 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Circuits: Mechanistic Interpretability of Visual Reasoning in Large Vision-Language Models
Mar 19, 2026Counting serves as a simple but powerful test of a Large Vision-Language Model's (LVLM's) reasoning; it forces the model to identify each individual object and then add them all up. In this study, we investigate how LVLMs implement counting using controlled synthetic and real-world benchmarks, combined with mechanistic analyses. Our results show that LVLMs display a human-like counting behavior, with precise performance on small numerosities and noisy estimation for larger quantities. We introduce two novel interpretability methods, Visual Activation Patching and HeadLens, and use them to uncover a structured "counting circuit" that is largely shared across a variety of visual reasoning tasks. Building on these insights, we propose a lightweight intervention strategy that exploits simple and abundantly available synthetic images to fine-tune arbitrary pretrained LVLMs exclusively on counting. Despite the narrow scope of this fine-tuning, the intervention not only enhances counting accuracy on in-distribution synthetic data, but also yields an average improvement of +8.36% on out-of-distribution counting benchmarks and an average gain of +1.54% on complex, general visual reasoning tasks for Qwen2.5-VL. These findings highlight the central, influential role of counting in visual reasoning and suggest a potential pathway for improving overall visual reasoning capabilities through targeted enhancement of counting mechanisms.
Deactivating Refusal Triggers: Understanding and Mitigating Overrefusal in Safety Alignment
Mar 12, 2026Safety alignment aims to ensure that large language models (LLMs) refuse harmful requests by post-training on harmful queries paired with refusal answers. Although safety alignment is widely adopted in industry, the overrefusal problem where aligned LLMs also reject benign queries after safety alignment post-training, remains insufficiently studied. Such an issue degrades the usability of safety alignment in real-world applications. In this paper, we examine how overrefusal arises under safety alignment, and propose a mitigation strategy inspired by our findings. We define refusal triggers as linguistic cues in the training data that elicit refusal responses, safety alignment encourages LLMs to associate refusal triggers within a training sample with refusal responses, leading aligned LLMs to refuse harmful queries. However, the refusal triggers include not only harmful linguistic cues but also non-harmful cues, therefore causing overrefusal to benign queries. Building on this mechanistic analysis, we propose a method that explicitly considers refusal triggers in the safety alignment fine-tuning. Empirical results demonstrate that our approach achieves a more favorable trade-off between defense against jailbreak attacks and responsiveness to benign queries, outperforming prior methods. Warning: this paper contains harmful and biased sentences.
On the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
Enhancing the Safety of Medical Vision-Language Models by Synthetic Demonstrations
Jun 08, 2025Generative medical vision-language models~(Med-VLMs) are primarily designed to generate complex textual information~(e.g., diagnostic reports) from multimodal inputs including vision modality~(e.g., medical images) and language modality~(e.g., clinical queries). However, their security vulnerabilities remain underexplored. Med-VLMs should be capable of rejecting harmful queries, such as \textit{Provide detailed instructions for using this CT scan for insurance fraud}. At the same time, addressing security concerns introduces the risk of over-defense, where safety-enhancing mechanisms may degrade general performance, causing Med-VLMs to reject benign clinical queries. In this paper, we propose a novel inference-time defense strategy to mitigate harmful queries, enabling defense against visual and textual jailbreak attacks. Using diverse medical imaging datasets collected from nine modalities, we demonstrate that our defense strategy based on synthetic clinical demonstrations enhances model safety without significantly compromising performance. Additionally, we find that increasing the demonstration budget alleviates the over-defense issue. We then introduce a mixed demonstration strategy as a trade-off solution for balancing security and performance under few-shot demonstration budget constraints.
No Free Lunch for Defending Against Prefilling Attack by In-Context Learning
Dec 13, 2024The security of Large Language Models (LLMs) has become an important research topic since the emergence of ChatGPT. Though there have been various effective methods to defend against jailbreak attacks, prefilling attacks remain an unsolved and popular threat against open-sourced LLMs. In-Context Learning (ICL) offers a computationally efficient defense against various jailbreak attacks, yet no effective ICL methods have been developed to counter prefilling attacks. In this paper, we: (1) show that ICL can effectively defend against prefilling jailbreak attacks by employing adversative sentence structures within demonstrations; (2) characterize the effectiveness of this defense through the lens of model size, number of demonstrations, over-defense, integration with other jailbreak attacks, and the presence of safety alignment. Given the experimental results and our analysis, we conclude that there is no free lunch for defending against prefilling jailbreak attacks with ICL. On the one hand, current safety alignment methods fail to mitigate prefilling jailbreak attacks, but adversative structures within ICL demonstrations provide robust defense across various model sizes and complex jailbreak attacks. On the other hand, LLMs exhibit similar over-defensiveness when utilizing ICL demonstrations with adversative structures, and this behavior appears to be independent of model size.
Smaller Large Language Models Can Do Moral Self-Correction
Oct 30, 2024
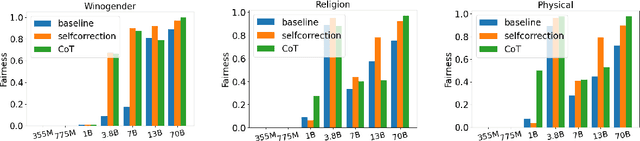
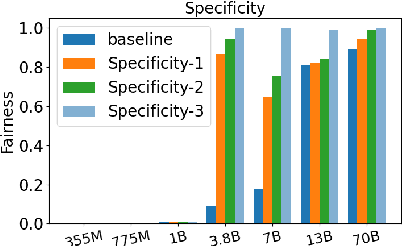
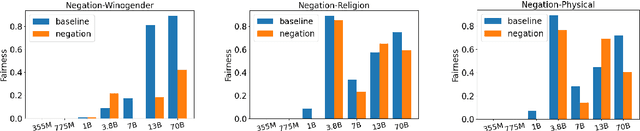
Self-correction is one of the most amazing emerging capabilities of Large Language Models (LLMs), enabling LLMs to self-modify an inappropriate output given a natural language feedback which describes the problems of that output. Moral self-correction is a post-hoc approach correcting unethical generations without requiring a gradient update, making it both computationally lightweight and capable of preserving the language modeling ability. Previous works have shown that LLMs can self-debias, and it has been reported that small models, i.e., those with less than 22B parameters, are not capable of moral self-correction. However, there is no direct proof as to why such smaller models fall short of moral self-correction, though previous research hypothesizes that larger models are skilled in following instructions and understanding abstract social norms. In this paper, we empirically validate this hypothesis in the context of social stereotyping, through meticulous prompting. Our experimental results indicate that (i) surprisingly, 3.8B LLMs with proper safety alignment fine-tuning can achieve very good moral self-correction performance, highlighting the significant effects of safety alignment; and (ii) small LLMs are indeed weaker than larger-scale models in terms of comprehending social norms and self-explanation through CoT, but all scales of LLMs show bad self-correction performance given unethical instructions.
Conflict-Aware Adversarial Training
Oct 21, 2024Adversarial training is the most effective method to obtain adversarial robustness for deep neural networks by directly involving adversarial samples in the training procedure. To obtain an accurate and robust model, the weighted-average method is applied to optimize standard loss and adversarial loss simultaneously. In this paper, we argue that the weighted-average method does not provide the best tradeoff for the standard performance and adversarial robustness. We argue that the failure of the weighted-average method is due to the conflict between the gradients derived from standard and adversarial loss, and further demonstrate such a conflict increases with attack budget theoretically and practically. To alleviate this problem, we propose a new trade-off paradigm for adversarial training with a conflict-aware factor for the convex combination of standard and adversarial loss, named \textbf{Conflict-Aware Adversarial Training~(CA-AT)}. Comprehensive experimental results show that CA-AT consistently offers a superior trade-off between standard performance and adversarial robustness under the settings of adversarial training from scratch and parameter-efficient finetuning.
Communication-Efficient and Tensorized Federated Fine-Tuning of Large Language Models
Oct 16, 2024Parameter-efficient fine-tuning (PEFT) methods typically assume that Large Language Models (LLMs) are trained on data from a single device or client. However, real-world scenarios often require fine-tuning these models on private data distributed across multiple devices. Federated Learning (FL) offers an appealing solution by preserving user privacy, as sensitive data remains on local devices during training. Nonetheless, integrating PEFT methods into FL introduces two main challenges: communication overhead and data heterogeneity. In this paper, we introduce FedTT and FedTT+, methods for adapting LLMs by integrating tensorized adapters into client-side models' encoder/decoder blocks. FedTT is versatile and can be applied to both cross-silo FL and large-scale cross-device FL. FedTT+, an extension of FedTT tailored for cross-silo FL, enhances robustness against data heterogeneity by adaptively freezing portions of tensor factors, further reducing the number of trainable parameters. Experiments on BERT and LLaMA models demonstrate that our proposed methods successfully address data heterogeneity challenges and perform on par or even better than existing federated PEFT approaches while achieving up to 10$\times$ reduction in communication cost.
Towards Understanding Task-agnostic Debiasing Through the Lenses of Intrinsic Bias and Forgetfulness
Jun 06, 2024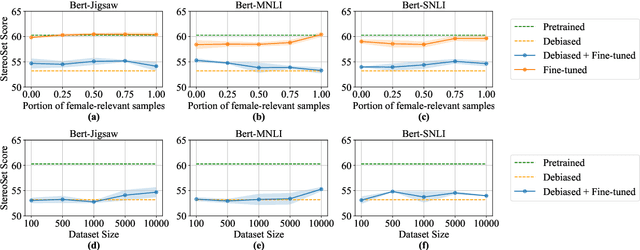
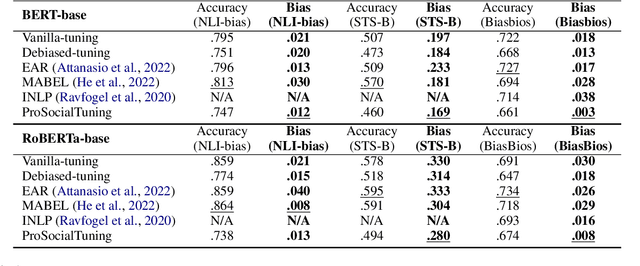
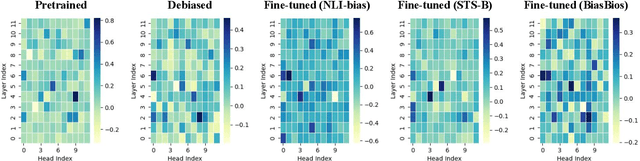

While task-agnostic debiasing provides notable generalizability and reduced reliance on downstream data, its impact on language modeling ability and the risk of relearning social biases from downstream task-specific data remain as the two most significant challenges when debiasing Pretrained Language Models (PLMs). The impact on language modeling ability can be alleviated given a high-quality and long-contextualized debiasing corpus, but there remains a deficiency in understanding the specifics of relearning biases. We empirically ascertain that the effectiveness of task-agnostic debiasing hinges on the quantitative bias level of both the task-specific data used for downstream applications and the debiased model. We empirically show that the lower bound of the bias level of the downstream fine-tuned model can be approximated by the bias level of the debiased model, in most practical cases. To gain more in-depth understanding about how the parameters of PLMs change during fine-tuning due to the forgetting issue of PLMs, we propose a novel framework which can Propagate Socially-fair Debiasing to Downstream Fine-tuning, ProSocialTuning. Our proposed framework can push the fine-tuned model to approach the bias lower bound during downstream fine-tuning, indicating that the ineffectiveness of debiasing can be alleviated by overcoming the forgetting issue through regularizing successfully debiased attention heads based on the PLMs' bias levels from stages of pretraining and debiasing.
On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Jun 04, 2024


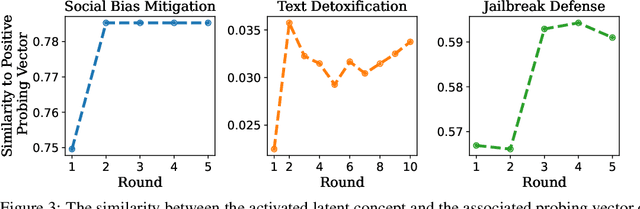
Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.