 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Reinforcement Learning for Honesty Alignment in Language Models on Deductive Reasoning
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has recently emerged as a promising framework for aligning language models with complex reasoning objectives. However, most existing methods optimize only for final task outcomes, leaving models vulnerable to collapse when negative rewards dominate early training. This challenge is especially pronounced in honesty alignment, where models must not only solve answerable queries but also identify when conclusions cannot be drawn from the given premises. Deductive reasoning provides an ideal testbed because it isolates reasoning capability from reliance on external factual knowledge. To investigate honesty alignment, we curate two multi-step deductive reasoning datasets from graph structures, one for linear algebra and one for logical inference, and introduce unanswerable cases by randomly perturbing an edge in half of the instances. We find that GRPO, with or without supervised fine tuning initialization, struggles on these tasks. Through extensive experiments across three models, we evaluate stabilization strategies and show that curriculum learning provides some benefit but requires carefully designed in distribution datasets with controllable difficulty. To address these limitations, we propose Anchor, a reinforcement learning method that injects ground truth trajectories into rollouts, preventing early training collapse. Our results demonstrate that this method stabilizes learning and significantly improves the overall reasoning performance, underscoring the importance of training dynamics for enabling reliable deductive reasoning in aligned language models.
On the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
One Model for One Graph: A New Perspective for Pretraining with Cross-domain Graphs
Nov 30, 2024



Graph Neural Networks (GNNs) have emerged as a powerful tool to capture intricate network patterns, achieving success across different domains. However, existing GNNs require careful domain-specific architecture designs and training from scratch on each dataset, leading to an expertise-intensive process with difficulty in generalizing across graphs from different domains. Therefore, it can be hard for practitioners to infer which GNN model can generalize well to graphs from their domains. To address this challenge, we propose a novel cross-domain pretraining framework, "one model for one graph," which overcomes the limitations of previous approaches that failed to use a single GNN to capture diverse graph patterns across domains with significant gaps. Specifically, we pretrain a bank of expert models, with each one corresponding to a specific dataset. When inferring to a new graph, gating functions choose a subset of experts to effectively integrate prior model knowledge while avoiding negative transfer. Extensive experiments consistently demonstrate the superiority of our proposed method on both link prediction and node classification tasks.
Do Neural Scaling Laws Exist on Graph Self-Supervised Learning?
Aug 20, 2024



Self-supervised learning~(SSL) is essential to obtain foundation models in NLP and CV domains via effectively leveraging knowledge in large-scale unlabeled data. The reason for its success is that a suitable SSL design can help the model to follow the neural scaling law, i.e., the performance consistently improves with increasing model and dataset sizes. However, it remains a mystery whether existing SSL in the graph domain can follow the scaling behavior toward building Graph Foundation Models~(GFMs) with large-scale pre-training. In this study, we examine whether existing graph SSL techniques can follow the neural scaling behavior with the potential to serve as the essential component for GFMs. Our benchmark includes comprehensive SSL technique implementations with analysis conducted on both the conventional SSL setting and many new settings adopted in other domains. Surprisingly, despite the SSL loss continuously decreasing, no existing graph SSL techniques follow the neural scaling behavior on the downstream performance. The model performance only merely fluctuates on different data scales and model scales. Instead of the scales, the key factors influencing the performance are the choices of model architecture and pretext task design. This paper examines existing SSL techniques for the feasibility of Graph SSL techniques in developing GFMs and opens a new direction for graph SSL design with the new evaluation prototype. Our code implementation is available online to ease reproducibility on https://github.com/GraphSSLScaling/GraphSSLScaling.
Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis
Jul 21, 2024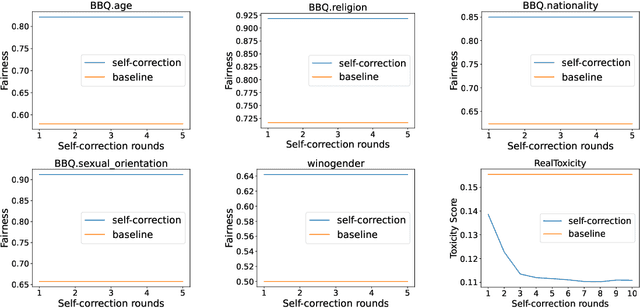

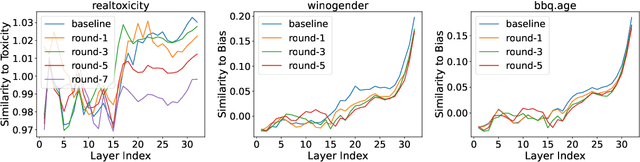

Large Language Models (LLMs) are capable of producing content that perpetuates stereotypes, discrimination, and toxicity. The recently proposed moral self-correction is a computationally efficient method for reducing harmful content in the responses of LLMs. However, the process of how injecting self-correction instructions can modify the behavior of LLMs remains under-explored. In this paper, we explore the effectiveness of moral self-correction by answering three research questions: (1) In what scenarios does moral self-correction work? (2) What are the internal mechanisms of LLMs, e.g., hidden states, that are influenced by moral self-correction instructions? (3) Is intrinsic moral self-correction actually superficial? We argue that self-correction can help LLMs find a shortcut to more morally correct output, rather than truly reducing the immorality stored in hidden states. Through empirical investigation with tasks of language generation and multi-choice question answering, we conclude: (i) LLMs exhibit good performance across both tasks, and self-correction instructions are particularly beneficial when the correct answer is already top-ranked; (ii) The morality levels in intermediate hidden states are strong indicators as to whether one instruction would be more effective than another; (iii) Based on our analysis of intermediate hidden states and task case studies of self-correction behaviors, we are first to propose the hypothesis that intrinsic moral self-correction is in fact superficial.
A Pure Transformer Pretraining Framework on Text-attributed Graphs
Jun 19, 2024



Pretraining plays a pivotal role in acquiring generalized knowledge from large-scale data, achieving remarkable successes as evidenced by large models in CV and NLP. However, progress in the graph domain remains limited due to fundamental challenges such as feature heterogeneity and structural heterogeneity. Recently, increasing efforts have been made to enhance node feature quality with Large Language Models (LLMs) on text-attributed graphs (TAGs), demonstrating superiority to traditional bag-of-words or word2vec techniques. These high-quality node features reduce the previously critical role of graph structure, resulting in a modest performance gap between Graph Neural Networks (GNNs) and structure-agnostic Multi-Layer Perceptrons (MLPs). Motivated by this, we introduce a feature-centric pretraining perspective by treating graph structure as a prior and leveraging the rich, unified feature space to learn refined interaction patterns that generalizes across graphs. Our framework, Graph Sequence Pretraining with Transformer (GSPT), samples node contexts through random walks and employs masked feature reconstruction to capture pairwise proximity in the LLM-unified feature space using a standard Transformer. By utilizing unified text representations rather than varying structures, our framework achieves significantly better transferability among graphs within the same domain. GSPT can be easily adapted to both node classification and link prediction, demonstrating promising empirical success on various datasets.
Text-space Graph Foundation Models: Comprehensive Benchmarks and New Insights
Jun 15, 2024



Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from \url{https://github.com/CurryTang/TSGFM}.
Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models
Jun 04, 2024Models for natural language and images benefit from data scaling behavior: the more data fed into the model, the better they perform. This 'better with more' phenomenon enables the effectiveness of large-scale pre-training on vast amounts of data. However, current graph pre-training methods struggle to scale up data due to heterogeneity across graphs. To achieve effective data scaling, we aim to develop a general model that is able to capture diverse data patterns of graphs and can be utilized to adaptively help the downstream tasks. To this end, we propose UniAug, a universal graph structure augmentor built on a diffusion model. We first pre-train a discrete diffusion model on thousands of graphs across domains to learn the graph structural patterns. In the downstream phase, we provide adaptive enhancement by conducting graph structure augmentation with the help of the pre-trained diffusion model via guided generation. By leveraging the pre-trained diffusion model for structure augmentation, we consistently achieve performance improvements across various downstream tasks in a plug-and-play manner. To the best of our knowledge, this study represents the first demonstration of a data-scaling graph structure augmentor on graphs across domains.
PDHG-Unrolled Learning-to-Optimize Method for Large-Scale Linear Programming
Jun 04, 2024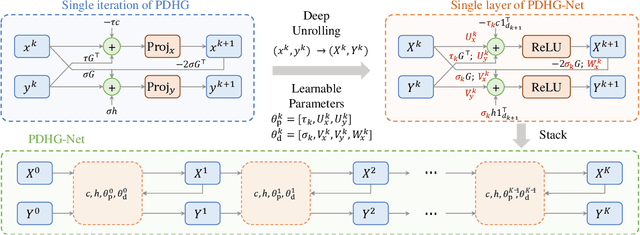
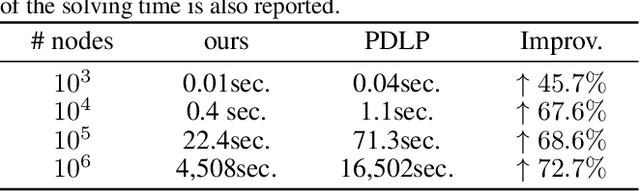
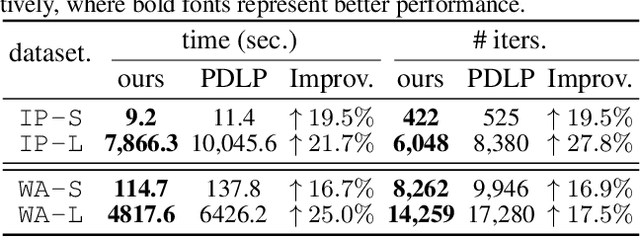
Solving large-scale linear programming (LP) problems is an important task in various areas such as communication networks, power systems, finance and logistics. Recently, two distinct approaches have emerged to expedite LP solving: (i) First-order methods (FOMs); (ii) Learning to optimize (L2O). In this work, we propose an FOM-unrolled neural network (NN) called PDHG-Net, and propose a two-stage L2O method to solve large-scale LP problems. The new architecture PDHG-Net is designed by unrolling the recently emerged PDHG method into a neural network, combined with channel-expansion techniques borrowed from graph neural networks. We prove that the proposed PDHG-Net can recover PDHG algorithm, thus can approximate optimal solutions of LP instances with a polynomial number of neurons. We propose a two-stage inference approach: first use PDHG-Net to generate an approximate solution, and then apply PDHG algorithm to further improve the solution. Experiments show that our approach can significantly accelerate LP solving, achieving up to a 3$\times$ speedup compared to FOMs for large-scale LP problems.
On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Jun 04, 2024Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.