the high costs of collecting human annotations by strategically annotating the most informative samples. We introduce Annotator-Centric Active Learning (ACAL), which incorporates an annotator selection strategy following data sampling. Our objective is two-fold: (1) to efficiently approximate the full diversity of human judgments, and to assess model performance using annotator-centric metrics, which emphasize minority perspectives over a majority. We experiment with multiple annotator selection strategies across seven subjective NLP tasks, employing both traditional and novel, human-centered evaluation metrics. Our findings indicate that ACAL improves data efficiency and excels in annotator-centric performance evaluations. However, its success depends on the availability of a sufficiently large and diverse pool of annotators to sample from.
A Hybrid Intelligence Method for Argument Mining
Mar 11, 2024



Large-scale survey tools enable the collection of citizen feedback in opinion corpora. Extracting the key arguments from a large and noisy set of opinions helps in understanding the opinions quickly and accurately. Fully automated methods can extract arguments but (1) require large labeled datasets that induce large annotation costs and (2) work well for known viewpoints, but not for novel points of view. We propose HyEnA, a hybrid (human + AI) method for extracting arguments from opinionated texts, combining the speed of automated processing with the understanding and reasoning capabilities of humans. We evaluate HyEnA on three citizen feedback corpora. We find that, on the one hand, HyEnA achieves higher coverage and precision than a state-of-the-art automated method when compared to a common set of diverse opinions, justifying the need for human insight. On the other hand, HyEnA requires less human effort and does not compromise quality compared to (fully manual) expert analysis, demonstrating the benefit of combining human and artificial intelligence.
An Empirical Analysis of Diversity in Argument Summarization
Feb 14, 2024Presenting high-level arguments is a crucial task for fostering participation in online societal discussions. Current argument summarization approaches miss an important facet of this task -- capturing diversity -- which is important for accommodating multiple perspectives. We introduce three aspects of diversity: those of opinions, annotators, and sources. We evaluate approaches to a popular argument summarization task called Key Point Analysis, which shows how these approaches struggle to (1) represent arguments shared by few people, (2) deal with data from various sources, and (3) align with subjectivity in human-provided annotations. We find that both general-purpose LLMs and dedicated KPA models exhibit this behavior, but have complementary strengths. Further, we observe that diversification of training data may ameliorate generalization. Addressing diversity in argument summarization requires a mix of strategies to deal with subjectivity.
EduGym: An Environment Suite for Reinforcement Learning Education
Nov 17, 2023


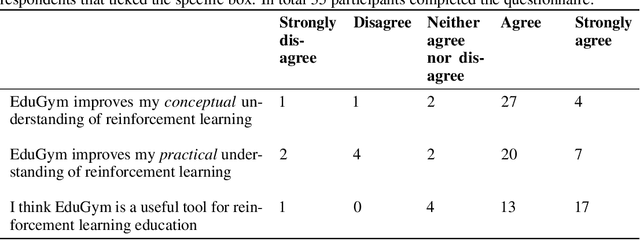
Due to the empirical success of reinforcement learning, an increasing number of students study the subject. However, from our practical teaching experience, we see students entering the field (bachelor, master and early PhD) often struggle. On the one hand, textbooks and (online) lectures provide the fundamentals, but students find it hard to translate between equations and code. On the other hand, public codebases do provide practical examples, but the implemented algorithms tend to be complex, and the underlying test environments contain multiple reinforcement learning challenges at once. Although this is realistic from a research perspective, it often hinders educational conceptual understanding. To solve this issue we introduce EduGym, a set of educational reinforcement learning environments and associated interactive notebooks tailored for education. Each EduGym environment is specifically designed to illustrate a certain aspect/challenge of reinforcement learning (e.g., exploration, partial observability, stochasticity, etc.), while the associated interactive notebook explains the challenge and its possible solution approaches, connecting equations and code in a single document. An evaluation among RL students and researchers shows 86% of them think EduGym is a useful tool for reinforcement learning education. All notebooks are available from https://sites.google.com/view/edu-gym/home, while the full software package can be installed from https://github.com/RLG-Leiden/edugym.
Do Differences in Values Influence Disagreements in Online Discussions?
Oct 24, 2023Disagreements are common in online discussions. Disagreement may foster collaboration and improve the quality of a discussion under some conditions. Although there exist methods for recognizing disagreement, a deeper understanding of factors that influence disagreement is lacking in the literature. We investigate a hypothesis that differences in personal values are indicative of disagreement in online discussions. We show how state-of-the-art models can be used for estimating values in online discussions and how the estimated values can be aggregated into value profiles. We evaluate the estimated value profiles based on human-annotated agreement labels. We find that the dissimilarity of value profiles correlates with disagreement in specific cases. We also find that including value information in agreement prediction improves performance.
Leveraging Few-Shot Data Augmentation and Waterfall Prompting for Response Generation
Aug 02, 2023



This paper discusses our approaches for task-oriented conversational modelling using subjective knowledge, with a particular emphasis on response generation. Our methodology was shaped by an extensive data analysis that evaluated key factors such as response length, sentiment, and dialogue acts present in the provided dataset. We used few-shot learning to augment the data with newly generated subjective knowledge items and present three approaches for DSTC11: (1) task-specific model exploration, (2) incorporation of the most frequent question into all generated responses, and (3) a waterfall prompting technique using a combination of both GPT-3 and ChatGPT.