 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYPER: A Foundation Model for Inductive Link Prediction with Knowledge Hypergraphs
Jun 14, 2025Inductive link prediction with knowledge hypergraphs is the task of predicting missing hyperedges involving completely novel entities (i.e., nodes unseen during training). Existing methods for inductive link prediction with knowledge hypergraphs assume a fixed relational vocabulary and, as a result, cannot generalize to knowledge hypergraphs with novel relation types (i.e., relations unseen during training). Inspired by knowledge graph foundation models, we propose HYPER as a foundation model for link prediction, which can generalize to any knowledge hypergraph, including novel entities and novel relations. Importantly, HYPER can learn and transfer across different relation types of varying arities, by encoding the entities of each hyperedge along with their respective positions in the hyperedge. To evaluate HYPER, we construct 16 new inductive datasets from existing knowledge hypergraphs, covering a diverse range of relation types of varying arities. Empirically, HYPER consistently outperforms all existing methods in both node-only and node-and-relation inductive settings, showing strong generalization to unseen, higher-arity relational structures.
Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models
Mar 28, 2025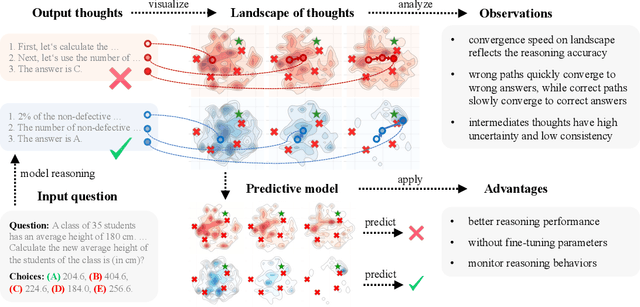
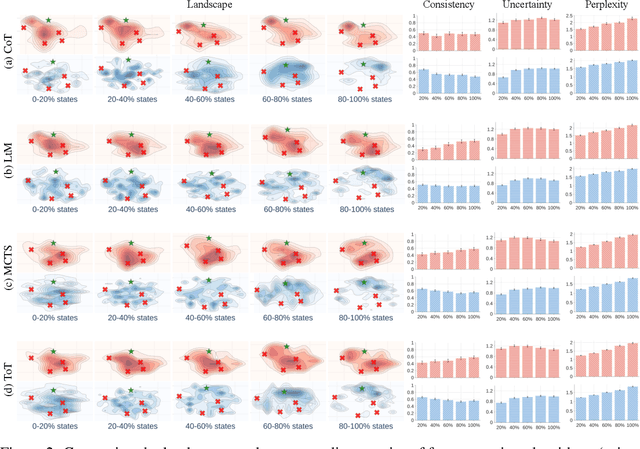
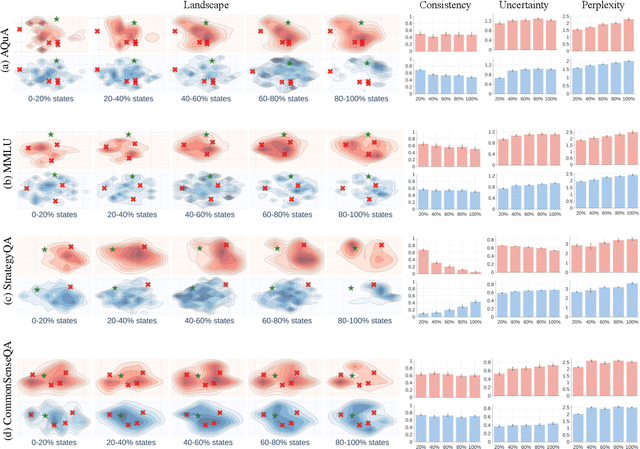
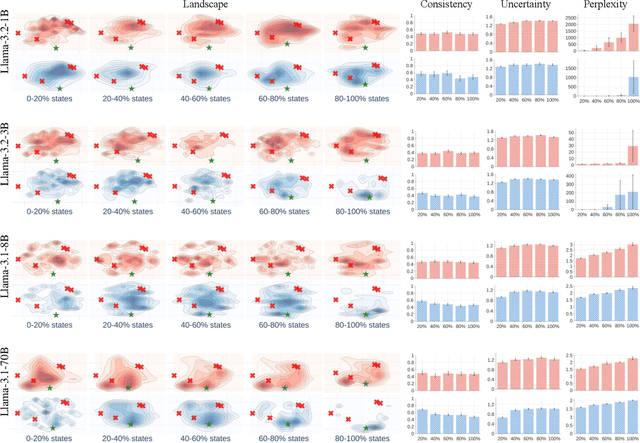
Numerous applications of large language models (LLMs) rely on their ability to perform step-by-step reasoning. However, the reasoning behavior of LLMs remains poorly understood, posing challenges to research, development, and safety. To address this gap, we introduce landscape of thoughts-the first visualization tool for users to inspect the reasoning paths of chain-of-thought and its derivatives on any multi-choice dataset. Specifically, we represent the states in a reasoning path as feature vectors that quantify their distances to all answer choices. These features are then visualized in two-dimensional plots using t-SNE. Qualitative and quantitative analysis with the landscape of thoughts effectively distinguishes between strong and weak models, correct and incorrect answers, as well as different reasoning tasks. It also uncovers undesirable reasoning patterns, such as low consistency and high uncertainty. Additionally, users can adapt our tool to a model that predicts the property they observe. We showcase this advantage by adapting our tool to a lightweight verifier that evaluates the correctness of reasoning paths. The code is publicly available at: https://github.com/tmlr-group/landscape-of-thoughts.
TRIX: A More Expressive Model for Zero-shot Domain Transfer in Knowledge Graphs
Feb 26, 2025Fully inductive knowledge graph models can be trained on multiple domains and subsequently perform zero-shot knowledge graph completion (KGC) in new unseen domains. This is an important capability towards the goal of having foundation models for knowledge graphs. In this work, we introduce a more expressive and capable fully inductive model, dubbed TRIX, which not only yields strictly more expressive triplet embeddings (head entity, relation, tail entity) compared to state-of-the-art methods, but also introduces a new capability: directly handling both entity and relation prediction tasks in inductive settings. Empirically, we show that TRIX outperforms the state-of-the-art fully inductive models in zero-shot entity and relation predictions in new domains, and outperforms large-context LLMs in out-of-domain predictions. The source code is available at https://github.com/yuchengz99/TRIX.
Position: Graph Learning Will Lose Relevance Due To Poor Benchmarks
Feb 20, 2025
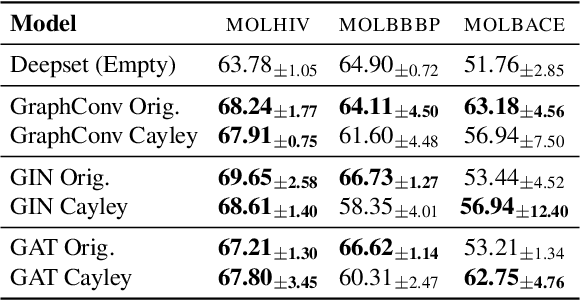
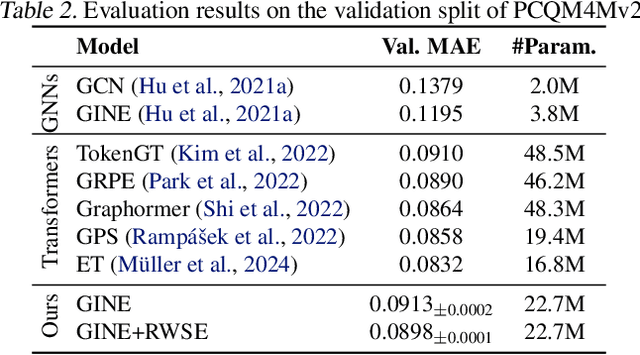
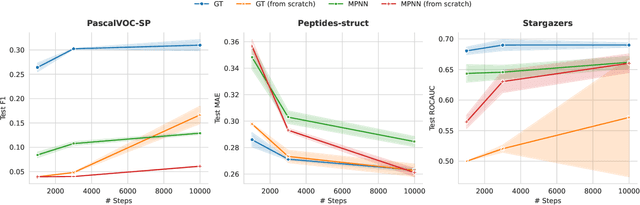
While machine learning on graphs has demonstrated promise in drug design and molecular property prediction, significant benchmarking challenges hinder its further progress and relevance. Current benchmarking practices often lack focus on transformative, real-world applications, favoring narrow domains like two-dimensional molecular graphs over broader, impactful areas such as combinatorial optimization, relational databases, or chip design. Additionally, many benchmark datasets poorly represent the underlying data, leading to inadequate abstractions and misaligned use cases. Fragmented evaluations and an excessive focus on accuracy further exacerbate these issues, incentivizing overfitting rather than fostering generalizable insights. These limitations have prevented the development of truly useful graph foundation models. This position paper calls for a paradigm shift toward more meaningful benchmarks, rigorous evaluation protocols, and stronger collaboration with domain experts to drive impactful and reliable advances in graph learning research, unlocking the potential of graph learning.
How Expressive are Knowledge Graph Foundation Models?
Feb 18, 2025Knowledge Graph Foundation Models (KGFMs) are at the frontier for deep learning on knowledge graphs (KGs), as they can generalize to completely novel knowledge graphs with different relational vocabularies. Despite their empirical success, our theoretical understanding of KGFMs remains very limited. In this paper, we conduct a rigorous study of the expressive power of KGFMs. Specifically, we show that the expressive power of KGFMs directly depends on the motifs that are used to learn the relation representations. We then observe that the most typical motifs used in the existing literature are binary, as the representations are learned based on how pairs of relations interact, which limits the model's expressiveness. As part of our study, we design more expressive KGFMs using richer motifs, which necessitate learning relation representations based on, e.g., how triples of relations interact with each other. Finally, we empirically validate our theoretical findings, showing that the use of richer motifs results in better performance on a wide range of datasets drawn from different domains.
SymmCD: Symmetry-Preserving Crystal Generation with Diffusion Models
Feb 05, 2025Generating novel crystalline materials has potential to lead to advancements in fields such as electronics, energy storage, and catalysis. The defining characteristic of crystals is their symmetry, which plays a central role in determining their physical properties. However, existing crystal generation methods either fail to generate materials that display the symmetries of real-world crystals, or simply replicate the symmetry information from examples in a database. To address this limitation, we propose SymmCD, a novel diffusion-based generative model that explicitly incorporates crystallographic symmetry into the generative process. We decompose crystals into two components and learn their joint distribution through diffusion: 1) the asymmetric unit, the smallest subset of the crystal which can generate the whole crystal through symmetry transformations, and; 2) the symmetry transformations needed to be applied to each atom in the asymmetric unit. We also use a novel and interpretable representation for these transformations, enabling generalization across different crystallographic symmetry groups. We showcase the competitive performance of SymmCD on a subset of the Materials Project, obtaining diverse and valid crystals with realistic symmetries and predicted properties.
Deconstructing equivariant representations in molecular systems
Oct 10, 2024Recent equivariant models have shown significant progress in not just chemical property prediction, but as surrogates for dynamical simulations of molecules and materials. Many of the top performing models in this category are built within the framework of tensor products, which preserves equivariance by restricting interactions and transformations to those that are allowed by symmetry selection rules. Despite being a core part of the modeling process, there has not yet been much attention into understanding what information persists in these equivariant representations, and their general behavior outside of benchmark metrics. In this work, we report on a set of experiments using a simple equivariant graph convolution model on the QM9 dataset, focusing on correlating quantitative performance with the resulting molecular graph embeddings. Our key finding is that, for a scalar prediction task, many of the irreducible representations are simply ignored during training -- specifically those pertaining to vector ($l=1$) and tensor quantities ($l=2$) -- an issue that does not necessarily make itself evident in the test metric. We empirically show that removing some unused orders of spherical harmonics improves model performance, correlating with improved latent space structure. We provide a number of recommendations for future experiments to try and improve efficiency and utilization of equivariant features based on these observations.
One Model, Any Conjunctive Query: Graph Neural Networks for Answering Complex Queries over Knowledge Graphs
Sep 21, 2024



Traditional query answering over knowledge graphs -- or broadly over relational data -- is one of the most fundamental problems in data management. Motivated by the incompleteness of modern knowledge graphs, a new setup for query answering has emerged, where the goal is to predict answers that do not necessarily appear in the knowledge graph, but are present in its completion. In this work, we propose AnyCQ, a graph neural network model that can classify answers to any conjunctive query on any knowledge graph, following training. At the core of our framework lies a graph neural network model trained using a reinforcement learning objective to answer Boolean queries. Our approach and problem setup differ from existing query answering studies in multiple dimensions. First, we focus on the problem of query answer classification: given a query and a set of possible answers, classify these proposals as true or false relative to the complete knowledge graph. Second, we study the problem of query answer retrieval: given a query, retrieve an answer to the query relative to the complete knowledge graph or decide that no correct solutions exist. Trained on simple, small instances, AnyCQ can generalize to large queries of arbitrary structure, reliably classifying and retrieving answers to samples where existing approaches fail, which is empirically validated on new and challenging benchmarks. Furthermore, we demonstrate that our AnyCQ models effectively transfer to out-of-distribution knowledge graphs, when equipped with a relevant link predictor, highlighting their potential to serve as a general engine for query answering.
TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
Jun 14, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
GraphAny: A Foundation Model for Node Classification on Any Graph
Jun 03, 2024Foundation models that can perform inference on any new task without requiring specific training have revolutionized machine learning in vision and language applications. However, applications involving graph-structured data remain a tough nut for foundation models, due to challenges in the unique feature- and label spaces associated with each graph. Traditional graph ML models such as graph neural networks (GNNs) trained on graphs cannot perform inference on a new graph with feature and label spaces different from the training ones. Furthermore, existing models learn functions specific to the training graph and cannot generalize to new graphs. In this work, we tackle these two challenges with a new foundational architecture for inductive node classification named GraphAny. GraphAny models inference on a new graph as an analytical solution to a LinearGNN, thereby solving the first challenge. To solve the second challenge, we learn attention scores for each node to fuse the predictions of multiple LinearGNNs. Specifically, the attention module is carefully parameterized as a function of the entropy-normalized distance-features between multiple LinearGNNs predictions to ensure generalization to new graphs. Empirically, GraphAny trained on the Wisconsin dataset with only 120 labeled nodes can effectively generalize to 30 new graphs with an average accuracy of 67.26\% in an inductive manner, surpassing GCN and GAT trained in the supervised regime, as well as other inductive baselines.