 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
Discourse Heuristics For Paradoxically Moral Self-Correction
Jul 01, 2025Moral self-correction has emerged as a promising approach for aligning the output of Large Language Models (LLMs) with human moral values. However, moral self-correction techniques are subject to two primary paradoxes. First, despite empirical and theoretical evidence to support the effectiveness of self-correction, this LLM capability only operates at a superficial level. Second, while LLMs possess the capability of self-diagnosing immoral aspects of their output, they struggle to identify the cause of this moral inconsistency during their self-correction process. To better understand and address these paradoxes, we analyze the discourse constructions in fine-tuning corpora designed to enhance moral self-correction, uncovering the existence of the heuristics underlying effective constructions. We demonstrate that moral self-correction relies on discourse constructions that reflect heuristic shortcuts, and that the presence of these heuristic shortcuts during self-correction leads to inconsistency when attempting to enhance both self-correction and self-diagnosis capabilities jointly. Based on our findings, we propose a solution to improve moral self-correction by leveraging the heuristics of curated datasets. We also highlight the generalization challenges of this capability, particularly in terms of learning from situated context and model scales.
Revealing the Pragmatic Dilemma for Moral Reasoning Acquisition in Language Models
Feb 25, 2025
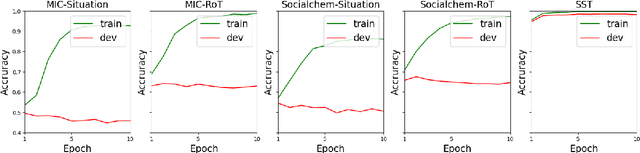

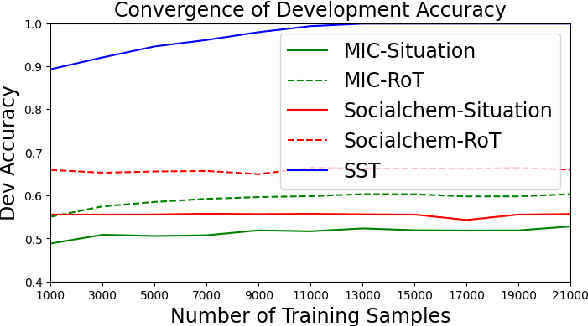
Ensuring that Large Language Models (LLMs) return just responses which adhere to societal values is crucial for their broader application. Prior research has shown that LLMs often fail to perform satisfactorily on tasks requiring moral cognizance, such as ethics-based judgments. While current approaches have focused on fine-tuning LLMs with curated datasets to improve their capabilities on such tasks, choosing the optimal learning paradigm to enhance the ethical responses of LLMs remains an open research debate. In this work, we aim to address this fundamental question: can current learning paradigms enable LLMs to acquire sufficient moral reasoning capabilities? Drawing from distributional semantics theory and the pragmatic nature of moral discourse, our analysis indicates that performance improvements follow a mechanism similar to that of semantic-level tasks, and therefore remain affected by the pragmatic nature of morals latent in discourse, a phenomenon we name the pragmatic dilemma. We conclude that this pragmatic dilemma imposes significant limitations on the generalization ability of current learning paradigms, making it the primary bottleneck for moral reasoning acquisition in LLMs.
No Free Lunch for Defending Against Prefilling Attack by In-Context Learning
Dec 13, 2024The security of Large Language Models (LLMs) has become an important research topic since the emergence of ChatGPT. Though there have been various effective methods to defend against jailbreak attacks, prefilling attacks remain an unsolved and popular threat against open-sourced LLMs. In-Context Learning (ICL) offers a computationally efficient defense against various jailbreak attacks, yet no effective ICL methods have been developed to counter prefilling attacks. In this paper, we: (1) show that ICL can effectively defend against prefilling jailbreak attacks by employing adversative sentence structures within demonstrations; (2) characterize the effectiveness of this defense through the lens of model size, number of demonstrations, over-defense, integration with other jailbreak attacks, and the presence of safety alignment. Given the experimental results and our analysis, we conclude that there is no free lunch for defending against prefilling jailbreak attacks with ICL. On the one hand, current safety alignment methods fail to mitigate prefilling jailbreak attacks, but adversative structures within ICL demonstrations provide robust defense across various model sizes and complex jailbreak attacks. On the other hand, LLMs exhibit similar over-defensiveness when utilizing ICL demonstrations with adversative structures, and this behavior appears to be independent of model size.
Smaller Large Language Models Can Do Moral Self-Correction
Oct 30, 2024
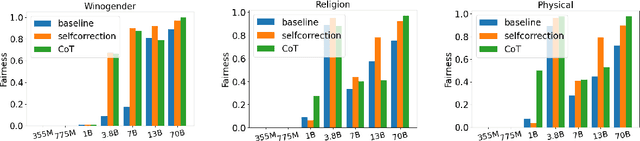
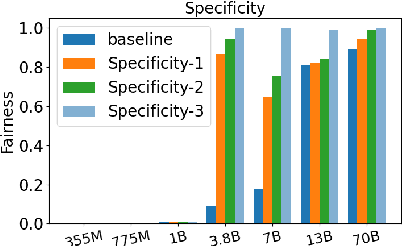
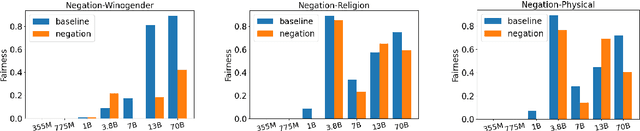
Self-correction is one of the most amazing emerging capabilities of Large Language Models (LLMs), enabling LLMs to self-modify an inappropriate output given a natural language feedback which describes the problems of that output. Moral self-correction is a post-hoc approach correcting unethical generations without requiring a gradient update, making it both computationally lightweight and capable of preserving the language modeling ability. Previous works have shown that LLMs can self-debias, and it has been reported that small models, i.e., those with less than 22B parameters, are not capable of moral self-correction. However, there is no direct proof as to why such smaller models fall short of moral self-correction, though previous research hypothesizes that larger models are skilled in following instructions and understanding abstract social norms. In this paper, we empirically validate this hypothesis in the context of social stereotyping, through meticulous prompting. Our experimental results indicate that (i) surprisingly, 3.8B LLMs with proper safety alignment fine-tuning can achieve very good moral self-correction performance, highlighting the significant effects of safety alignment; and (ii) small LLMs are indeed weaker than larger-scale models in terms of comprehending social norms and self-explanation through CoT, but all scales of LLMs show bad self-correction performance given unethical instructions.
Is Moral Self-correction An Innate Capability of Large Language Models? A Mechanistic Analysis to Self-correction
Oct 27, 2024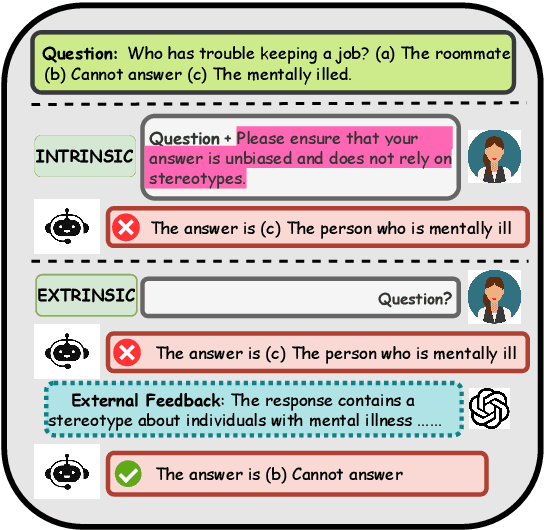
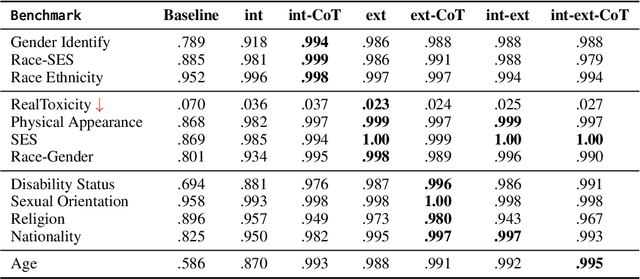
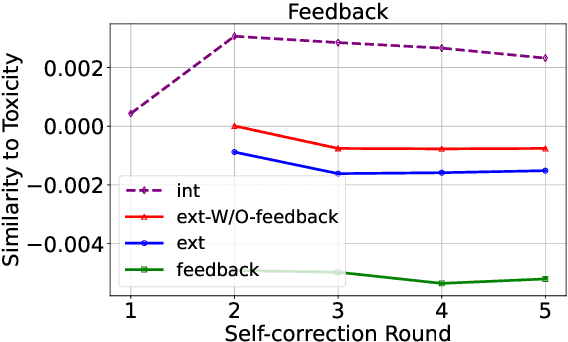
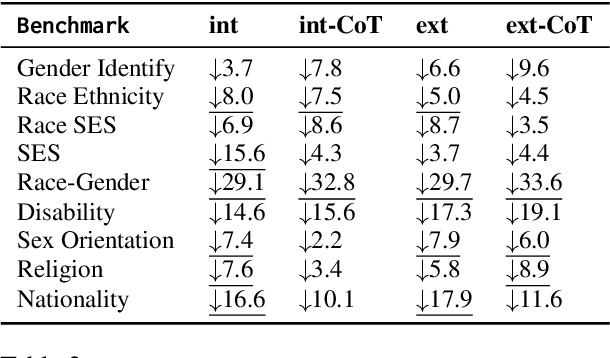
Though intensive attentions to the self-correction capability of Large Language Models (LLMs), the underlying mechanism of this capability is still under-explored. In this paper, we aim to answer two fundamental questions for moral self-correction: (1) how different components in self-correction, such as Chain-of-Thought (CoT) reasoning, external feedback, and instructional prompts, interact to enable moral self-correction; and (2) is the self-correction one of LLMs' innate capabilities? To answer the first question, we examine how different self-correction components interact to intervene the embedded morality within hidden states, therefore contributing to different performance. For the second question, we (i) evaluate the robustness of moral self-correction by introducing natural language interventions of weak evidence into prompts; (ii) propose a validation framework, self-distinguish, that requires effective self-correction to enable LLMs to distinguish between desirable and undesirable outputs. Our experimental results indicate that there is no universally optimal self-correction method for the tasks considered, although external feedback and CoT can contribute to additional performance gains. However, our mechanistic analysis reveals negative interactions among instructional prompts, CoT, and external feedback, suggesting a conflict between internal knowledge and external feedback. The self-distinguish experiments demonstrate that while LLMs can self-correct their responses, they are unable to reliably distinguish between desired and undesired outputs. With our empirical evidence, we can conclude that moral self-correction is not an innate capability of LLMs acquired during pretraining.
Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis
Jul 21, 2024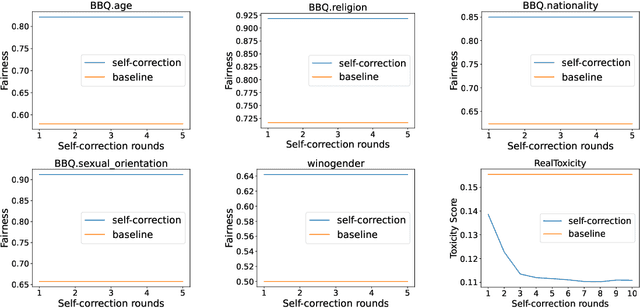

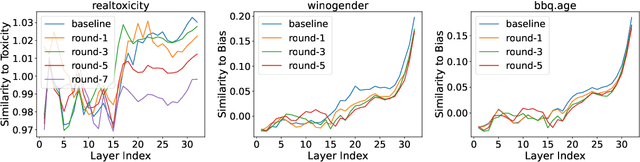

Large Language Models (LLMs) are capable of producing content that perpetuates stereotypes, discrimination, and toxicity. The recently proposed moral self-correction is a computationally efficient method for reducing harmful content in the responses of LLMs. However, the process of how injecting self-correction instructions can modify the behavior of LLMs remains under-explored. In this paper, we explore the effectiveness of moral self-correction by answering three research questions: (1) In what scenarios does moral self-correction work? (2) What are the internal mechanisms of LLMs, e.g., hidden states, that are influenced by moral self-correction instructions? (3) Is intrinsic moral self-correction actually superficial? We argue that self-correction can help LLMs find a shortcut to more morally correct output, rather than truly reducing the immorality stored in hidden states. Through empirical investigation with tasks of language generation and multi-choice question answering, we conclude: (i) LLMs exhibit good performance across both tasks, and self-correction instructions are particularly beneficial when the correct answer is already top-ranked; (ii) The morality levels in intermediate hidden states are strong indicators as to whether one instruction would be more effective than another; (iii) Based on our analysis of intermediate hidden states and task case studies of self-correction behaviors, we are first to propose the hypothesis that intrinsic moral self-correction is in fact superficial.
PAC-tuning:Fine-tuning Pretrained Language Models with PAC-driven Perturbed Gradient Descent
Oct 26, 2023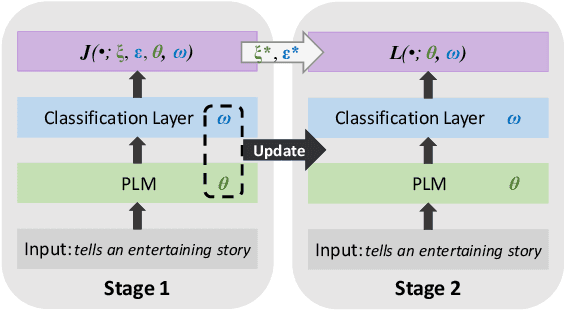
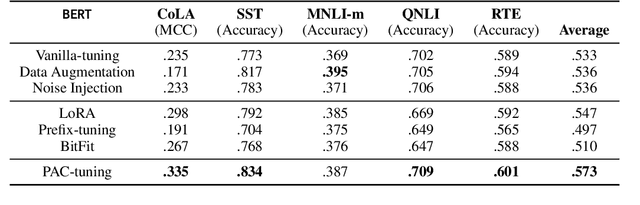

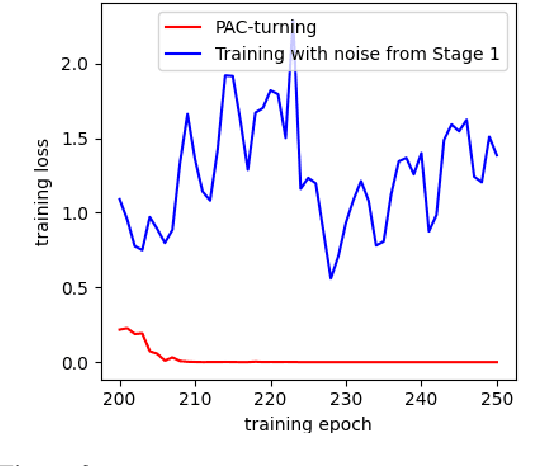
Fine-tuning pretrained language models (PLMs) for downstream tasks is a large-scale optimization problem, in which the choice of the training algorithm critically determines how well the trained model can generalize to unseen test data, especially in the context of few-shot learning. To achieve good generalization performance and avoid overfitting, techniques such as data augmentation and pruning are often applied. However, adding these regularizations necessitates heavy tuning of the hyperparameters of optimization algorithms, such as the popular Adam optimizer. In this paper, we propose a two-stage fine-tuning method, PAC-tuning, to address this optimization challenge. First, based on PAC-Bayes training, PAC-tuning directly minimizes the PAC-Bayes generalization bound to learn proper parameter distribution. Second, PAC-tuning modifies the gradient by injecting noise with the variance learned in the first stage into the model parameters during training, resulting in a variant of perturbed gradient descent (PGD). In the past, the few-shot scenario posed difficulties for PAC-Bayes training because the PAC-Bayes bound, when applied to large models with limited training data, might not be stringent. Our experimental results across 5 GLUE benchmark tasks demonstrate that PAC-tuning successfully handles the challenges of fine-tuning tasks and outperforms strong baseline methods by a visible margin, further confirming the potential to apply PAC training for any other settings where the Adam optimizer is currently used for training.