 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Answering of Graph Queries
Aug 12, 2023Knowledge graphs (KGs) are inherently incomplete because of incomplete world knowledge and bias in what is the input to the KG. Additionally, world knowledge constantly expands and evolves, making existing facts deprecated or introducing new ones. However, we would still want to be able to answer queries as if the graph were complete. In this chapter, we will give an overview of several methods which have been proposed to answer queries in such a setting. We will first provide an overview of the different query types which can be supported by these methods and datasets typically used for evaluation, as well as an insight into their limitations. Then, we give an overview of the different approaches and describe them in terms of expressiveness, supported graph types, and inference capabilities.
BioBLP: A Modular Framework for Learning on Multimodal Biomedical Knowledge Graphs
Jun 06, 2023Knowledge graphs (KGs) are an important tool for representing complex relationships between entities in the biomedical domain. Several methods have been proposed for learning embeddings that can be used to predict new links in such graphs. Some methods ignore valuable attribute data associated with entities in biomedical KGs, such as protein sequences, or molecular graphs. Other works incorporate such data, but assume that entities can be represented with the same data modality. This is not always the case for biomedical KGs, where entities exhibit heterogeneous modalities that are central to their representation in the subject domain. We propose a modular framework for learning embeddings in KGs with entity attributes, that allows encoding attribute data of different modalities while also supporting entities with missing attributes. We additionally propose an efficient pretraining strategy for reducing the required training runtime. We train models using a biomedical KG containing approximately 2 million triples, and evaluate the performance of the resulting entity embeddings on the tasks of link prediction, and drug-protein interaction prediction, comparing against methods that do not take attribute data into account. In the standard link prediction evaluation, the proposed method results in competitive, yet lower performance than baselines that do not use attribute data. When evaluated in the task of drug-protein interaction prediction, the method compares favorably with the baselines. We find settings involving low degree entities, which make up for a substantial amount of the set of entities in the KG, where our method outperforms the baselines. Our proposed pretraining strategy yields significantly higher performance while reducing the required training runtime. Our implementation is available at https://github.com/elsevier-AI-Lab/BioBLP .
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022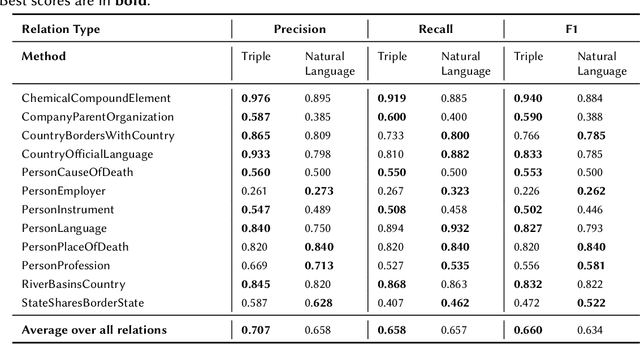
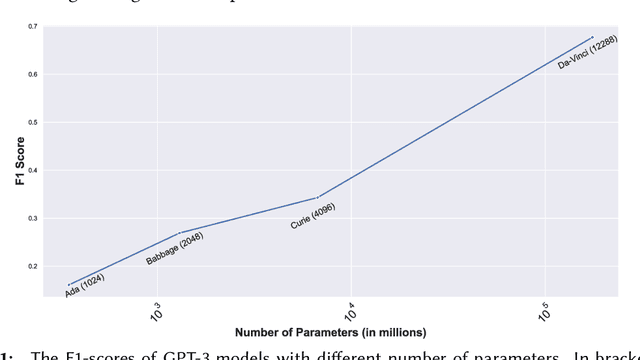
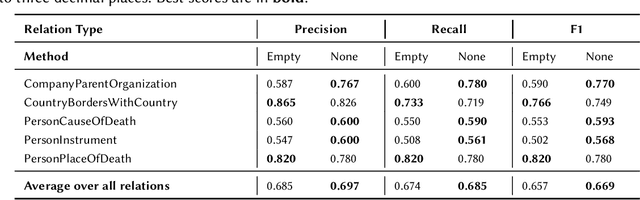
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
Query Embedding on Hyper-relational Knowledge Graphs
Jun 17, 2021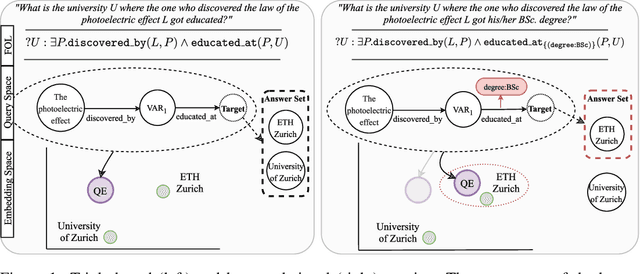
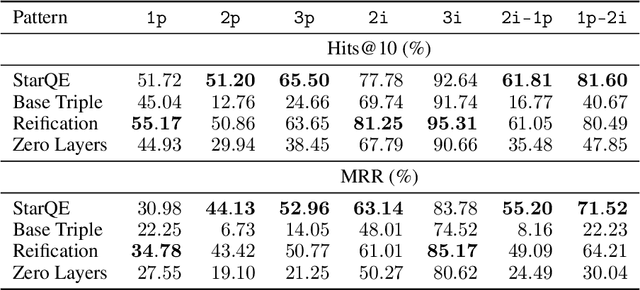

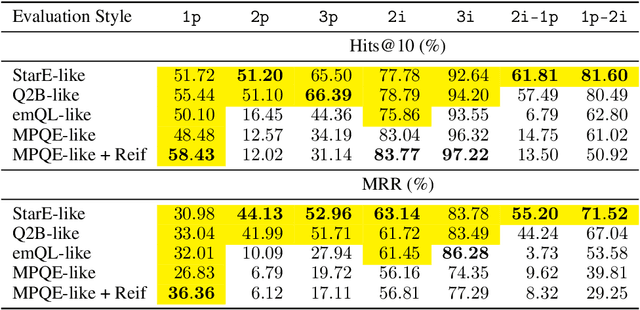
Multi-hop logical reasoning is an established problem in the field of representation learning on knowledge graphs (KGs). It subsumes both one-hop link prediction as well as other more complex types of logical queries. Existing algorithms operate only on classical, triple-based graphs, whereas modern KGs often employ a hyper-relational modeling paradigm. In this paradigm, typed edges may have several key-value pairs known as qualifiers that provide fine-grained context for facts. In queries, this context modifies the meaning of relations, and usually reduces the answer set. Hyper-relational queries are often observed in real-world KG applications, and existing approaches for approximate query answering cannot make use of qualifier pairs. In this work, we bridge this gap and extend the multi-hop reasoning problem to hyper-relational KGs allowing to tackle this new type of complex queries. Building upon recent advancements in Graph Neural Networks and query embedding techniques, we study how to embed and answer hyper-relational conjunctive queries. Besides that, we propose a method to answer such queries and demonstrate in our experiments that qualifiers improve query answering on a diverse set of query patterns.
Approximate Knowledge Graph Query Answering: From Ranking to Binary Classification
Feb 22, 2021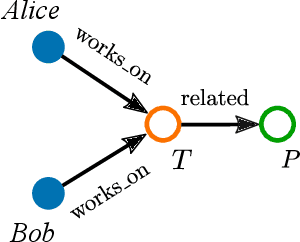
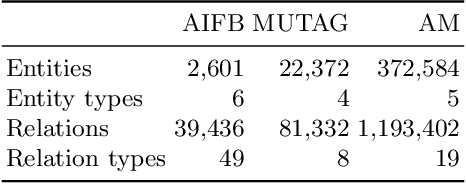
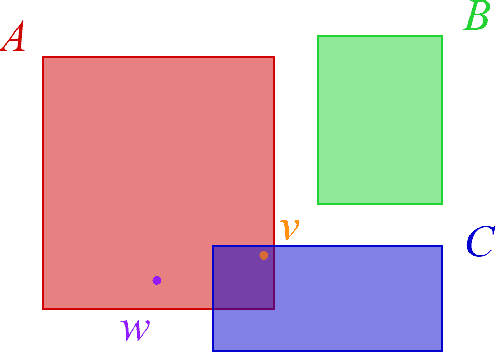
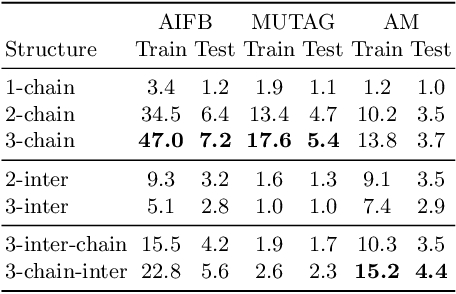
Large, heterogeneous datasets are characterized by missing or even erroneous information. This is more evident when they are the product of community effort or automatic fact extraction methods from external sources, such as text. A special case of the aforementioned phenomenon can be seen in knowledge graphs, where this mostly appears in the form of missing or incorrect edges and nodes. Structured querying on such incomplete graphs will result in incomplete sets of answers, even if the correct entities exist in the graph, since one or more edges needed to match the pattern are missing. To overcome this problem, several algorithms for approximate structured query answering have been proposed. Inspired by modern Information Retrieval metrics, these algorithms produce a ranking of all entities in the graph, and their performance is further evaluated based on how high in this ranking the correct answers appear. In this work we take a critical look at this way of evaluation. We argue that performing a ranking-based evaluation is not sufficient to assess methods for complex query answering. To solve this, we introduce Message Passing Query Boxes (MPQB), which takes binary classification metrics back into use and shows the effect this has on the recently proposed query embedding method MPQE.