 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Diagnose and Correct Moral Errors: Towards Enhancing Moral Sensitivity in Large Language Models
Jan 06, 2026Moral sensitivity is fundamental to human moral competence, as it guides individuals in regulating everyday behavior. Although many approaches seek to align large language models (LLMs) with human moral values, how to enable them morally sensitive has been extremely challenging. In this paper, we take a step toward answering the question: how can we enhance moral sensitivity in LLMs? Specifically, we propose two pragmatic inference methods that faciliate LLMs to diagnose morally benign and hazardous input and correct moral errors, whereby enhancing LLMs' moral sensitivity. A central strength of our pragmatic inference methods is their unified perspective: instead of modeling moral discourses across semantically diverse and complex surface forms, they offer a principled perspective for designing pragmatic inference procedures grounded in their inferential loads. Empirical evidence demonstrates that our pragmatic methods can enhance moral sensitivity in LLMs and achieves strong performance on representative morality-relevant benchmarks.
On the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
Discourse Heuristics For Paradoxically Moral Self-Correction
Jul 01, 2025Moral self-correction has emerged as a promising approach for aligning the output of Large Language Models (LLMs) with human moral values. However, moral self-correction techniques are subject to two primary paradoxes. First, despite empirical and theoretical evidence to support the effectiveness of self-correction, this LLM capability only operates at a superficial level. Second, while LLMs possess the capability of self-diagnosing immoral aspects of their output, they struggle to identify the cause of this moral inconsistency during their self-correction process. To better understand and address these paradoxes, we analyze the discourse constructions in fine-tuning corpora designed to enhance moral self-correction, uncovering the existence of the heuristics underlying effective constructions. We demonstrate that moral self-correction relies on discourse constructions that reflect heuristic shortcuts, and that the presence of these heuristic shortcuts during self-correction leads to inconsistency when attempting to enhance both self-correction and self-diagnosis capabilities jointly. Based on our findings, we propose a solution to improve moral self-correction by leveraging the heuristics of curated datasets. We also highlight the generalization challenges of this capability, particularly in terms of learning from situated context and model scales.
Revealing the Pragmatic Dilemma for Moral Reasoning Acquisition in Language Models
Feb 25, 2025
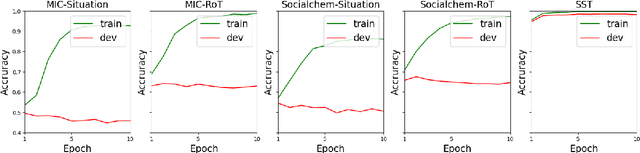

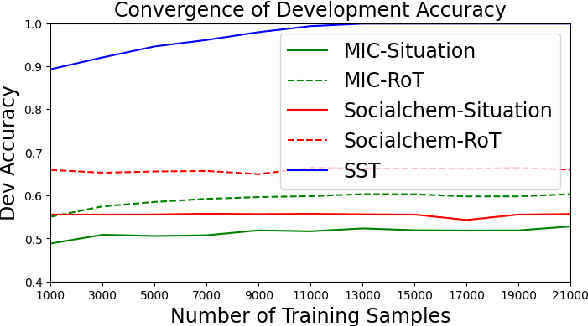
Ensuring that Large Language Models (LLMs) return just responses which adhere to societal values is crucial for their broader application. Prior research has shown that LLMs often fail to perform satisfactorily on tasks requiring moral cognizance, such as ethics-based judgments. While current approaches have focused on fine-tuning LLMs with curated datasets to improve their capabilities on such tasks, choosing the optimal learning paradigm to enhance the ethical responses of LLMs remains an open research debate. In this work, we aim to address this fundamental question: can current learning paradigms enable LLMs to acquire sufficient moral reasoning capabilities? Drawing from distributional semantics theory and the pragmatic nature of moral discourse, our analysis indicates that performance improvements follow a mechanism similar to that of semantic-level tasks, and therefore remain affected by the pragmatic nature of morals latent in discourse, a phenomenon we name the pragmatic dilemma. We conclude that this pragmatic dilemma imposes significant limitations on the generalization ability of current learning paradigms, making it the primary bottleneck for moral reasoning acquisition in LLMs.
Optimal Eye Surgeon: Finding Image Priors through Sparse Generators at Initialization
Jun 07, 2024



We introduce Optimal Eye Surgeon (OES), a framework for pruning and training deep image generator networks. Typically, untrained deep convolutional networks, which include image sampling operations, serve as effective image priors (Ulyanov et al., 2018). However, they tend to overfit to noise in image restoration tasks due to being overparameterized. OES addresses this by adaptively pruning networks at random initialization to a level of underparameterization. This process effectively captures low-frequency image components even without training, by just masking. When trained to fit noisy images, these pruned subnetworks, which we term Sparse-DIP, resist overfitting to noise. This benefit arises from underparameterization and the regularization effect of masking, constraining them in the manifold of image priors. We demonstrate that subnetworks pruned through OES surpass other leading pruning methods, such as the Lottery Ticket Hypothesis, which is known to be suboptimal for image recovery tasks (Wu et al., 2023). Our extensive experiments demonstrate the transferability of OES-masks and the characteristics of sparse-subnetworks for image generation. Code is available at https://github.com/Avra98/Optimal-Eye-Surgeon.git.
* Pruning image generator networks at initialization to alleviate overfitting
Towards Understanding Task-agnostic Debiasing Through the Lenses of Intrinsic Bias and Forgetfulness
Jun 06, 2024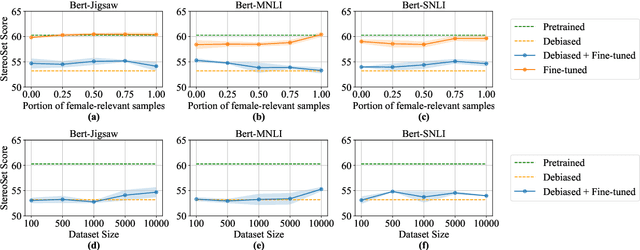
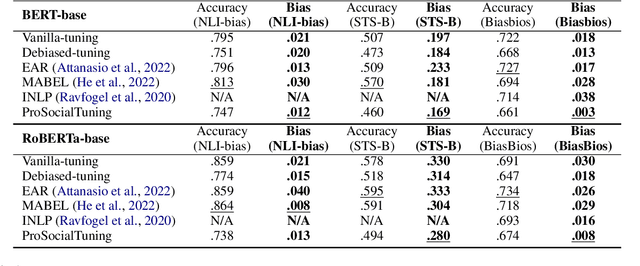
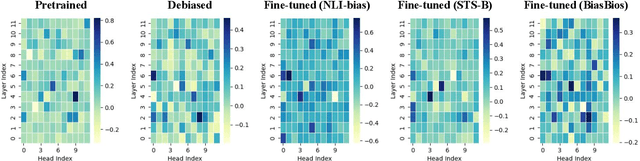

While task-agnostic debiasing provides notable generalizability and reduced reliance on downstream data, its impact on language modeling ability and the risk of relearning social biases from downstream task-specific data remain as the two most significant challenges when debiasing Pretrained Language Models (PLMs). The impact on language modeling ability can be alleviated given a high-quality and long-contextualized debiasing corpus, but there remains a deficiency in understanding the specifics of relearning biases. We empirically ascertain that the effectiveness of task-agnostic debiasing hinges on the quantitative bias level of both the task-specific data used for downstream applications and the debiased model. We empirically show that the lower bound of the bias level of the downstream fine-tuned model can be approximated by the bias level of the debiased model, in most practical cases. To gain more in-depth understanding about how the parameters of PLMs change during fine-tuning due to the forgetting issue of PLMs, we propose a novel framework which can Propagate Socially-fair Debiasing to Downstream Fine-tuning, ProSocialTuning. Our proposed framework can push the fine-tuned model to approach the bias lower bound during downstream fine-tuning, indicating that the ineffectiveness of debiasing can be alleviated by overcoming the forgetting issue through regularizing successfully debiased attention heads based on the PLMs' bias levels from stages of pretraining and debiasing.
Structure-Preserving Network Compression Via Low-Rank Induced Training Through Linear Layers Composition
May 06, 2024



Deep Neural Networks (DNNs) have achieved remarkable success in addressing many previously unsolvable tasks. However, the storage and computational requirements associated with DNNs pose a challenge for deploying these trained models on resource-limited devices. Therefore, a plethora of compression and pruning techniques have been proposed in recent years. Low-rank decomposition techniques are among the approaches most utilized to address this problem. Compared to post-training compression, compression-promoted training is still under-explored. In this paper, we present a theoretically-justified novel approach, termed Low-Rank Induced Training (LoRITa), that promotes low-rankness through the composition of linear layers and compresses by using singular value truncation. This is achieved without the need to change the structure at inference time or require constrained and/or additional optimization, other than the standard weight decay regularization. Moreover, LoRITa eliminates the need to (i) initialize with pre-trained models and (ii) specify rank selection prior to training. Our experimental results (i) demonstrate the effectiveness of our approach using MNIST on Fully Connected Networks, CIFAR10 on Vision Transformers, and CIFAR10/100 on Convolutional Neural Networks, and (ii) illustrate that we achieve either competitive or SOTA results when compared to leading structured pruning methods in terms of FLOPs and parameters drop.
PAC-tuning:Fine-tuning Pretrained Language Models with PAC-driven Perturbed Gradient Descent
Oct 26, 2023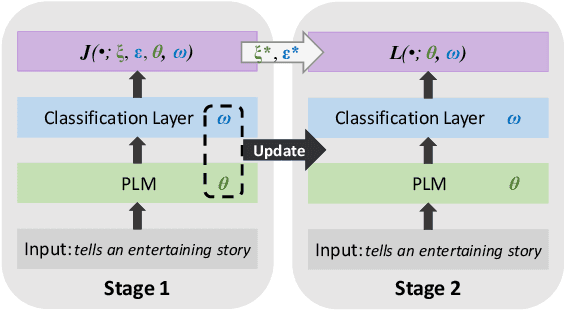
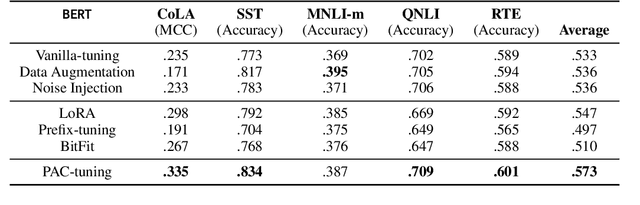

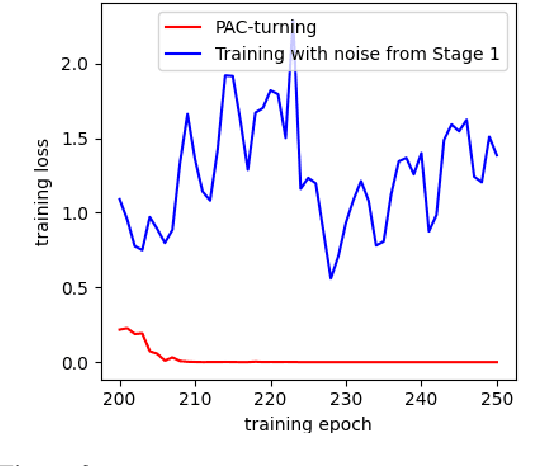
Fine-tuning pretrained language models (PLMs) for downstream tasks is a large-scale optimization problem, in which the choice of the training algorithm critically determines how well the trained model can generalize to unseen test data, especially in the context of few-shot learning. To achieve good generalization performance and avoid overfitting, techniques such as data augmentation and pruning are often applied. However, adding these regularizations necessitates heavy tuning of the hyperparameters of optimization algorithms, such as the popular Adam optimizer. In this paper, we propose a two-stage fine-tuning method, PAC-tuning, to address this optimization challenge. First, based on PAC-Bayes training, PAC-tuning directly minimizes the PAC-Bayes generalization bound to learn proper parameter distribution. Second, PAC-tuning modifies the gradient by injecting noise with the variance learned in the first stage into the model parameters during training, resulting in a variant of perturbed gradient descent (PGD). In the past, the few-shot scenario posed difficulties for PAC-Bayes training because the PAC-Bayes bound, when applied to large models with limited training data, might not be stringent. Our experimental results across 5 GLUE benchmark tasks demonstrate that PAC-tuning successfully handles the challenges of fine-tuning tasks and outperforms strong baseline methods by a visible margin, further confirming the potential to apply PAC training for any other settings where the Adam optimizer is currently used for training.
Can Directed Graph Neural Networks be Adversarially Robust?
Jun 03, 2023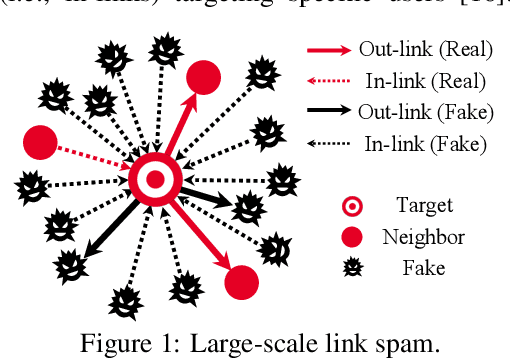
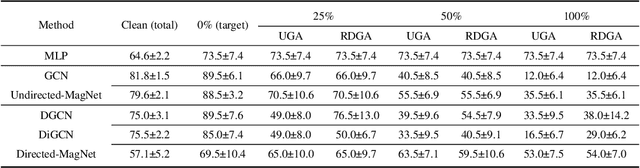
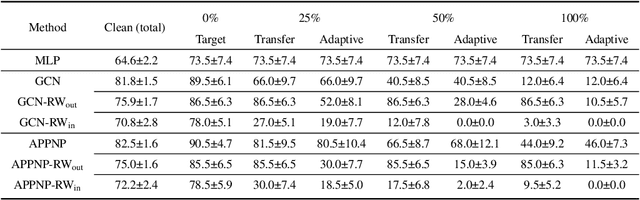
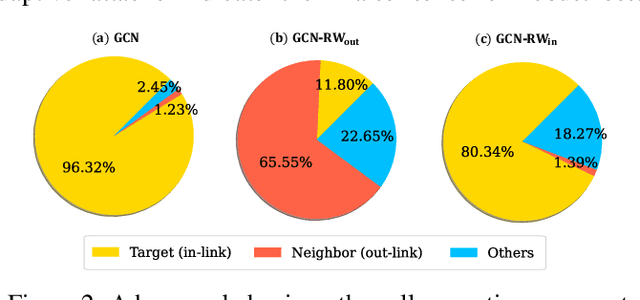
The existing research on robust Graph Neural Networks (GNNs) fails to acknowledge the significance of directed graphs in providing rich information about networks' inherent structure. This work presents the first investigation into the robustness of GNNs in the context of directed graphs, aiming to harness the profound trust implications offered by directed graphs to bolster the robustness and resilience of GNNs. Our study reveals that existing directed GNNs are not adversarially robust. In pursuit of our goal, we introduce a new and realistic directed graph attack setting and propose an innovative, universal, and efficient message-passing framework as a plug-in layer to significantly enhance the robustness of GNNs. Combined with existing defense strategies, this framework achieves outstanding clean accuracy and state-of-the-art robust performance, offering superior defense against both transfer and adaptive attacks. The findings in this study reveal a novel and promising direction for this crucial research area. The code will be made publicly available upon the acceptance of this work.
Auto-tune: PAC-Bayes Optimization over Prior and Posterior for Neural Networks
May 30, 2023



It is widely recognized that the generalization ability of neural networks can be greatly enhanced through carefully designing the training procedure. The current state-of-the-art training approach involves utilizing stochastic gradient descent (SGD) or Adam optimization algorithms along with a combination of additional regularization techniques such as weight decay, dropout, or noise injection. Optimal generalization can only be achieved by tuning a multitude of hyperparameters through grid search, which can be time-consuming and necessitates additional validation datasets. To address this issue, we introduce a practical PAC-Bayes training framework that is nearly tuning-free and requires no additional regularization while achieving comparable testing performance to that of SGD/Adam after a complete grid search and with extra regularizations. Our proposed algorithm demonstrates the remarkable potential of PAC training to achieve state-of-the-art performance on deep neural networks with enhanced robustness and interpretability.