 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausibility Is Not Prediction: Contrastive Evidence for LLM-Based Cellular Perturbation Reasoning
May 31, 2026Perturbation experiments are central to understanding cellular mechanisms, but remain costly and sparse, motivating prediction of gene expression responses for unobserved conditions. A promising recent direction leverages large language models (LLMs) as "virtual cell" simulators-using stepwise, knowledge-grounded mechanistic reasoning to infer differential expression-pointing toward an interpretable, knowledge-driven paradigm that transcends purely data-driven approaches. However, we find that plausibility is not prediction: despite producing biologically plausible explanations, these methods fail to capture perturbation-specific effects: systematically overestimating differential expression, often underperforming a simple gene-frequency baseline in aggregate evaluations, and collapsing to chance-level performance at the per-gene level. This reveals a reliance on intrinsic gene response tendencies rather than true perturbation reasoning. We trace this failure to how evidence is presented: existing methods evaluate perturbation-gene pairs in isolation, without exposing how related perturbations differ in their effects on the same gene. To address this limitation, we introduce CORE (Contrastive Organization of Relational Evidence), which reframes prediction as a comparison task by organizing evidence into positive and negative outcomes from related perturbations. Using a biomedical knowledge graph for evidence retrieval, CORE improves calibration and substantially boosts perturbation-specific prediction in both LLM-based and non-LLM settings: for example, on drug-perturbation data, CORE-Reasoning improves Qwen3.5-9B aggregate metrics by up to 28.6%, while on generic perturbation data, CORE-Voting raises macro-per-gene AUROC from chance to 0.703 in average across four cell lines. This highlights contrastive evidence organization as essential to reliable LLM-based perturbation reasoning
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.
Cell-ontology guided transcriptome foundation model
Aug 22, 2024



Transcriptome foundation models TFMs hold great promises of deciphering the transcriptomic language that dictate diverse cell functions by self-supervised learning on large-scale single-cell gene expression data, and ultimately unraveling the complex mechanisms of human diseases. However, current TFMs treat cells as independent samples and ignore the taxonomic relationships between cell types, which are available in cell ontology graphs. We argue that effectively leveraging this ontology information during the TFM pre-training can improve learning biologically meaningful gene co-expression patterns while preserving TFM as a general purpose foundation model for downstream zero-shot and fine-tuning tasks. To this end, we present \textbf{s}ingle \textbf{c}ell, \textbf{Cell}-\textbf{o}ntology guided TFM scCello. We introduce cell-type coherence loss and ontology alignment loss, which are minimized along with the masked gene expression prediction loss during the pre-training. The novel loss component guide scCello to learn the cell-type-specific representation and the structural relation between cell types from the cell ontology graph, respectively. We pre-trained scCello on 22 million cells from CellxGene database leveraging their cell-type labels mapped to the cell ontology graph from Open Biological and Biomedical Ontology Foundry. Our TFM demonstrates competitive generalization and transferability performance over the existing TFMs on biologically important tasks including identifying novel cell types of unseen cells, prediction of cell-type-specific marker genes, and cancer drug responses.
GraphAny: A Foundation Model for Node Classification on Any Graph
Jun 03, 2024Foundation models that can perform inference on any new task without requiring specific training have revolutionized machine learning in vision and language applications. However, applications involving graph-structured data remain a tough nut for foundation models, due to challenges in the unique feature- and label spaces associated with each graph. Traditional graph ML models such as graph neural networks (GNNs) trained on graphs cannot perform inference on a new graph with feature and label spaces different from the training ones. Furthermore, existing models learn functions specific to the training graph and cannot generalize to new graphs. In this work, we tackle these two challenges with a new foundational architecture for inductive node classification named GraphAny. GraphAny models inference on a new graph as an analytical solution to a LinearGNN, thereby solving the first challenge. To solve the second challenge, we learn attention scores for each node to fuse the predictions of multiple LinearGNNs. Specifically, the attention module is carefully parameterized as a function of the entropy-normalized distance-features between multiple LinearGNNs predictions to ensure generalization to new graphs. Empirically, GraphAny trained on the Wisconsin dataset with only 120 labeled nodes can effectively generalize to 30 new graphs with an average accuracy of 67.26\% in an inductive manner, surpassing GCN and GAT trained in the supervised regime, as well as other inductive baselines.
Advancing Real-time Pandemic Forecasting Using Large Language Models: A COVID-19 Case Study
Apr 10, 2024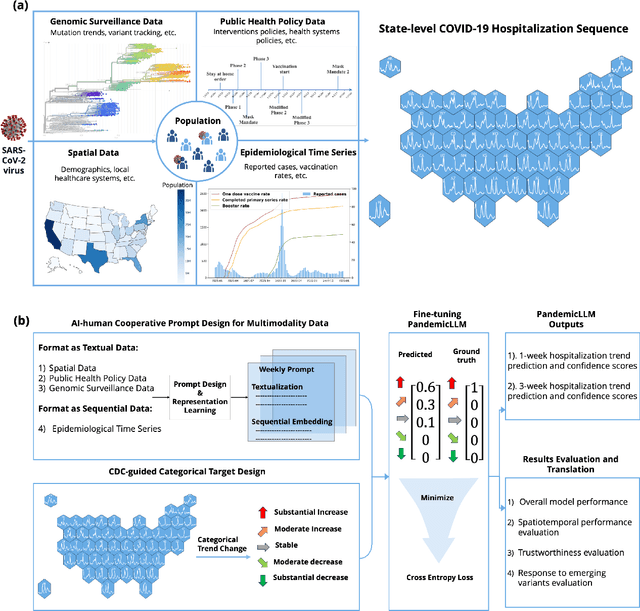
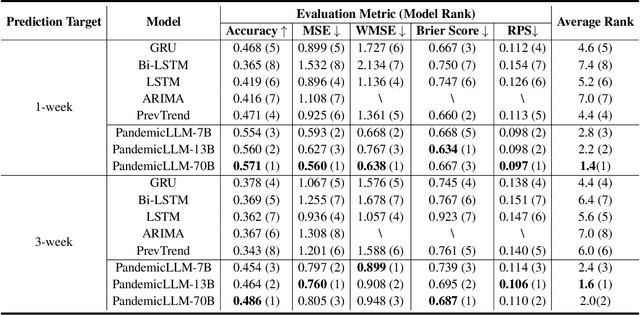

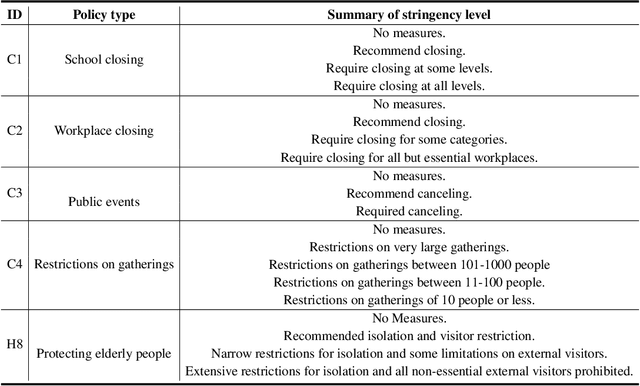
Forecasting the short-term spread of an ongoing disease outbreak is a formidable challenge due to the complexity of contributing factors, some of which can be characterized through interlinked, multi-modality variables such as epidemiological time series data, viral biology, population demographics, and the intersection of public policy and human behavior. Existing forecasting model frameworks struggle with the multifaceted nature of relevant data and robust results translation, which hinders their performances and the provision of actionable insights for public health decision-makers. Our work introduces PandemicLLM, a novel framework with multi-modal Large Language Models (LLMs) that reformulates real-time forecasting of disease spread as a text reasoning problem, with the ability to incorporate real-time, complex, non-numerical information that previously unattainable in traditional forecasting models. This approach, through a unique AI-human cooperative prompt design and time series representation learning, encodes multi-modal data for LLMs. The model is applied to the COVID-19 pandemic, and trained to utilize textual public health policies, genomic surveillance, spatial, and epidemiological time series data, and is subsequently tested across all 50 states of the U.S. Empirically, PandemicLLM is shown to be a high-performing pandemic forecasting framework that effectively captures the impact of emerging variants and can provide timely and accurate predictions. The proposed PandemicLLM opens avenues for incorporating various pandemic-related data in heterogeneous formats and exhibits performance benefits over existing models. This study illuminates the potential of adapting LLMs and representation learning to enhance pandemic forecasting, illustrating how AI innovations can strengthen pandemic responses and crisis management in the future.
Graph Foundation Models
Feb 06, 2024



Graph Foundation Model (GFM) is a new trending research topic in the graph domain, aiming to develop a graph model capable of generalizing across different graphs and tasks. However, a versatile GFM has not yet been achieved. The key challenge in building GFM is how to enable positive transfer across graphs with diverse structural patterns. Inspired by the existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a "graph vocabulary", in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, theoretical foundations, and stability. Such a vocabulary perspective can potentially advance the future GFM design following the neural scaling laws.
Knowledge-enhanced Multi-perspective Video Representation Learning for Scene Recognition
Jan 09, 2024With the explosive growth of video data in real-world applications, a comprehensive representation of videos becomes increasingly important. In this paper, we address the problem of video scene recognition, whose goal is to learn a high-level video representation to classify scenes in videos. Due to the diversity and complexity of video contents in realistic scenarios, this task remains a challenge. Most existing works identify scenes for videos only from visual or textual information in a temporal perspective, ignoring the valuable information hidden in single frames, while several earlier studies only recognize scenes for separate images in a non-temporal perspective. We argue that these two perspectives are both meaningful for this task and complementary to each other, meanwhile, externally introduced knowledge can also promote the comprehension of videos. We propose a novel two-stream framework to model video representations from multiple perspectives, i.e. temporal and non-temporal perspectives, and integrate the two perspectives in an end-to-end manner by self-distillation. Besides, we design a knowledge-enhanced feature fusion and label prediction method that contributes to naturally introducing knowledge into the task of video scene recognition. Experiments conducted on a real-world dataset demonstrate the effectiveness of our proposed method.
GraphText: Graph Reasoning in Text Space
Oct 02, 2023



Large Language Models (LLMs) have gained the ability to assimilate human knowledge and facilitate natural language interactions with both humans and other LLMs. However, despite their impressive achievements, LLMs have not made significant advancements in the realm of graph machine learning. This limitation arises because graphs encapsulate distinct relational data, making it challenging to transform them into natural language that LLMs understand. In this paper, we bridge this gap with a novel framework, GraphText, that translates graphs into natural language. GraphText derives a graph-syntax tree for each graph that encapsulates both the node attributes and inter-node relationships. Traversal of the tree yields a graph text sequence, which is then processed by an LLM to treat graph tasks as text generation tasks. Notably, GraphText offers multiple advantages. It introduces training-free graph reasoning: even without training on graph data, GraphText with ChatGPT can achieve on par with, or even surpassing, the performance of supervised-trained graph neural networks through in-context learning (ICL). Furthermore, GraphText paves the way for interactive graph reasoning, allowing both humans and LLMs to communicate with the model seamlessly using natural language. These capabilities underscore the vast, yet-to-be-explored potential of LLMs in the domain of graph machine learning.
To Copy Rather Than Memorize: A Vertical Learning Paradigm for Knowledge Graph Completion
May 23, 2023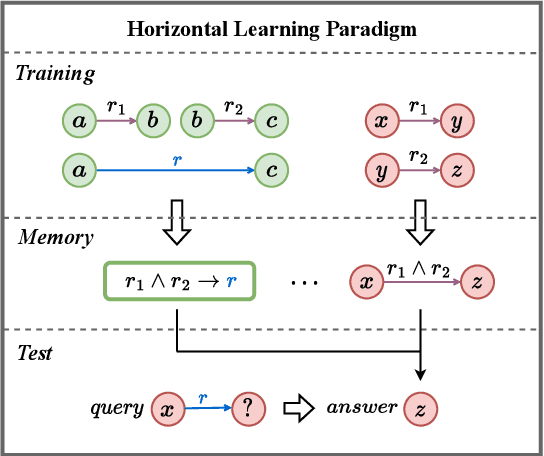

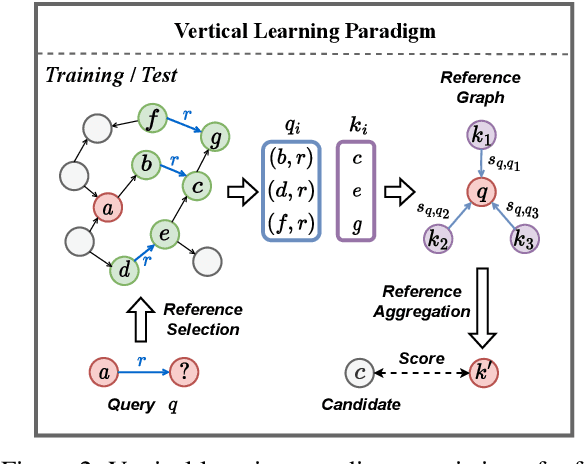
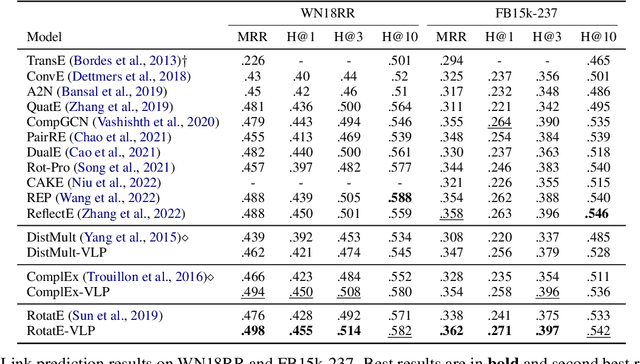
Embedding models have shown great power in knowledge graph completion (KGC) task. By learning structural constraints for each training triple, these methods implicitly memorize intrinsic relation rules to infer missing links. However, this paper points out that the multi-hop relation rules are hard to be reliably memorized due to the inherent deficiencies of such implicit memorization strategy, making embedding models underperform in predicting links between distant entity pairs. To alleviate this problem, we present Vertical Learning Paradigm (VLP), which extends embedding models by allowing to explicitly copy target information from related factual triples for more accurate prediction. Rather than solely relying on the implicit memory, VLP directly provides additional cues to improve the generalization ability of embedding models, especially making the distant link prediction significantly easier. Moreover, we also propose a novel relative distance based negative sampling technique (ReD) for more effective optimization. Experiments demonstrate the validity and generality of our proposals on two standard benchmarks. Our code is available at https://github.com/rui9812/VLP.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023

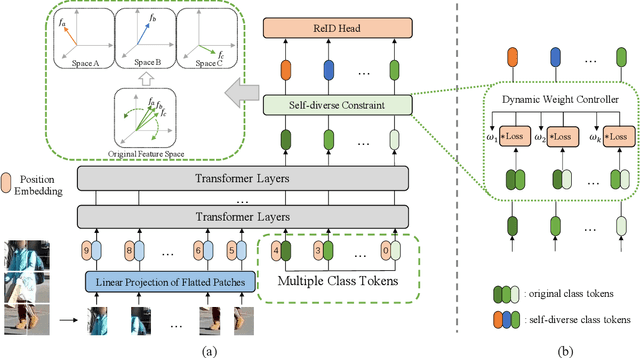

In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.