 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting triples from dialogues for conversational social agents
Dec 24, 2024Obtaining an explicit understanding of communication within a Hybrid Intelligence collaboration is essential to create controllable and transparent agents. In this paper, we describe a number of Natural Language Understanding models that extract explicit symbolic triples from social conversation. Triple extraction has mostly been developed and tested for Knowledge Base Completion using Wikipedia text and data for training and testing. However, social conversation is very different as a genre in which interlocutors exchange information in sequences of utterances that involve statements, questions, and answers. Phenomena such as co-reference, ellipsis, coordination, and implicit and explicit negation or confirmation are more prominent in conversation than in Wikipedia text. We therefore describe an attempt to fill this gap by releasing data sets for training and testing triple extraction from social conversation. We also created five triple extraction models and tested them in our evaluation data. The highest precision is 51.14 for complete triples and 69.32 for triple elements when tested on single utterances. However, scores for conversational triples that span multiple turns are much lower, showing that extracting knowledge from true conversational data is much more challenging.
Leveraging Few-Shot Data Augmentation and Waterfall Prompting for Response Generation
Aug 02, 2023



This paper discusses our approaches for task-oriented conversational modelling using subjective knowledge, with a particular emphasis on response generation. Our methodology was shaped by an extensive data analysis that evaluated key factors such as response length, sentiment, and dialogue acts present in the provided dataset. We used few-shot learning to augment the data with newly generated subjective knowledge items and present three approaches for DSTC11: (1) task-specific model exploration, (2) incorporation of the most frequent question into all generated responses, and (3) a waterfall prompting technique using a combination of both GPT-3 and ChatGPT.
Will It Blend? Mixing Training Paradigms & Prompting for Argument Quality Prediction
Oct 05, 2022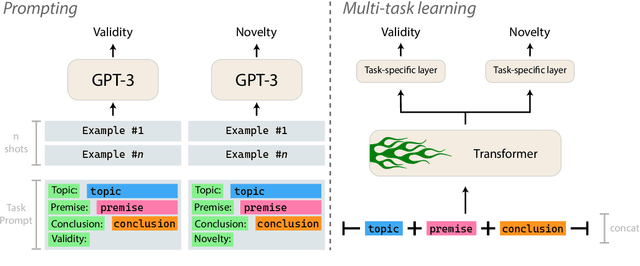

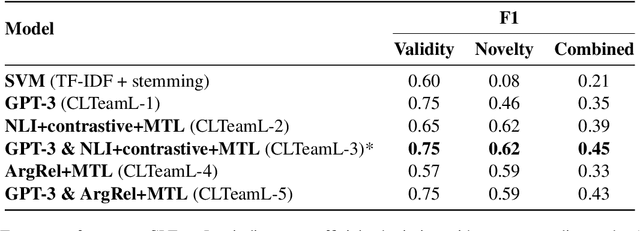
This paper describes our contributions to the Shared Task of the 9th Workshop on Argument Mining (2022). Our approach uses Large Language Models for the task of Argument Quality Prediction. We perform prompt engineering using GPT-3, and also investigate the training paradigms multi-task learning, contrastive learning, and intermediate-task training. We find that a mixed prediction setup outperforms single models. Prompting GPT-3 works best for predicting argument validity, and argument novelty is best estimated by a model trained using all three training paradigms.
Evaluating Agent Interactions Through Episodic Knowledge Graphs
Sep 26, 2022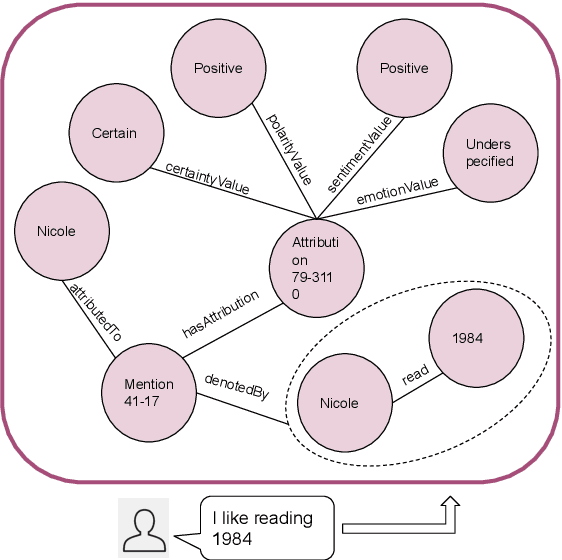



We present a new method based on episodic Knowledge Graphs (eKGs) for evaluating (multimodal) conversational agents in open domains. This graph is generated by interpreting raw signals during conversation and is able to capture the accumulation of knowledge over time. We apply structural and semantic analysis of the resulting graphs and translate the properties into qualitative measures. We compare these measures with existing automatic and manual evaluation metrics commonly used for conversational agents. Our results show that our Knowledge-Graph-based evaluation provides more qualitative insights into interaction and the agent's behavior.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022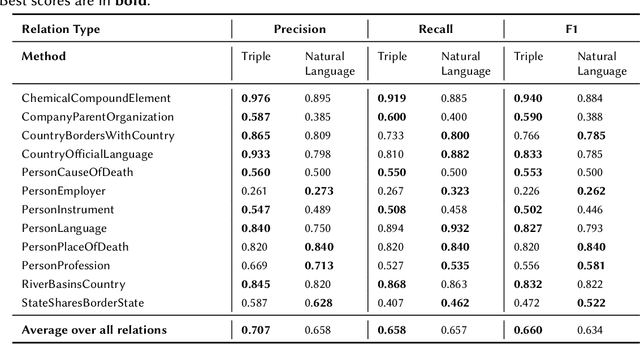
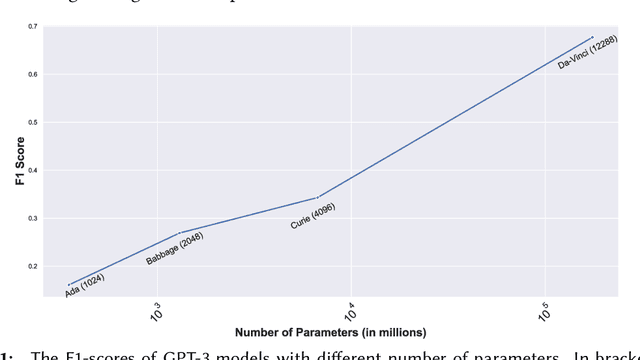
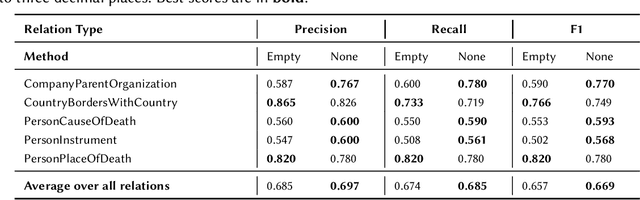
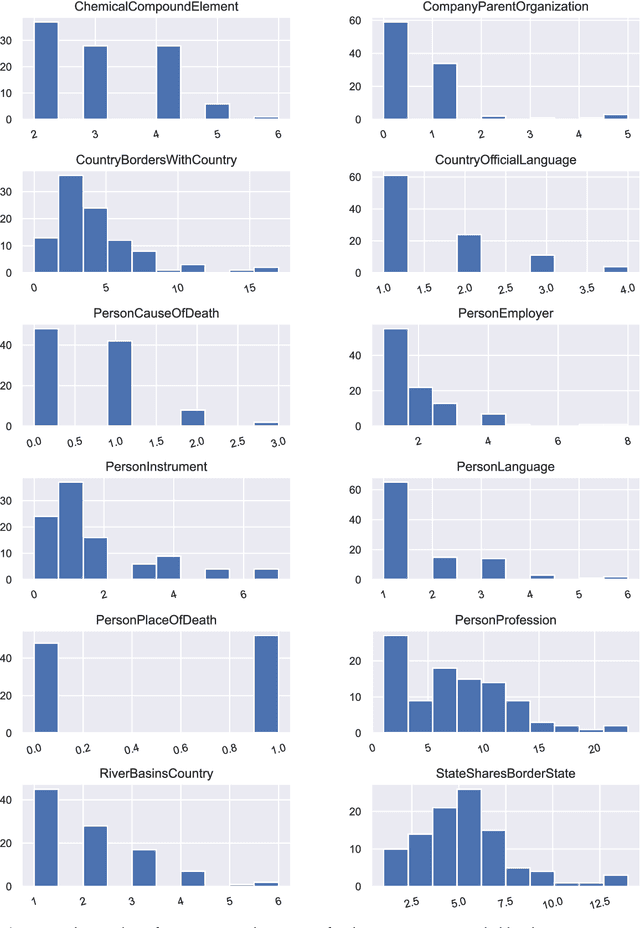
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.