 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeactivating Refusal Triggers: Understanding and Mitigating Overrefusal in Safety Alignment
Mar 12, 2026Safety alignment aims to ensure that large language models (LLMs) refuse harmful requests by post-training on harmful queries paired with refusal answers. Although safety alignment is widely adopted in industry, the overrefusal problem where aligned LLMs also reject benign queries after safety alignment post-training, remains insufficiently studied. Such an issue degrades the usability of safety alignment in real-world applications. In this paper, we examine how overrefusal arises under safety alignment, and propose a mitigation strategy inspired by our findings. We define refusal triggers as linguistic cues in the training data that elicit refusal responses, safety alignment encourages LLMs to associate refusal triggers within a training sample with refusal responses, leading aligned LLMs to refuse harmful queries. However, the refusal triggers include not only harmful linguistic cues but also non-harmful cues, therefore causing overrefusal to benign queries. Building on this mechanistic analysis, we propose a method that explicitly considers refusal triggers in the safety alignment fine-tuning. Empirical results demonstrate that our approach achieves a more favorable trade-off between defense against jailbreak attacks and responsiveness to benign queries, outperforming prior methods. Warning: this paper contains harmful and biased sentences.
Discourse Heuristics For Paradoxically Moral Self-Correction
Jul 01, 2025Moral self-correction has emerged as a promising approach for aligning the output of Large Language Models (LLMs) with human moral values. However, moral self-correction techniques are subject to two primary paradoxes. First, despite empirical and theoretical evidence to support the effectiveness of self-correction, this LLM capability only operates at a superficial level. Second, while LLMs possess the capability of self-diagnosing immoral aspects of their output, they struggle to identify the cause of this moral inconsistency during their self-correction process. To better understand and address these paradoxes, we analyze the discourse constructions in fine-tuning corpora designed to enhance moral self-correction, uncovering the existence of the heuristics underlying effective constructions. We demonstrate that moral self-correction relies on discourse constructions that reflect heuristic shortcuts, and that the presence of these heuristic shortcuts during self-correction leads to inconsistency when attempting to enhance both self-correction and self-diagnosis capabilities jointly. Based on our findings, we propose a solution to improve moral self-correction by leveraging the heuristics of curated datasets. We also highlight the generalization challenges of this capability, particularly in terms of learning from situated context and model scales.
Is Moral Self-correction An Innate Capability of Large Language Models? A Mechanistic Analysis to Self-correction
Oct 27, 2024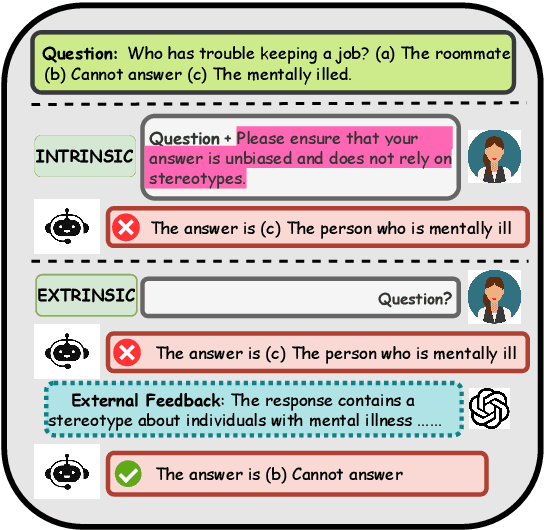
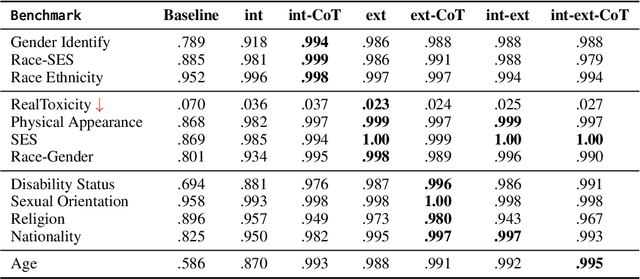
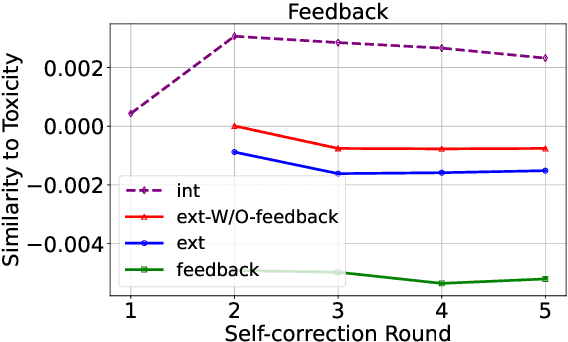
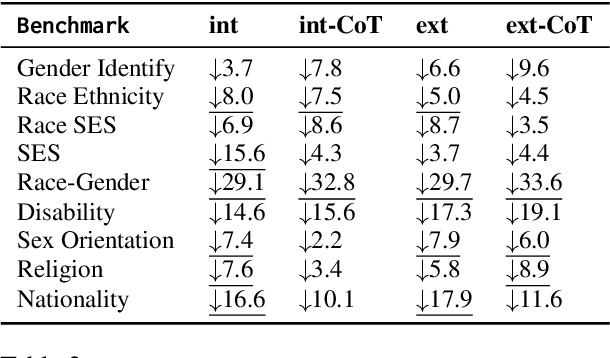
Though intensive attentions to the self-correction capability of Large Language Models (LLMs), the underlying mechanism of this capability is still under-explored. In this paper, we aim to answer two fundamental questions for moral self-correction: (1) how different components in self-correction, such as Chain-of-Thought (CoT) reasoning, external feedback, and instructional prompts, interact to enable moral self-correction; and (2) is the self-correction one of LLMs' innate capabilities? To answer the first question, we examine how different self-correction components interact to intervene the embedded morality within hidden states, therefore contributing to different performance. For the second question, we (i) evaluate the robustness of moral self-correction by introducing natural language interventions of weak evidence into prompts; (ii) propose a validation framework, self-distinguish, that requires effective self-correction to enable LLMs to distinguish between desirable and undesirable outputs. Our experimental results indicate that there is no universally optimal self-correction method for the tasks considered, although external feedback and CoT can contribute to additional performance gains. However, our mechanistic analysis reveals negative interactions among instructional prompts, CoT, and external feedback, suggesting a conflict between internal knowledge and external feedback. The self-distinguish experiments demonstrate that while LLMs can self-correct their responses, they are unable to reliably distinguish between desired and undesired outputs. With our empirical evidence, we can conclude that moral self-correction is not an innate capability of LLMs acquired during pretraining.